1. 伊利AI中台
1.1. 平台介绍
伊利AI平台是一个集开发、能力开放、运营于一体的AI综合性服务平台。平台提供从数据开发、模型训练到服务部署的一站式敏捷开发支撑,帮助租户快速创建和部署模型,管理全周期AI工作流。平台建立了AI能力使用流程,通过建立AI能力加入、展示和使用机制,实现了AI能力的快速使用、分享。
AI开发的各个环节,包括数据处理、算法开发、模型训练、模型部署都可以在伊利AI平台上完成。从技术上看,伊利AI平台底层支持各种异构计算资源,开发者可以根据需要灵活选择使用,而不需要关心底层的技术。同时,伊利AI平台支持Tensorflow、Pytorch等主流开源的AI开发框架,也支持开发者使用自研的算法框架,匹配租户的使用习惯。
伊利AI平台的理念就是让AI开发变得更简单、更便捷,AI使用变得更规范、高效。
1.1.1. AI开发总体流程介绍
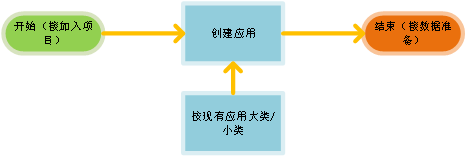
AI开发总体流程包括平台用户创建或加入项目、创建应用、数据准备、模型开发、服务部署五个步骤。
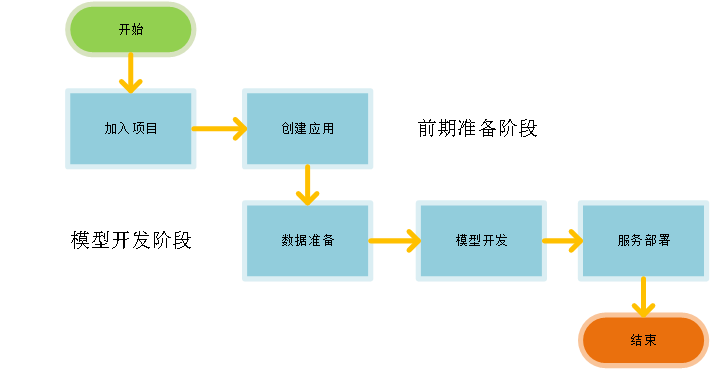
创建项目:申请AI开发的资源,创建项目后,可以添加成员,共享当前项目资源,协同AI开发;
创建应用:作为AI开发的流程,你需要创建一个应用,才可以进行AI开发;
数据开发:数据开发主要是指数据接入和数据处理的过程,数据是AI开发的基础;
模型训练:即建模,通过算法等分析手段对准备好的数据进行探索分析,并且得到模型,模型可以应用到新的数据中,得到推理结果;
推理服务部署:在训练得到模型后,需要将其应用到正式的实际数据或新产生数据中,进行推理预测,将预测结果提供给使用方,实现AI服务的投产使用。
1.2. 平台操作指南
1.2.1. 登录
伊利AI平台可通过"本地用户"登录:
登录后的用户点击导航栏右上角用户头像可以进行自身信息变更,包括"修改密码"、"绑定Git"(不进行Git绑定将无法进行编码式建模)、"退出登录":

1.2.2. 加入项目
用户可以加入项目或创建项目进入AI开发。
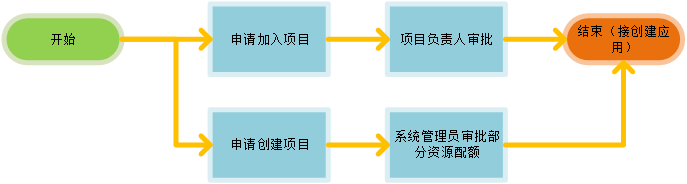
若是第一次登录,进入后会提示加入项目。
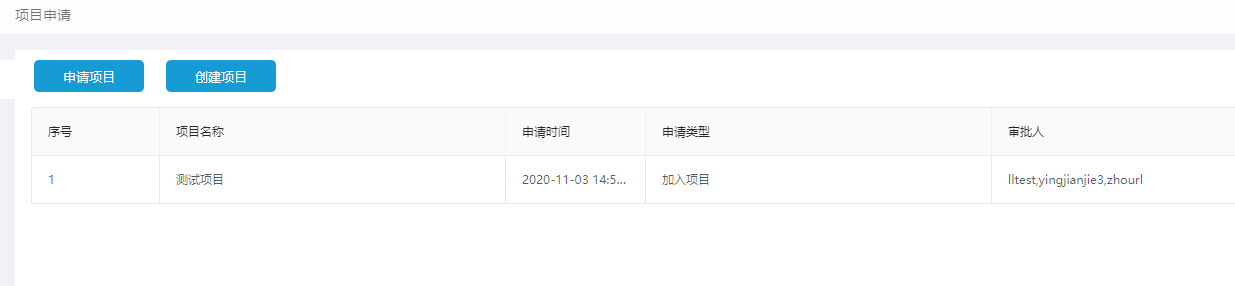
用户点击导航栏项目下拉框中的"新增项目申请",在【项目申请】中,可以点击"申请项目"申请加入一个已有项目,或点击"创建项目"创建一个新的项目:
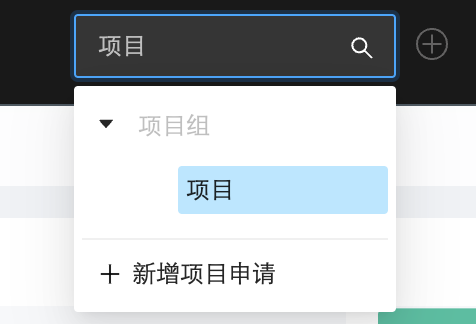
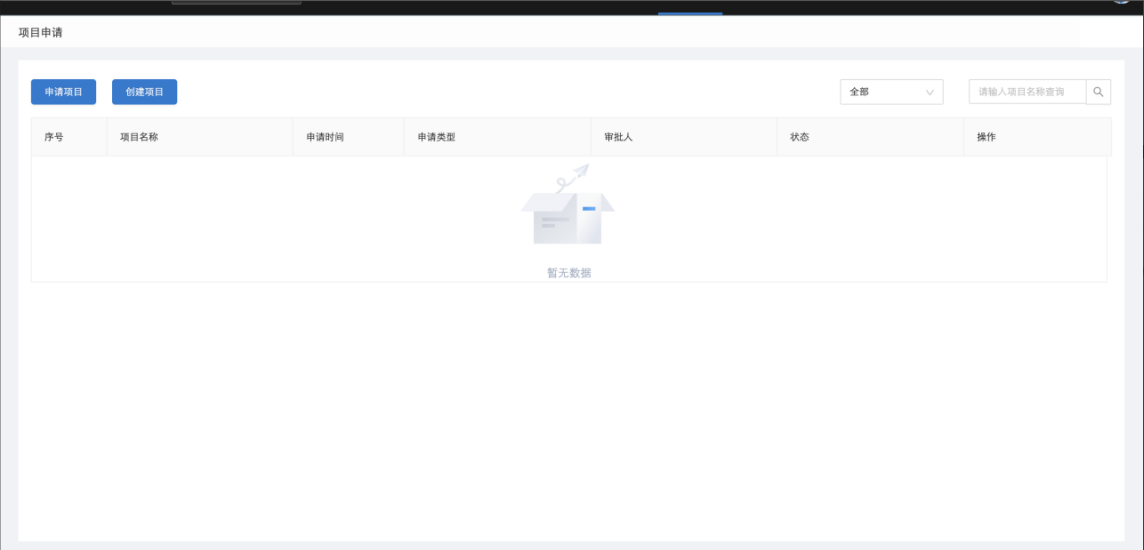
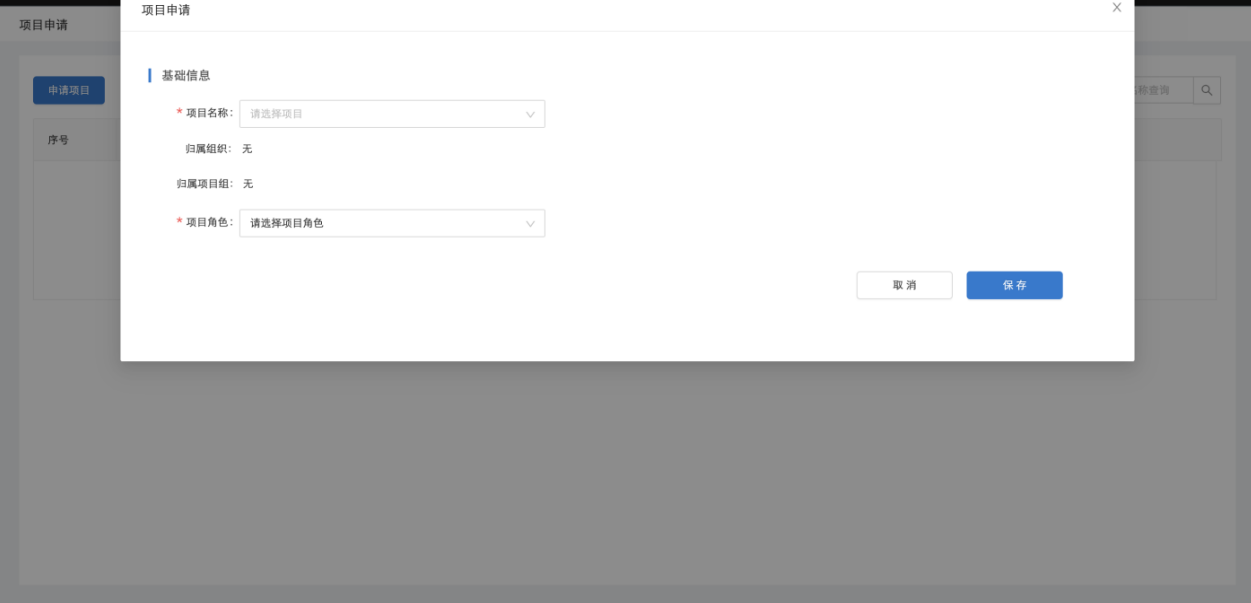
申请加入已有项目时需填写已有项目及角色,申请后会产生一条项目加入申请记录,需等待被申请项目的项目负责人在项目的【申请审批】中进行审批,可同时申请加入多个项目:
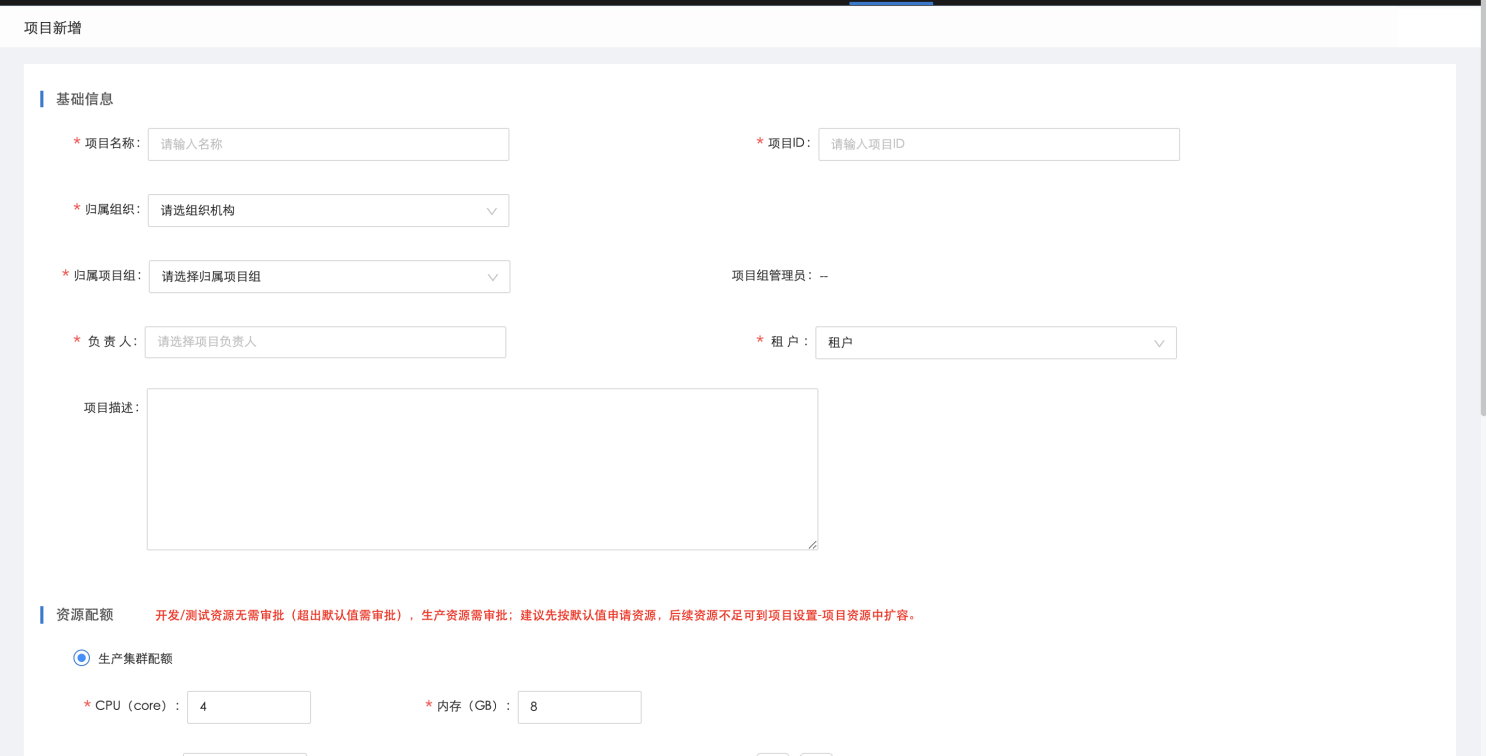
创建一个新的项目时需填写项目基础信息和资源情况,其中开发和测试环境默认的资源无需审批,开发和测试环境超出默认的资源以及生产环境的资源需租户管理员在【项目资源审批】中进行审批:
加入项目后,项目下拉框中选择已加入的项目,点击"AI开发",可通过【项目概述】查看项目的基本信息:

1.2.3. 创建应用
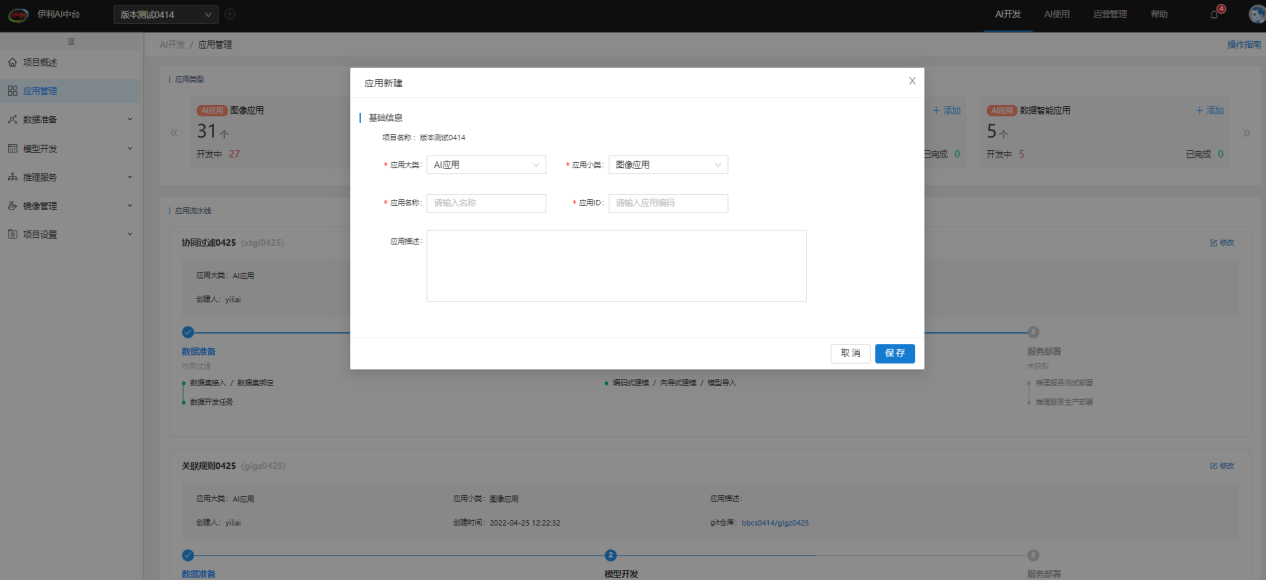
用户(项目负责人)按照系统规定的应用类型进行创建应用。
加入项目后,用户可在【应用管理】中,点击"添加",按照应用分类创建应用:
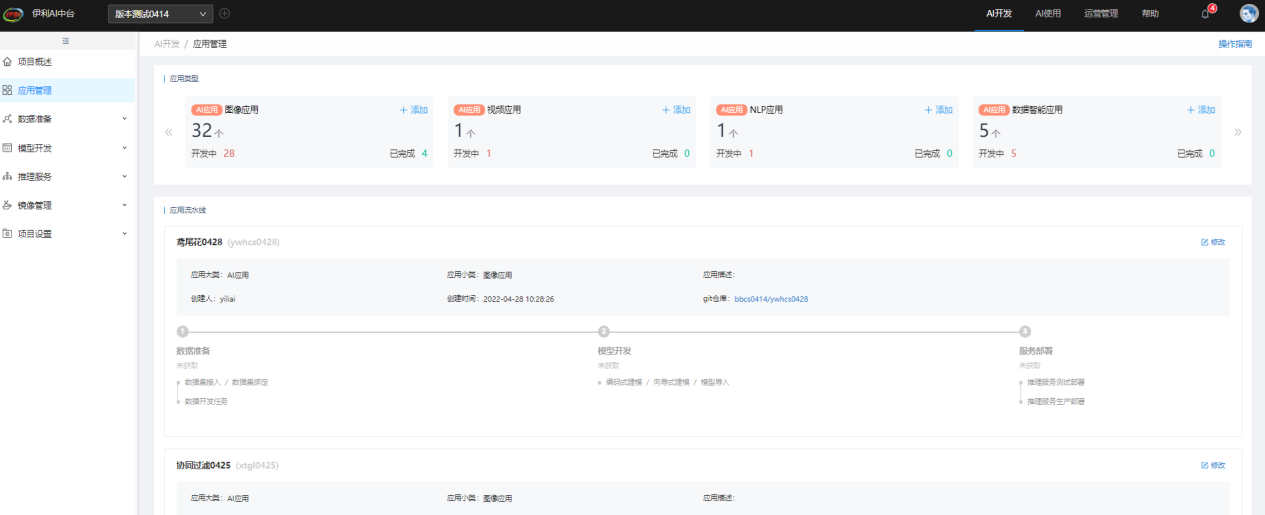
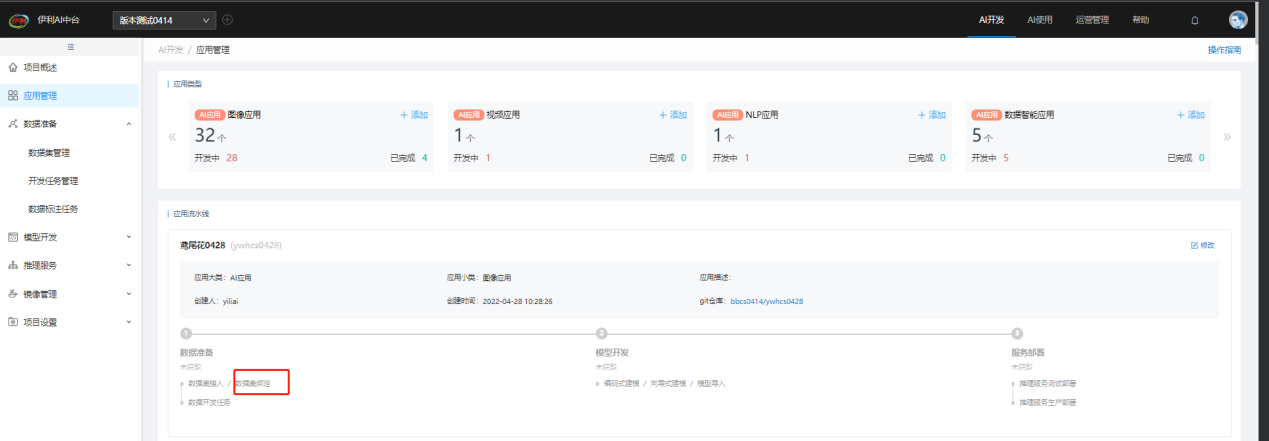
AI开发过程中,数据准备、模型开发、模型部署是通过应用关联起来的。应用开发过程中,会根据当前应用开发进度进行节点更新,同时点击应用节点也可以快速跳转到节点对应功能模块:
1.2.4. 接入数据集
用户可从结构化数据、非结构化数据进行数据准备,其中针对不满足训练条件的数据还可以进行二次的数据开发和标注。
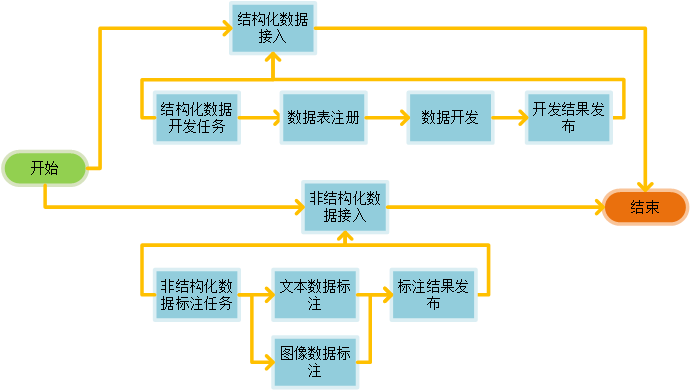
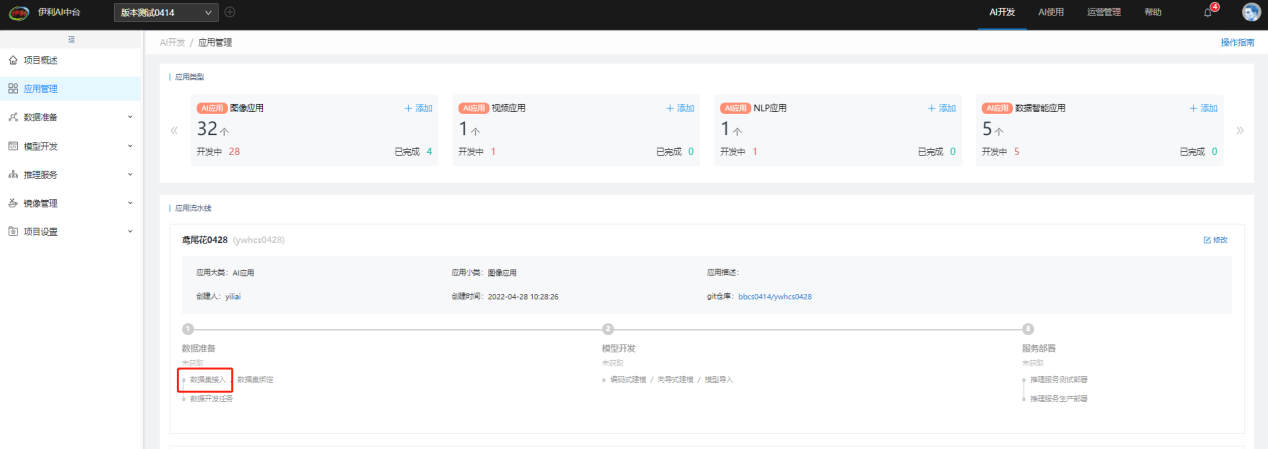
创建应用后,用户可在【应用管理】中,点击应用"数据准备"节点的"数据集接入"创建结构化或非结构化数据集,创建后的数据集将自动与该应用绑定,绑定后的数据集可供之后该应用的模型开发使用:
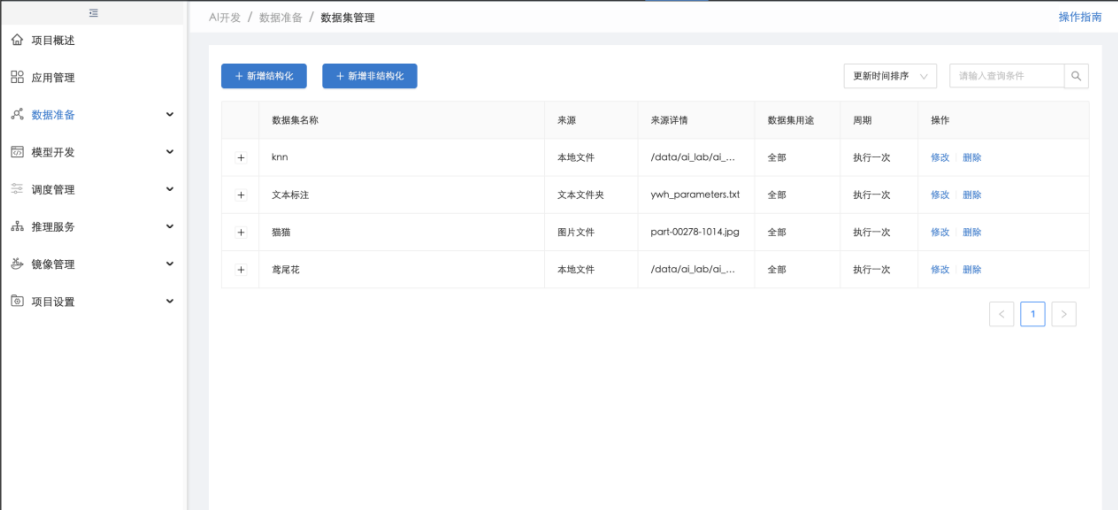
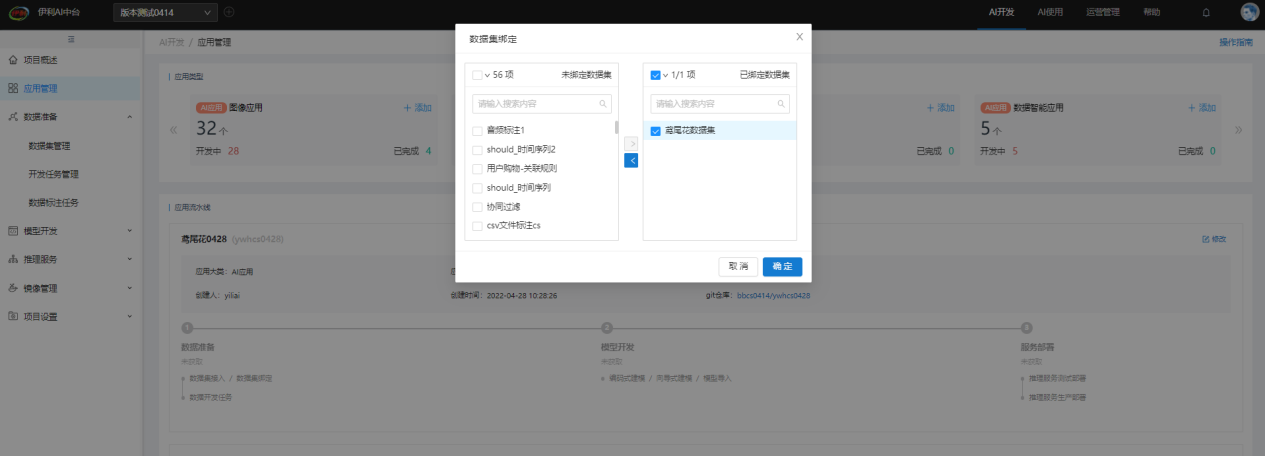
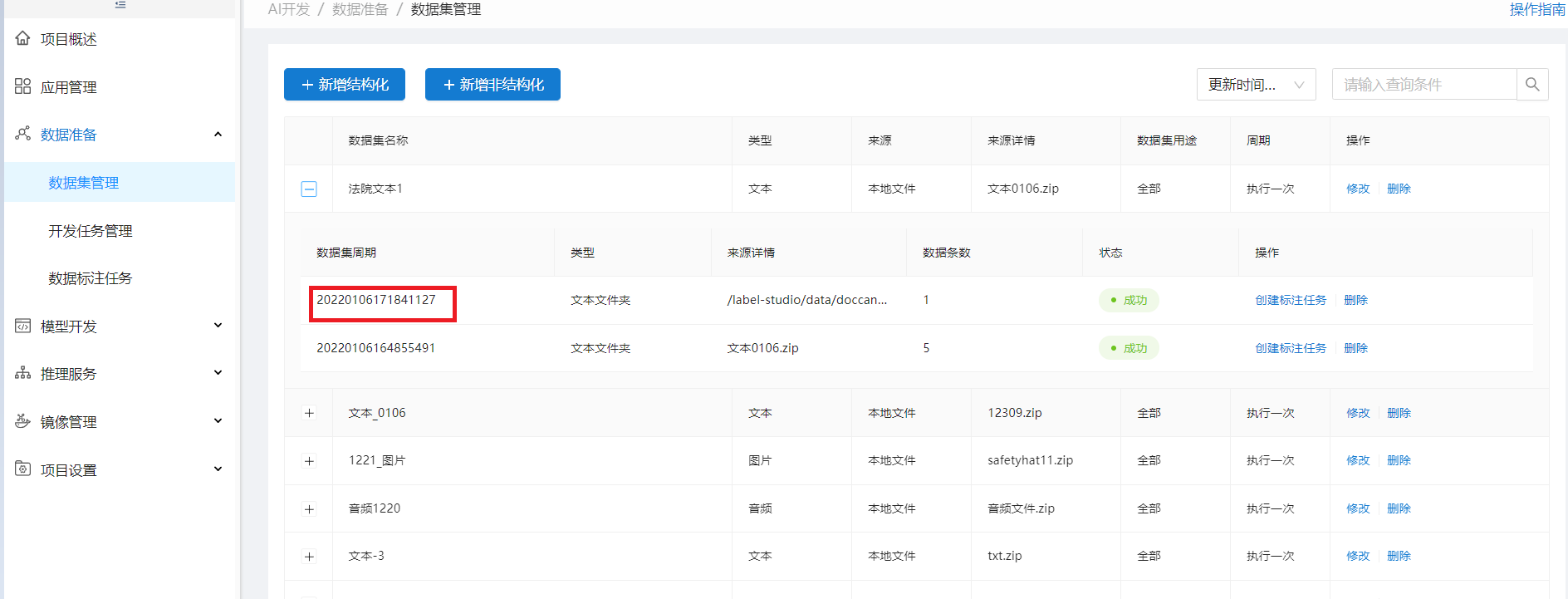
用户也可在【数据集管理】中点击"新增结构化"或"新增非结构化"直接进行结构化或非结构化数据集的创建,此时创建数据集后,需在【应用管理】中手动将创建的数据集绑定到该应用上,以供之后该应用的模型开发使用:
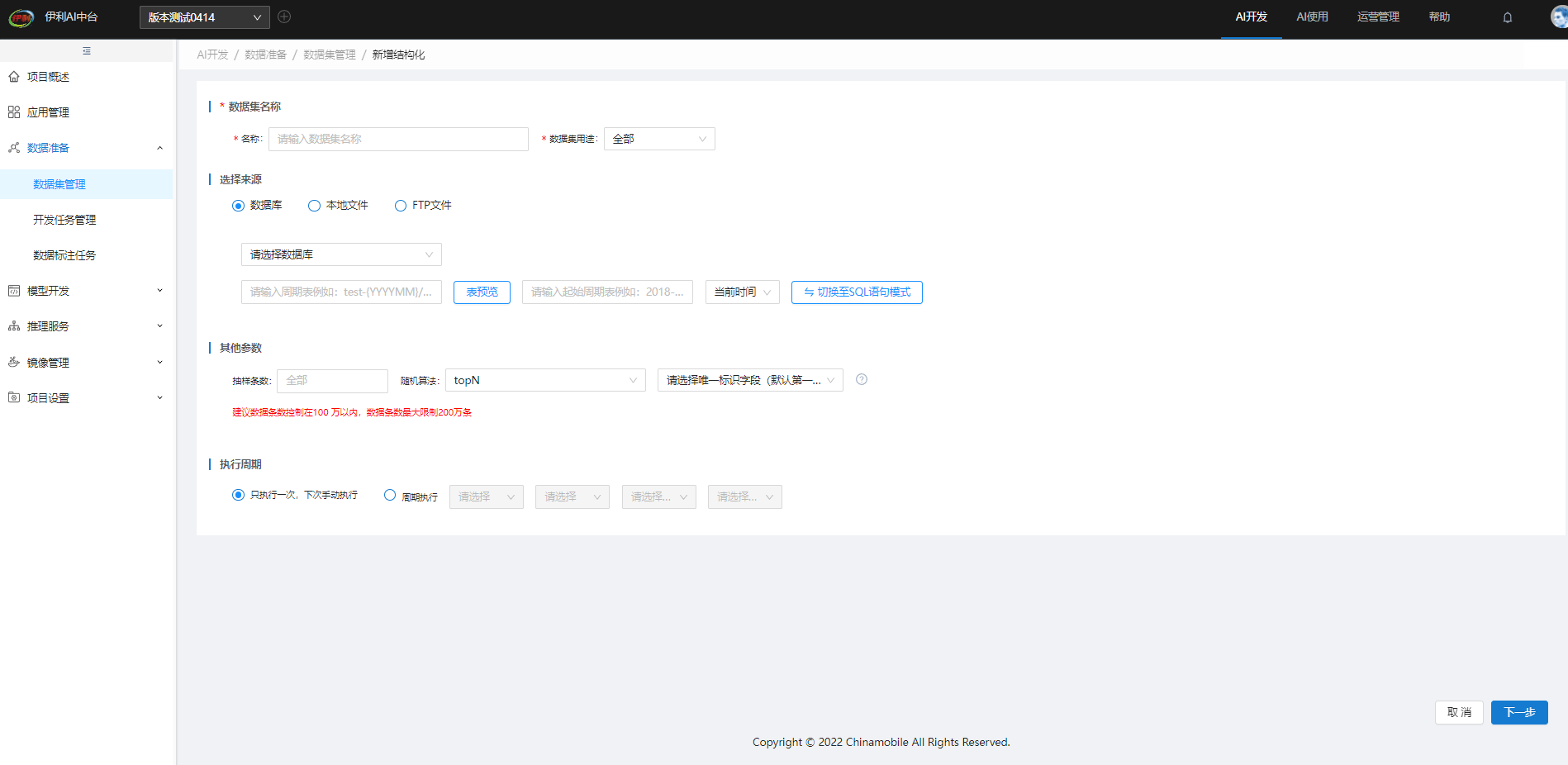
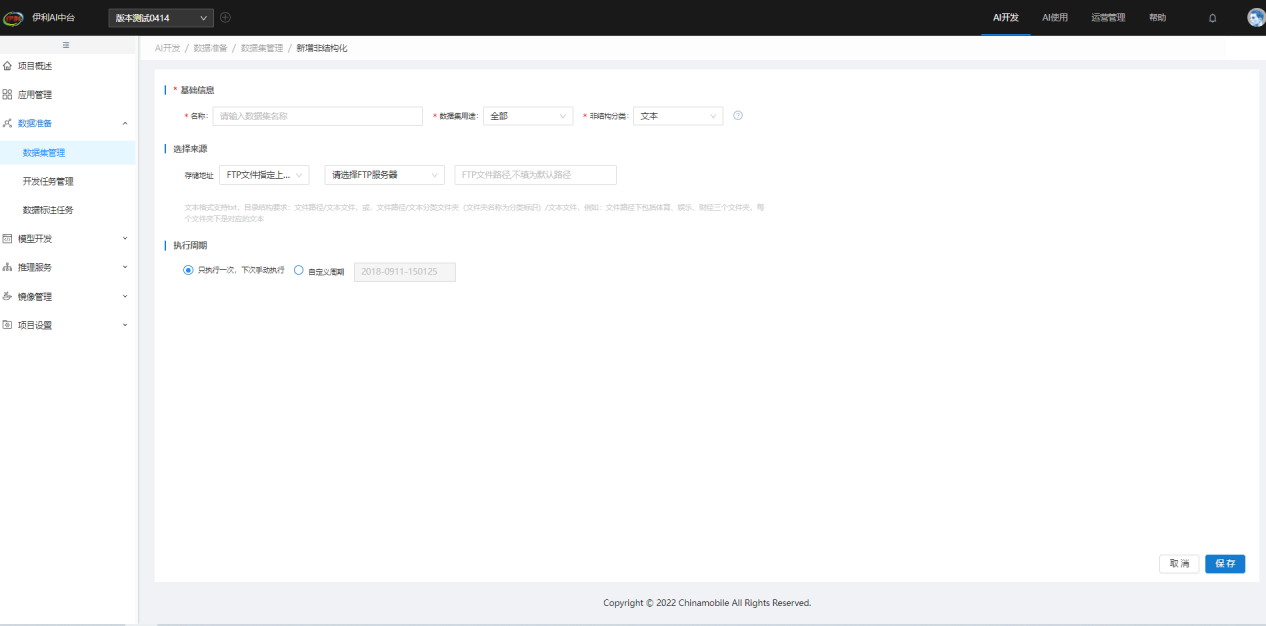
创建数据集时,除了本地上传数据,结构化数据还可以选择通过数据库或FTP上传,非结构化可通过FTP上传,若使用数据库或FTP上传时,需先在【数据源管理】中添加相应数据源连接:
数据集创建成功后,系统会自动抽取数据生成数据集的数据周期,可展开数据集进行数据周期查看:
1.2.5. 开发结构化数据
创建数据开发(如需使用数据开发模块需使用火狐或Chrome77版本浏览器)
点击项目设置,选择数据库。点击新增数据库
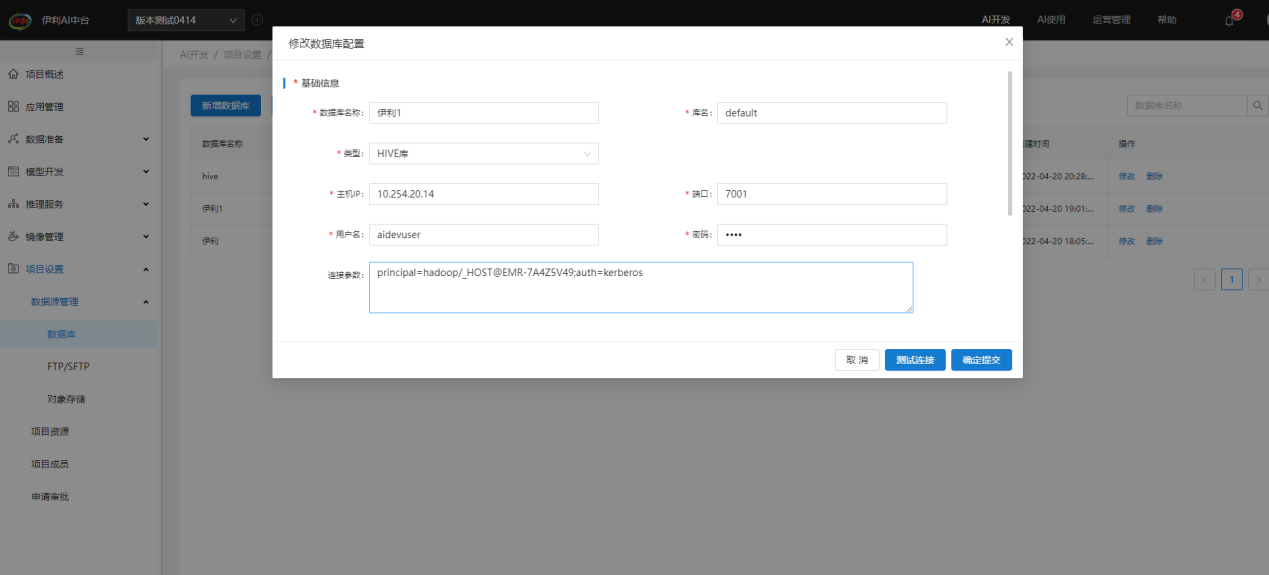
填写数据库配置信息,测试链接成功即可
进入数据集管理----点击新增结构化数据集--选择来源选择数据库----找到配置连接成功的数据库----点击表预览----填写要抽取的表名----点击下一步
默认使用字段,页面会显示该表的字段和值,点击保存。
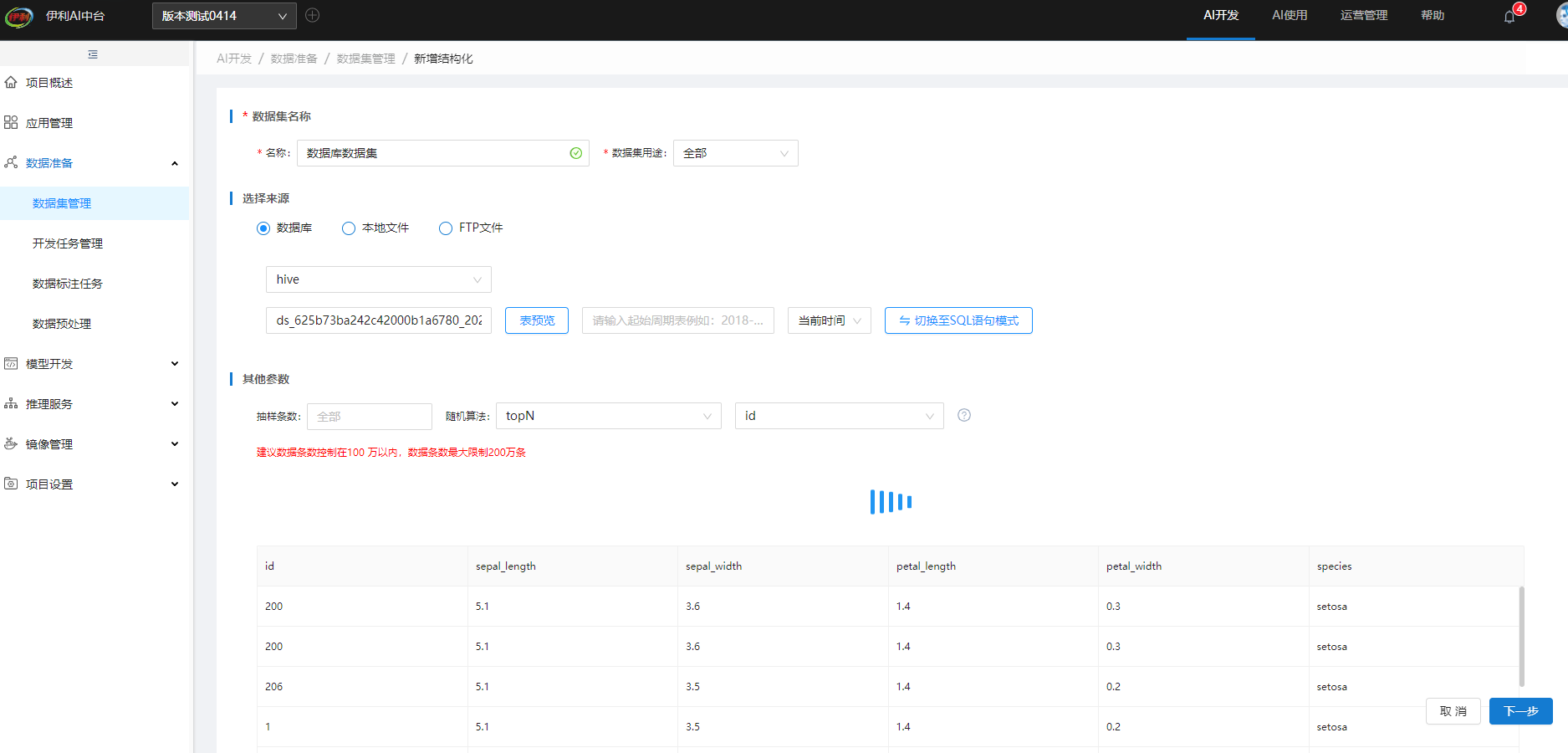
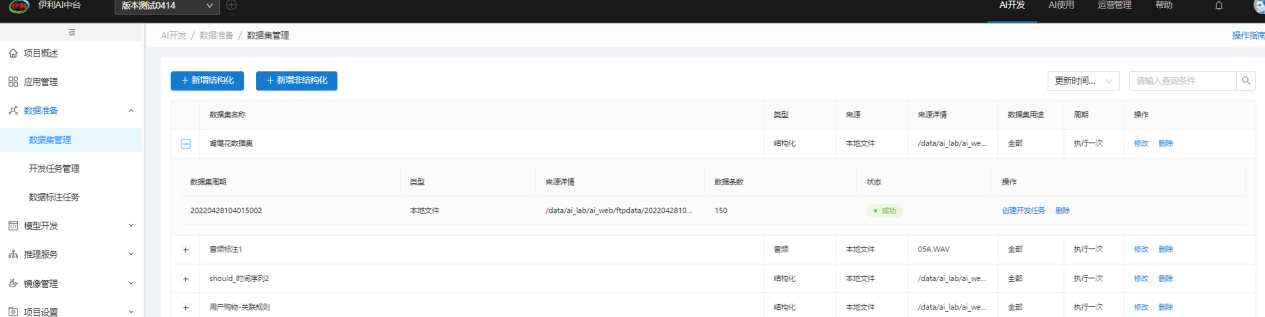
保存成功后的数据集可以在数据集管理中查看,点击数据集前方的加号,可以看到该数据集抽取的条数和状态。
创建成功的数据集可以点击右边创建开发任务,或者点击开发任务管理中选择新增开发任务
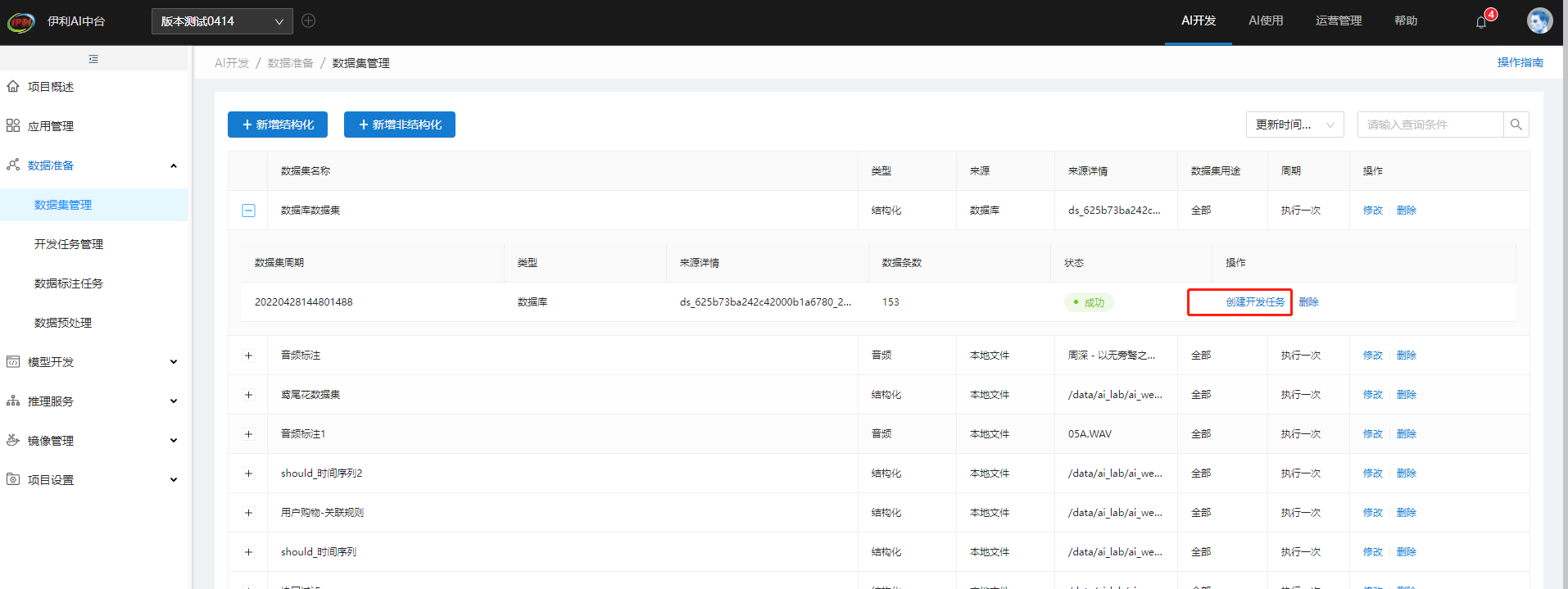
新增任务名称,选择创建成功的数据集和对应的数据集周期,点击确定提交。
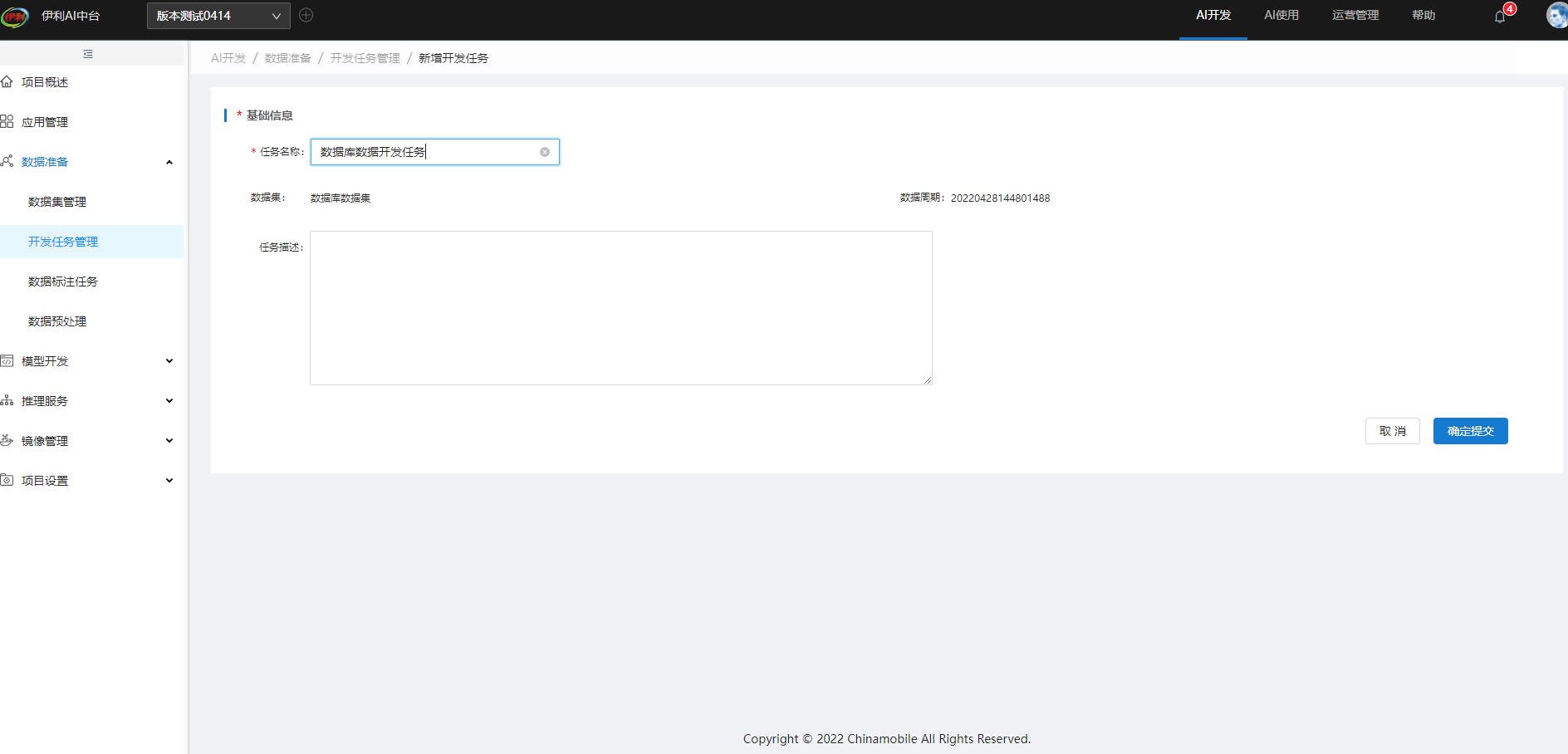
提交成功的开发任务,任务状态为可开发

点击注册界面进入模型管理界面
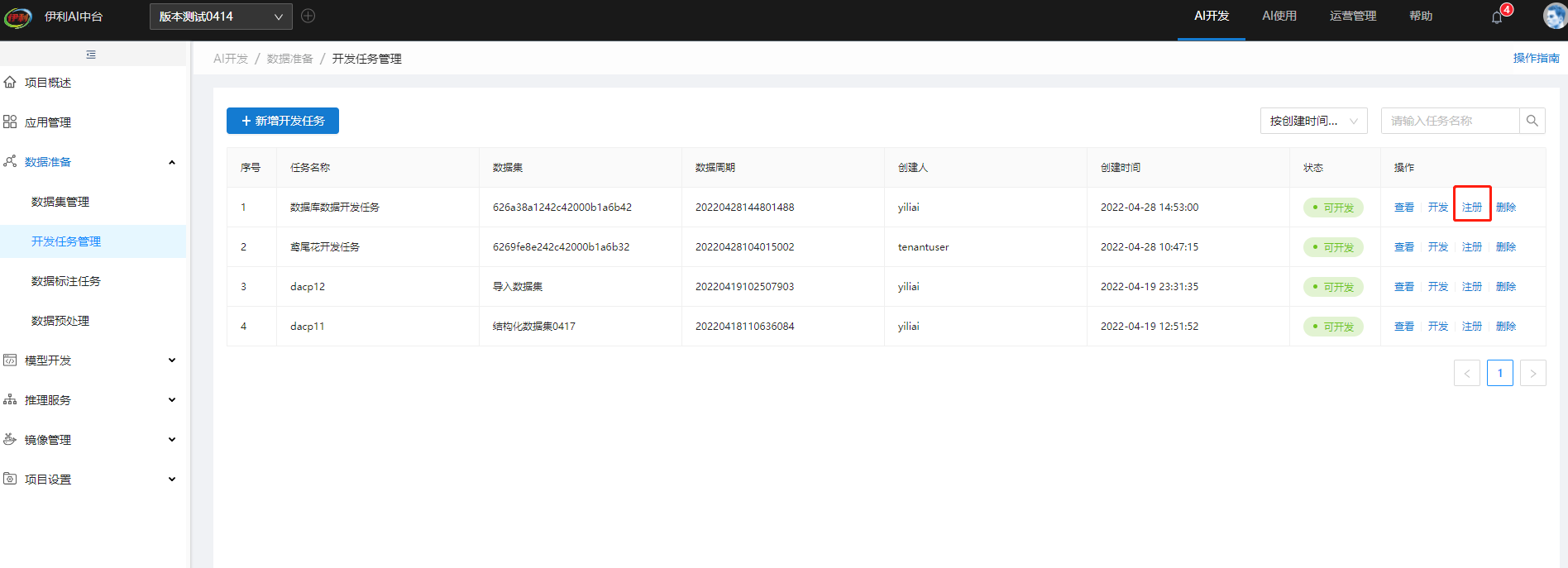
点击左侧AI开发,点击新建模型
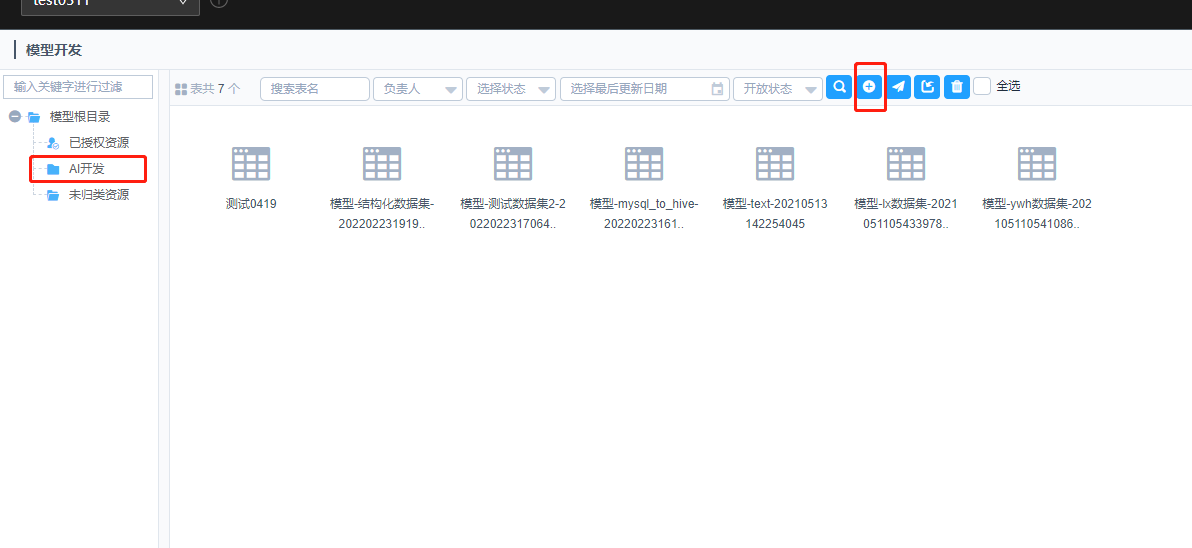
填写表基础信息后,点击下一步
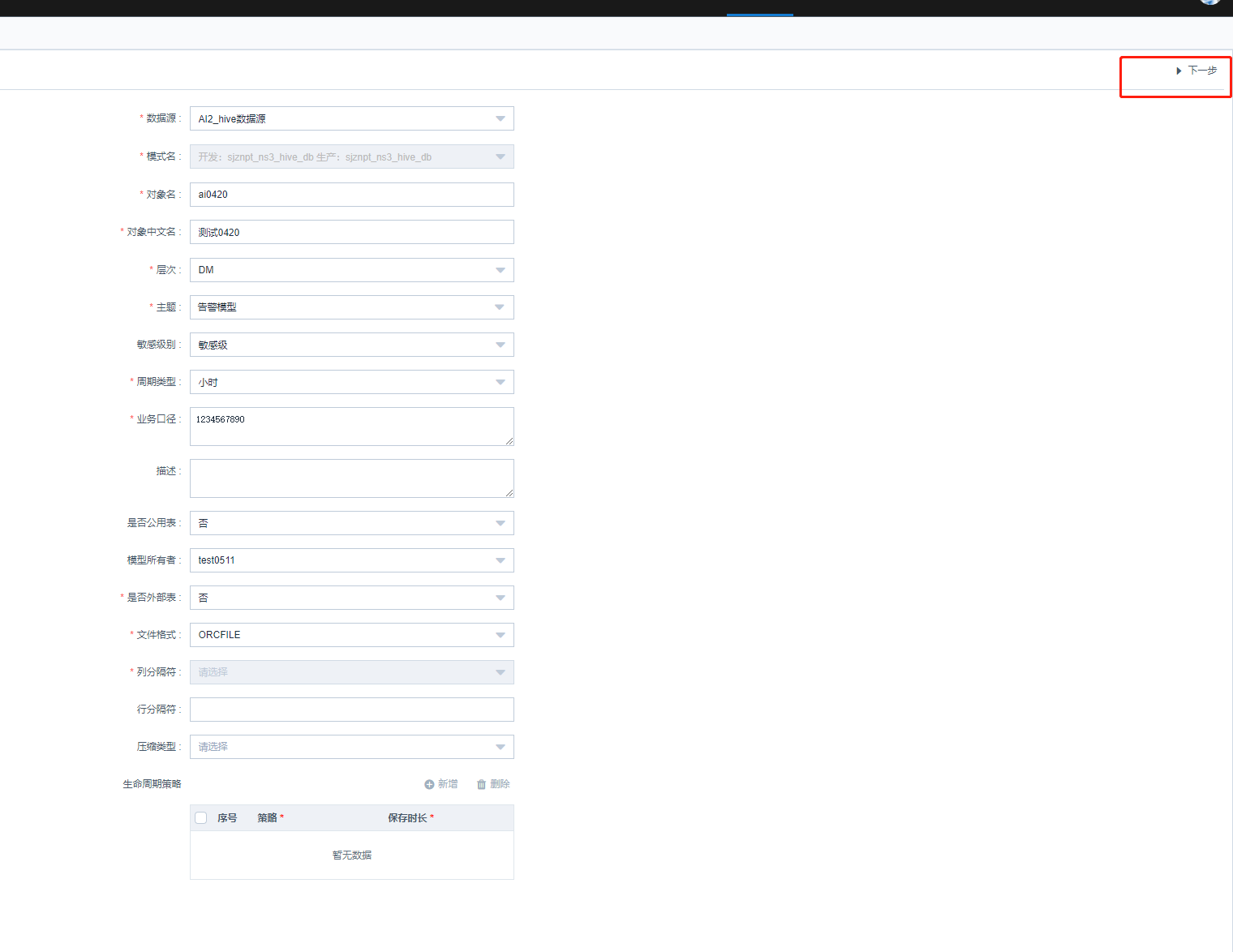
添加所需的字段信息后,点击保存——下一步——保存

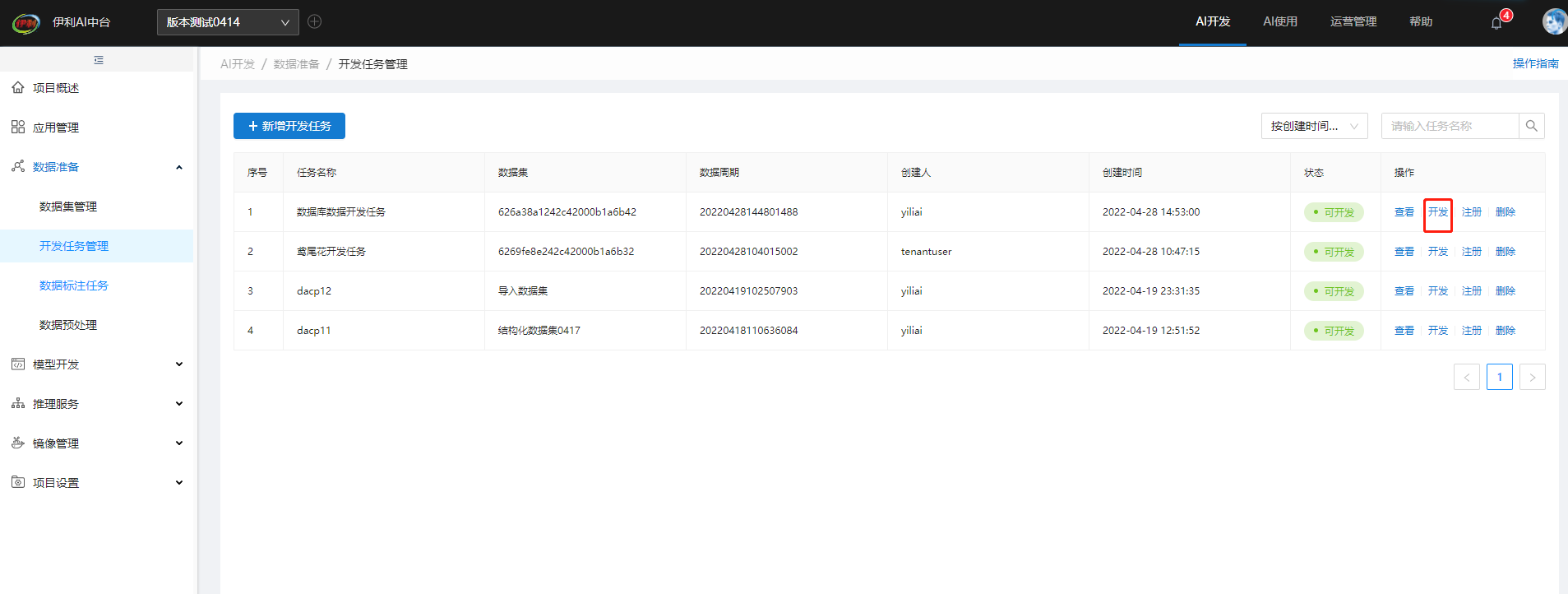
点击开发任务管理——开发任务右侧开发按钮,跳转到可视化编排页面


查找SQL语句组件,将SQL语句组件拖拽到页面和之前的创建表相连,双击进入sql语句组件。

实例选择配置好的hive数据库

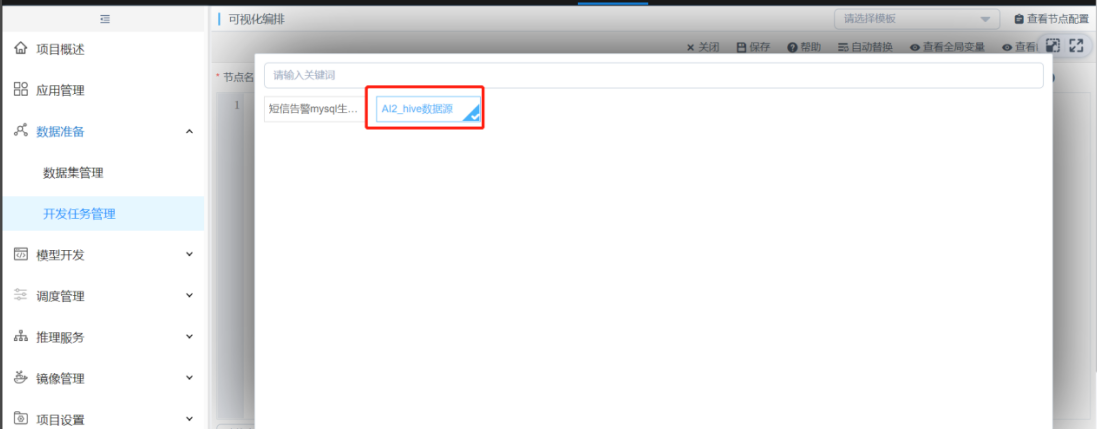
给该表插入数据,执行插入数据语句需要清空其他SQL语句,,注意这里的插入的表名为刚刚创建表中输入表的表名ai0420,点击保存
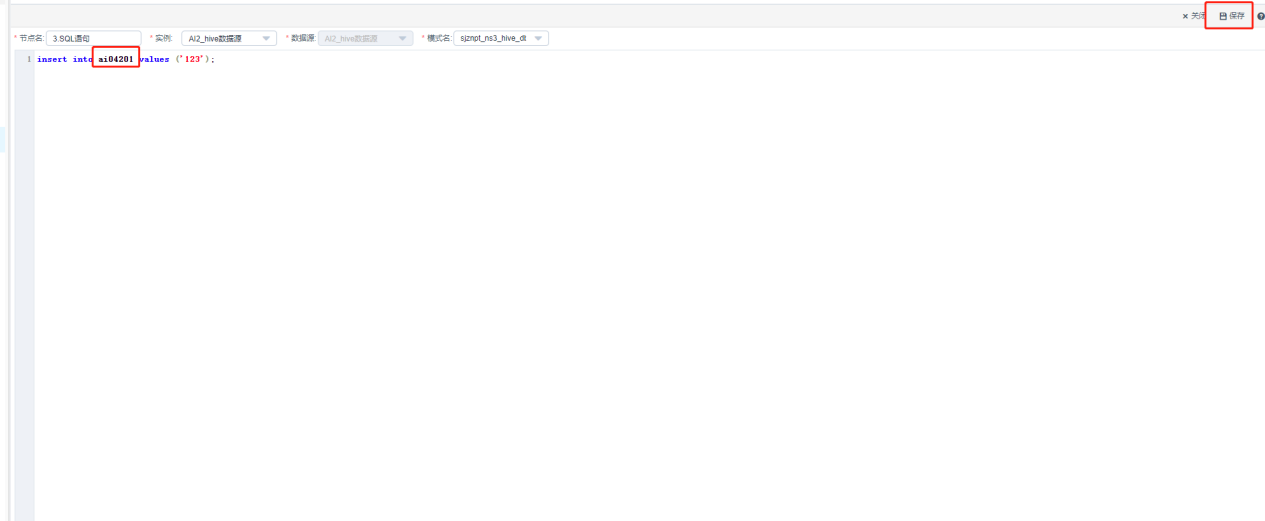
页面自动跳到上一层,再次点击保存,保存成功后点击测试,页面会弹出执行窗口,点击右侧执行键,点击执行,当显示执行成功并结束后,证明该数据插入成功。

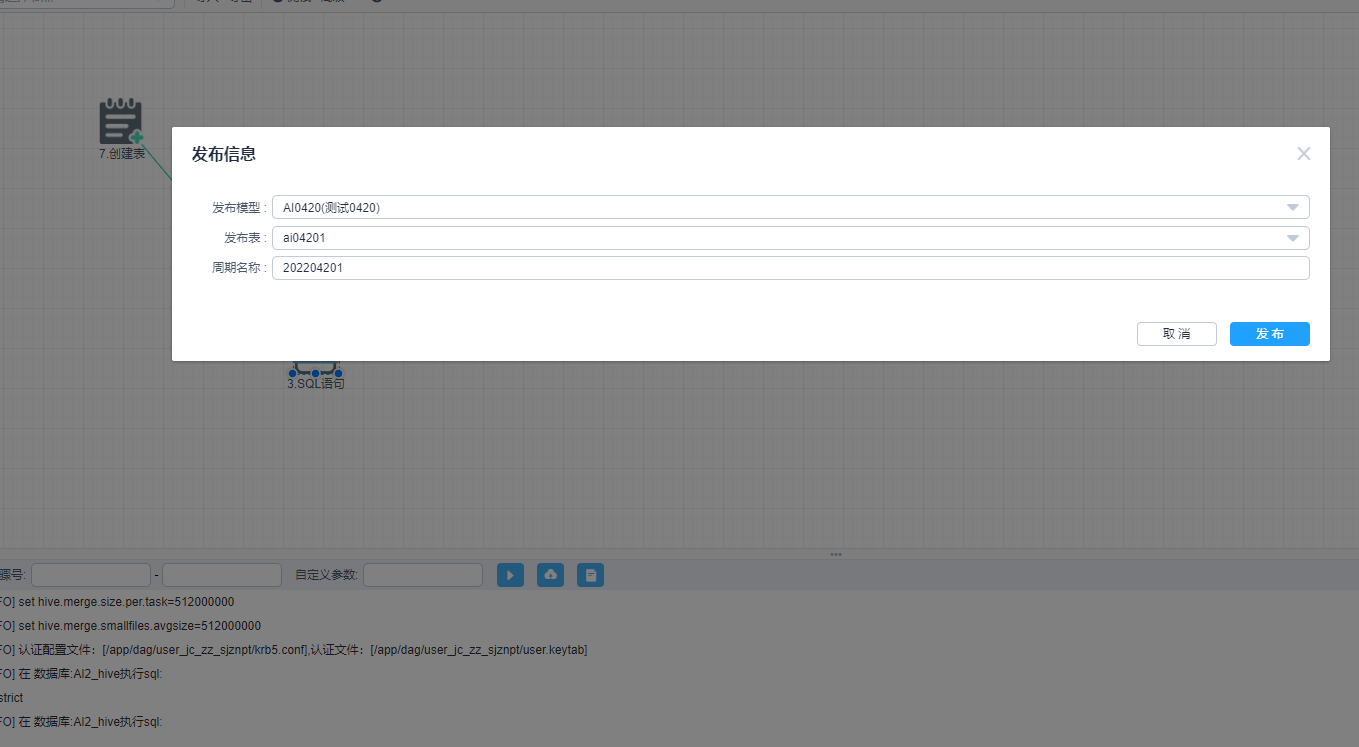
点击任务发布,选择相应的发布模型,发布表并填写周期后发布
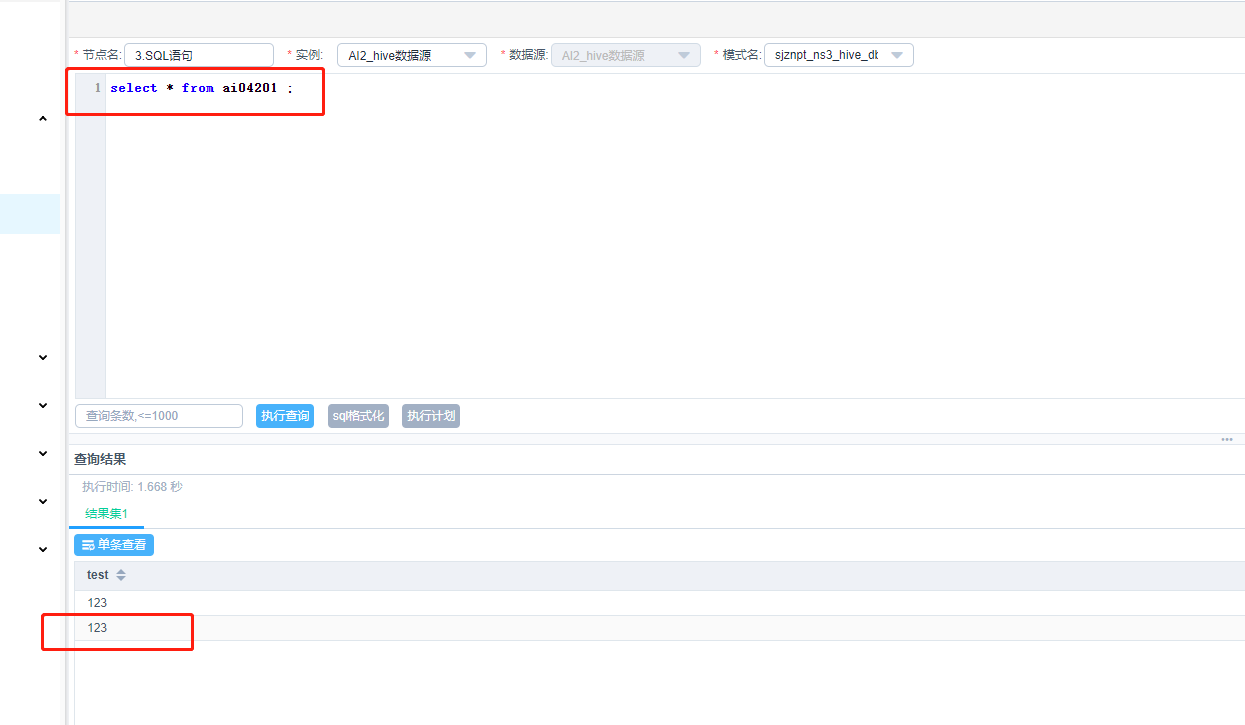
双击SQL语句组件,进入页面执行查询语句,可以看到数据插入成功。
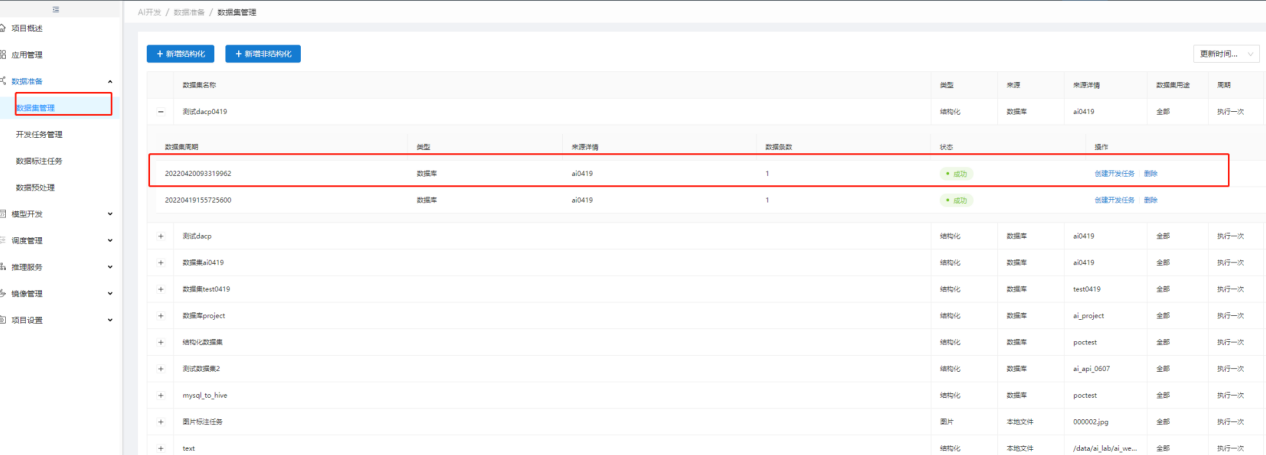
点击数据集管理查看数据集,发现有新的数据集周期被发布
1.2.6. 标注非结构化数据
1.2.6.1 音频标注
操作步骤
步骤1:新增非结构化数据集
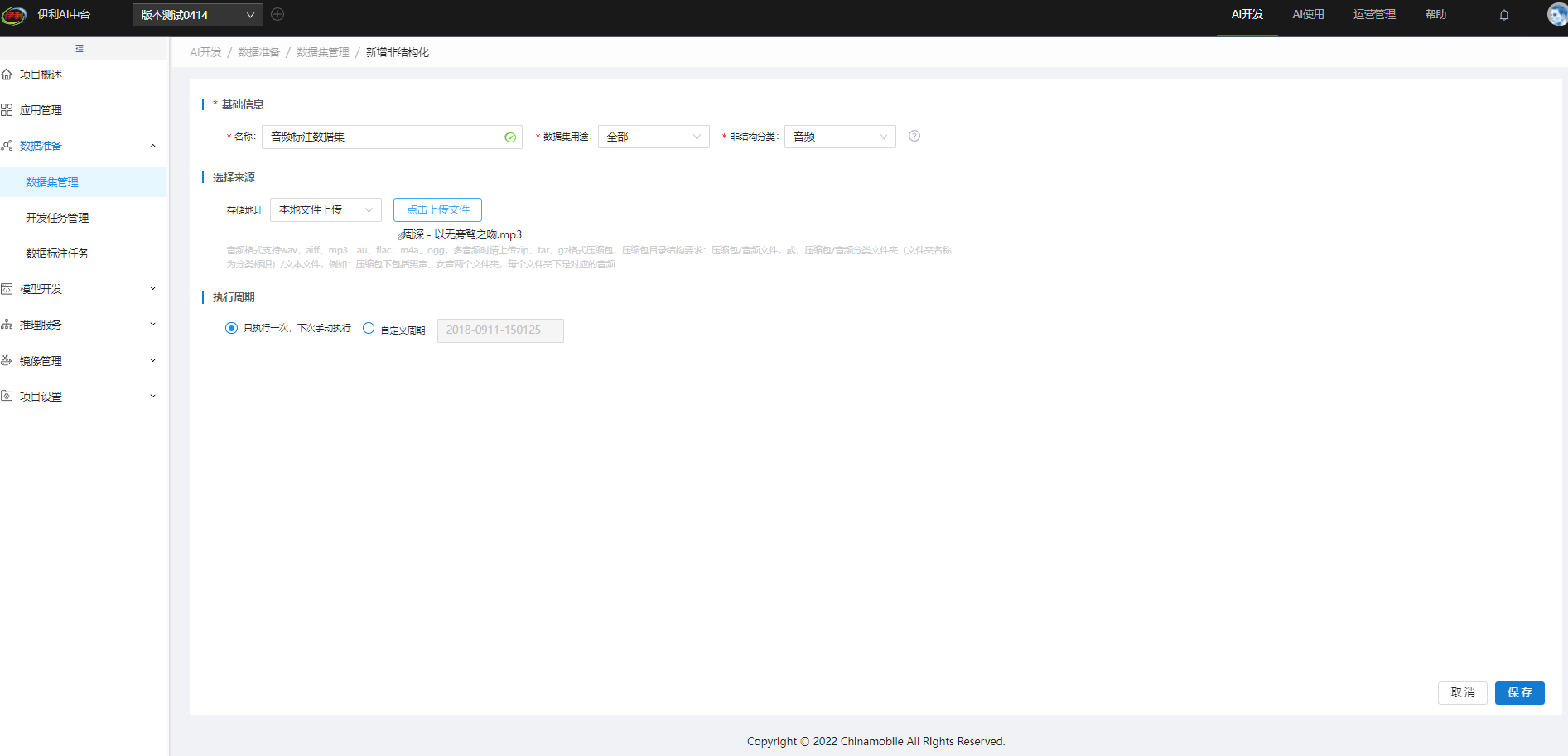
步骤2:创建标注任务,有两个入口,一是在数据集创建标注任务
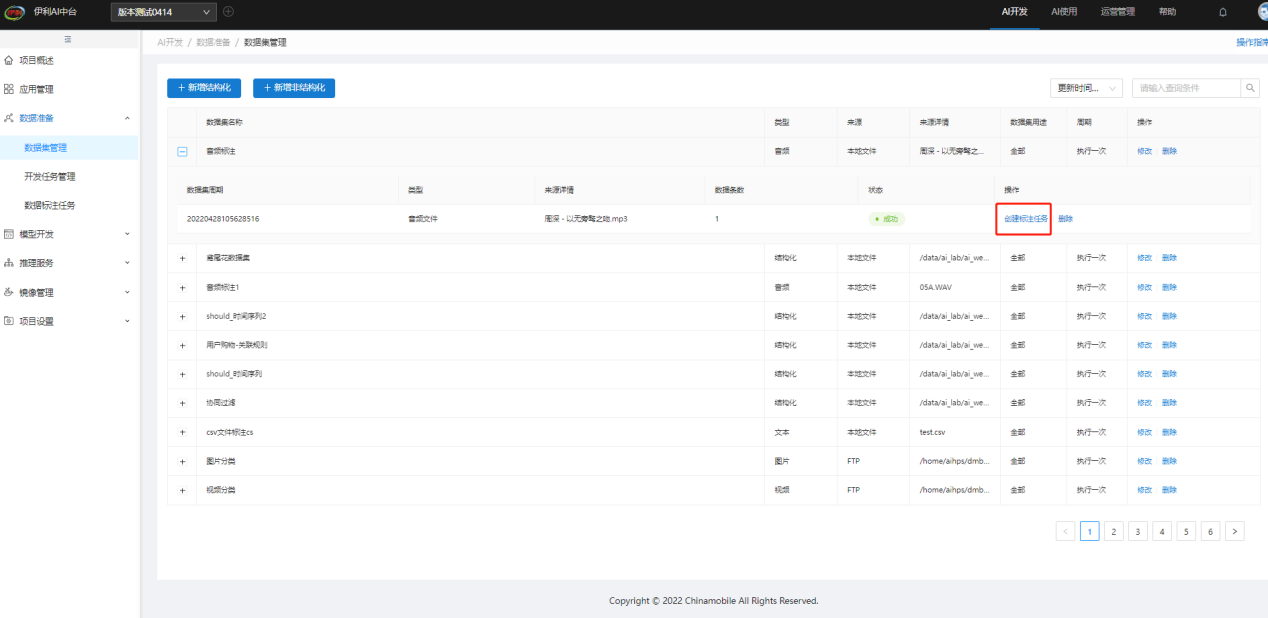
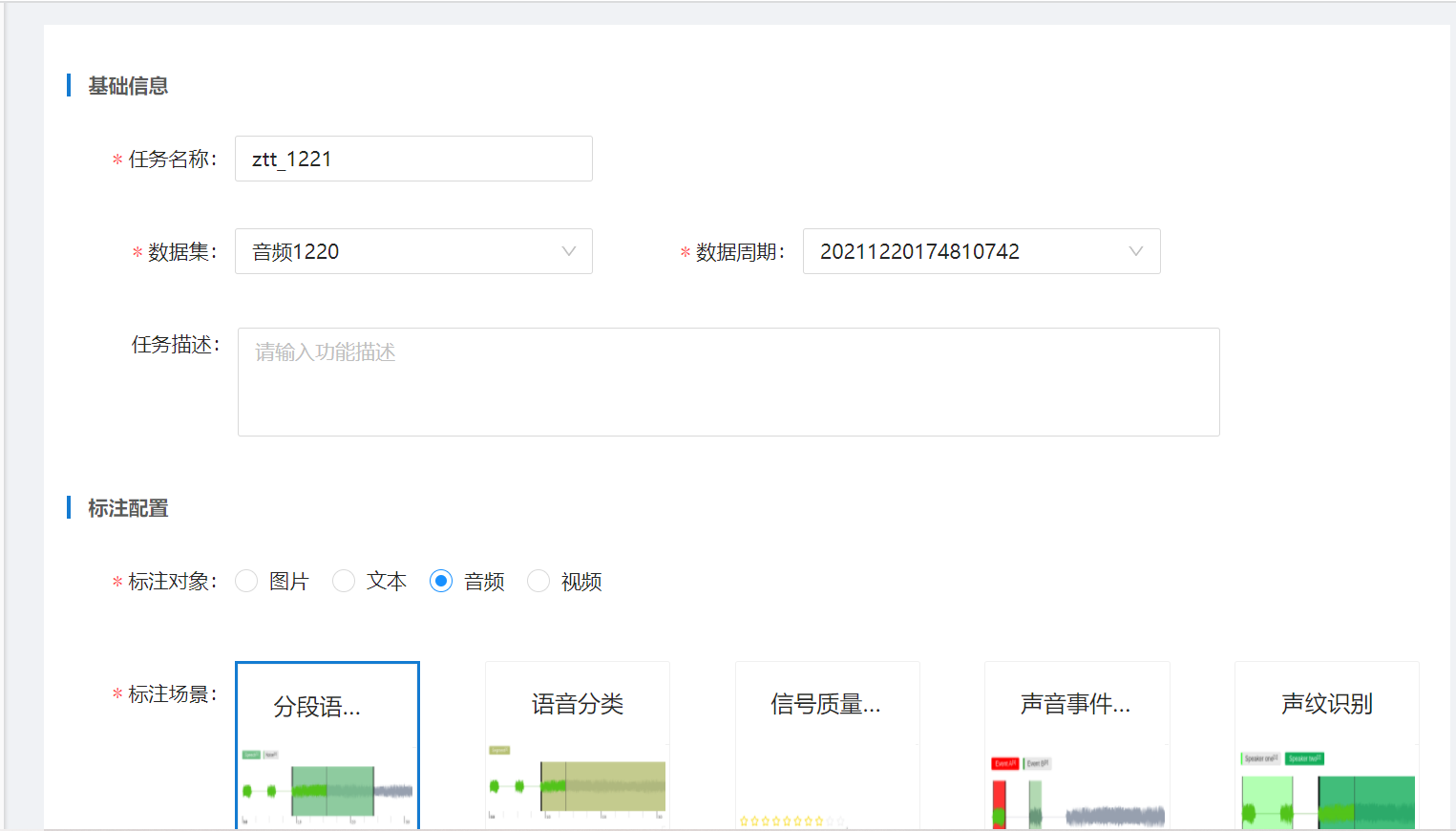
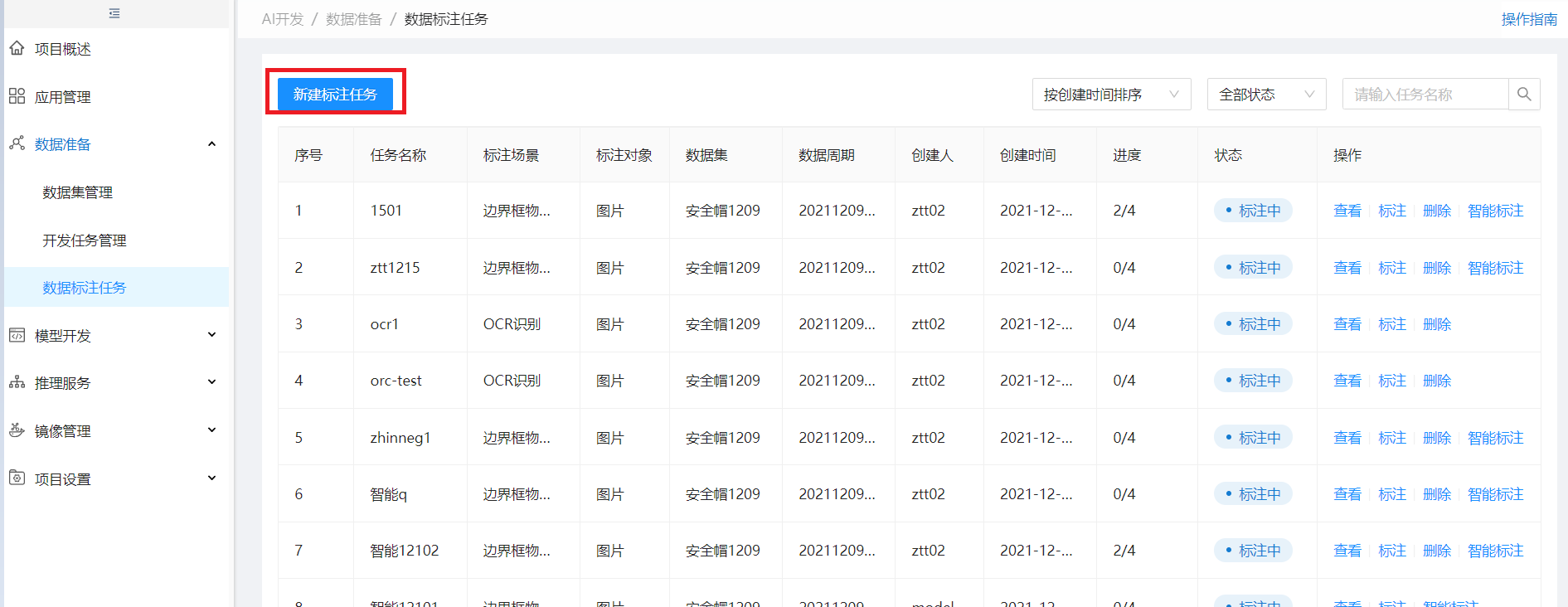
二是数据标注任务菜单,创建标注任务
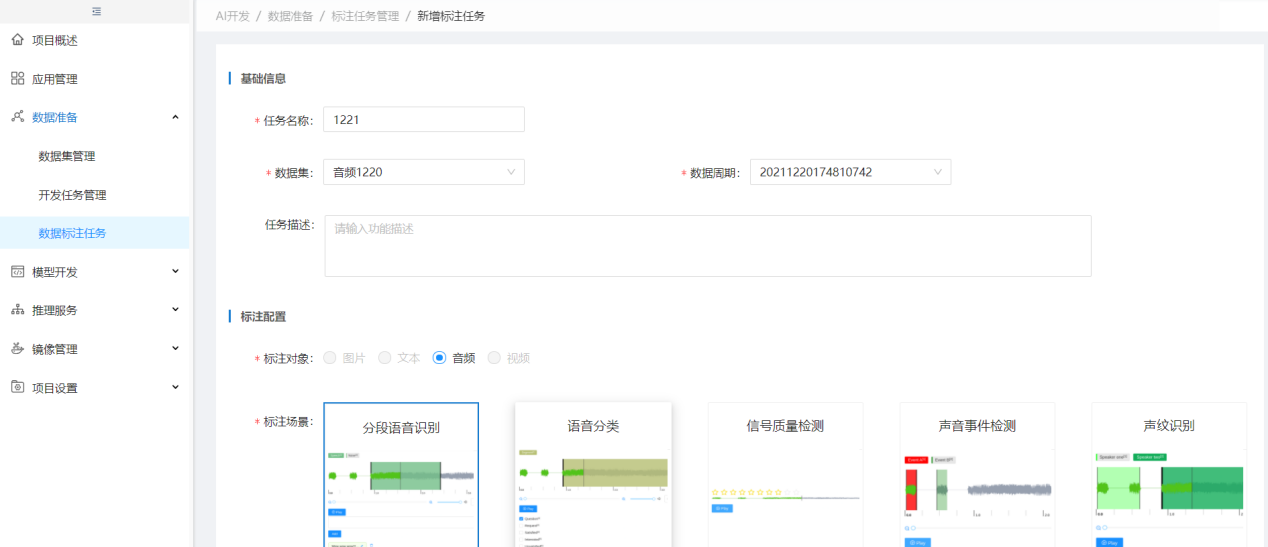
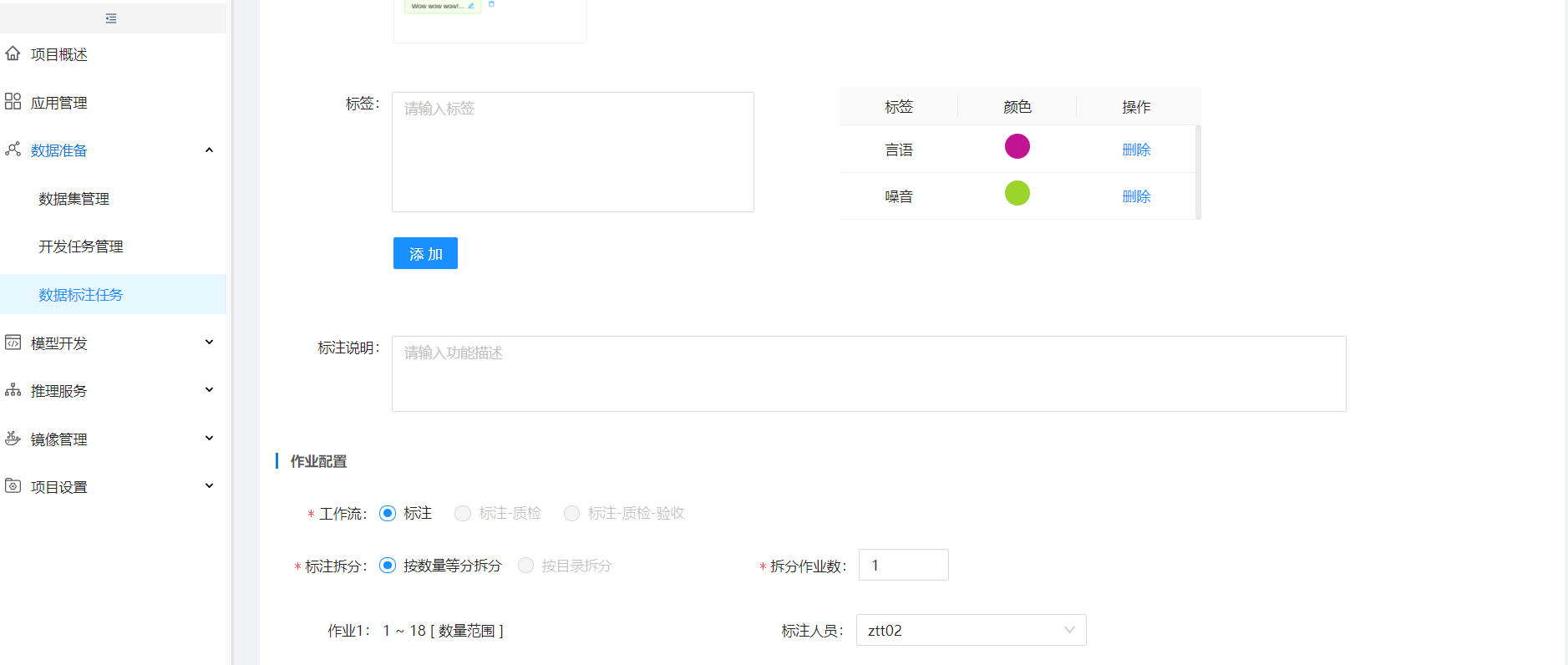
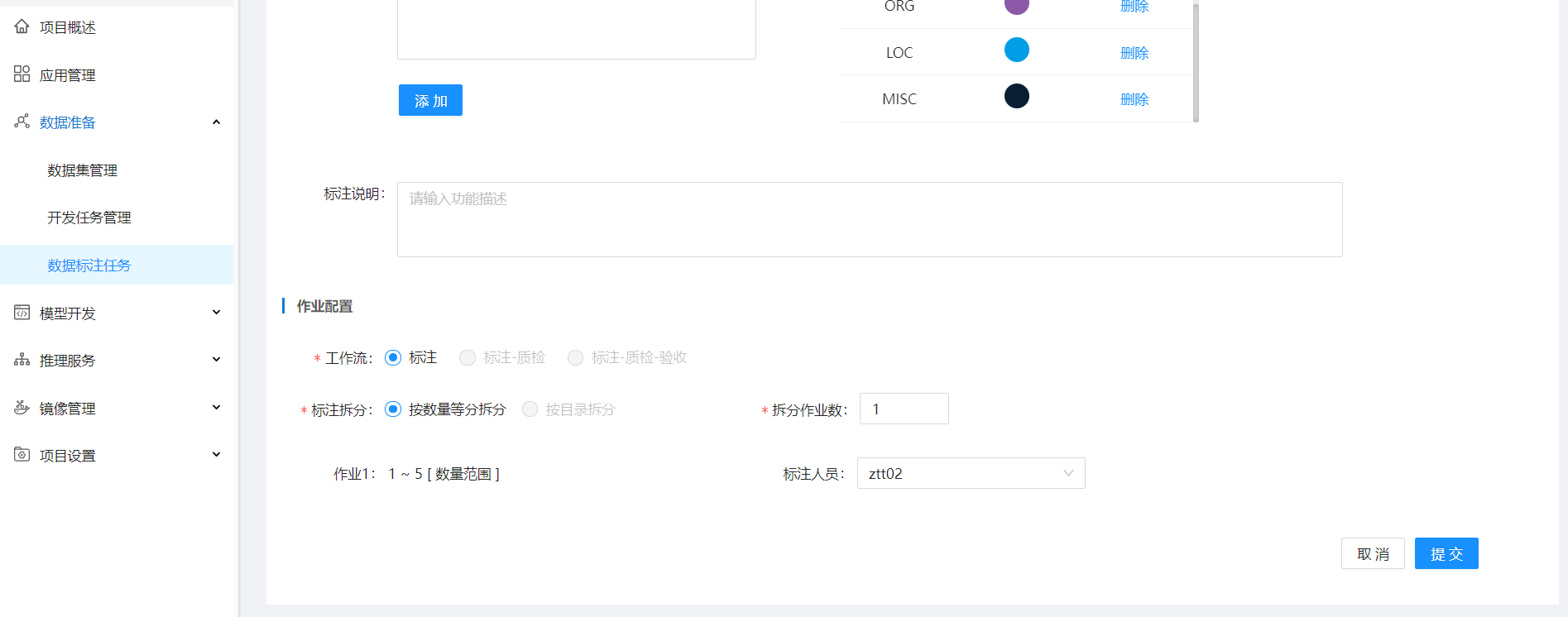
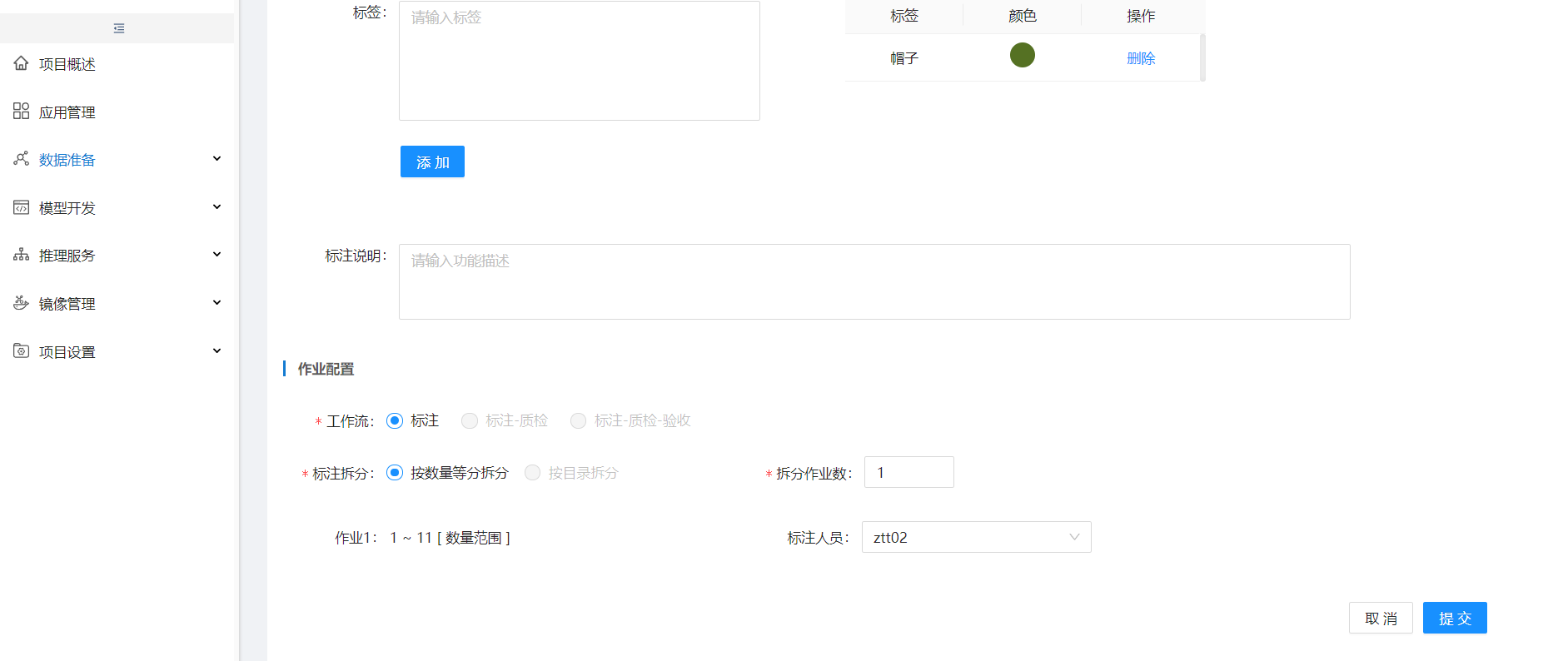
选择数据集,选择标注对象、标注场景,根据需要配置标签,并分配标注人员
步骤3:标注人员登陆,进行数据标注
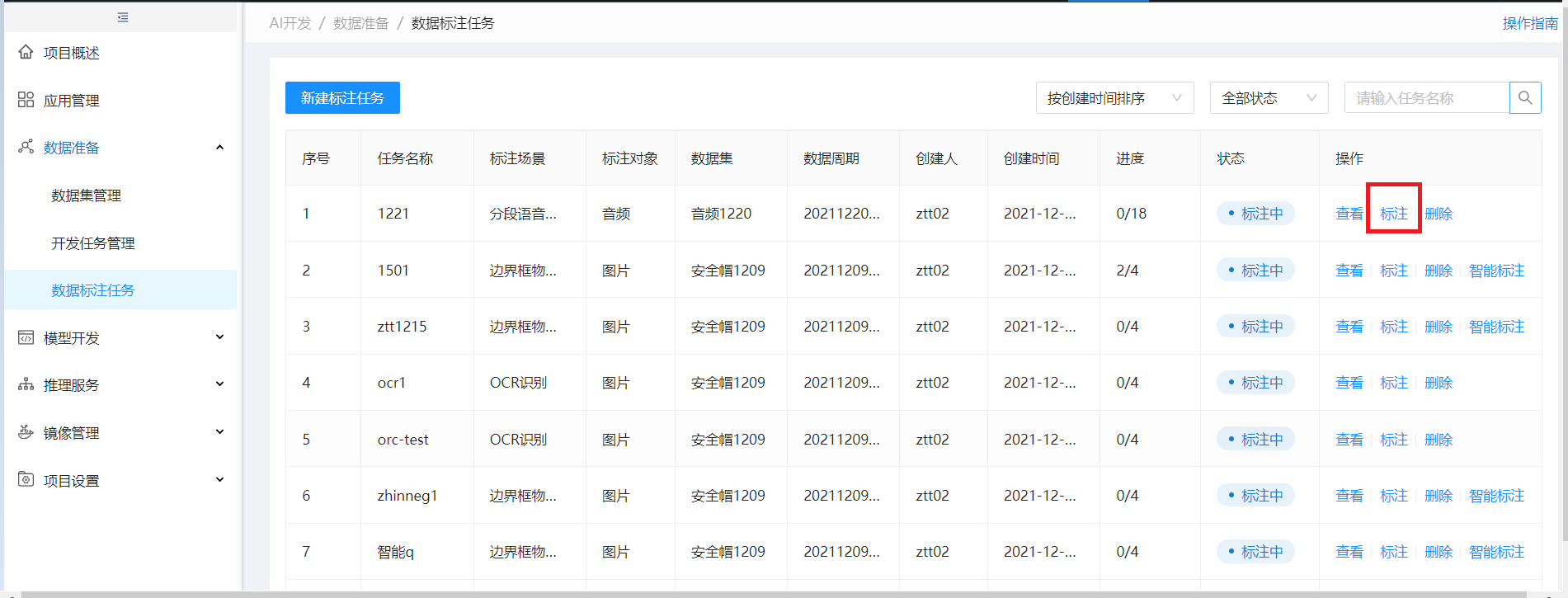
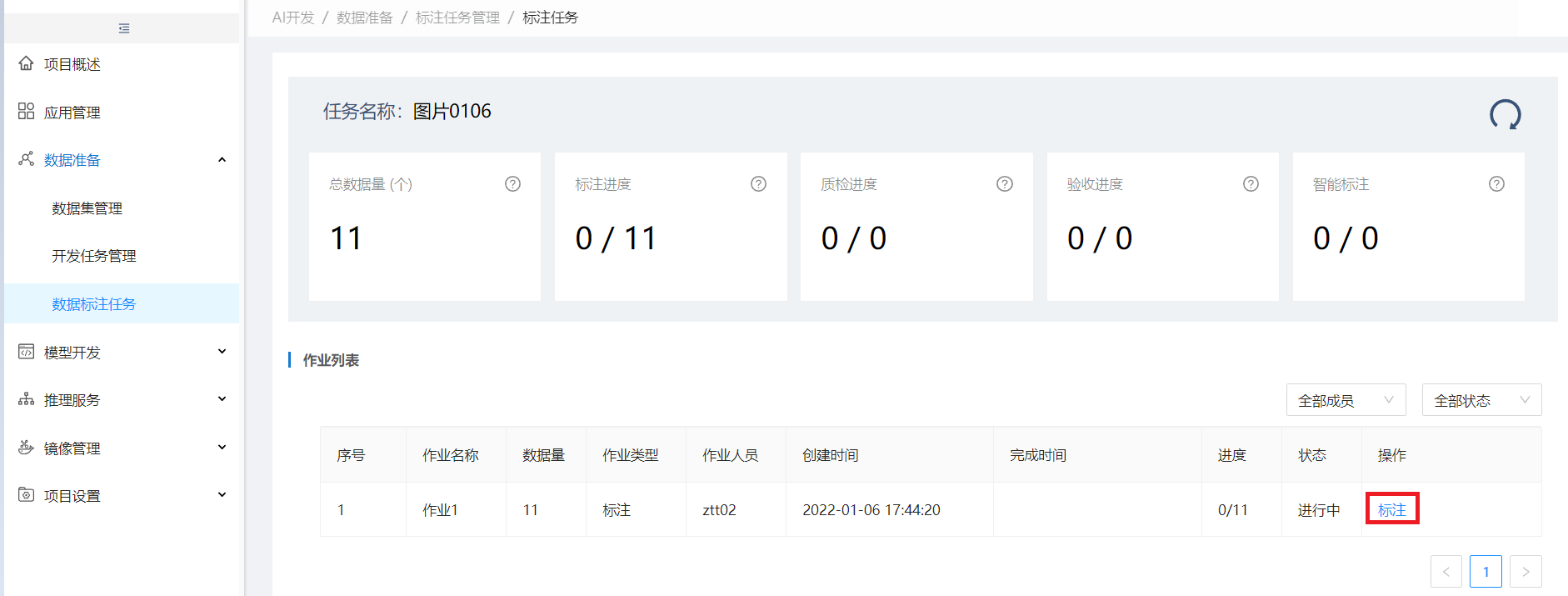
进入作业列表,点标注进入LabelStudio进行标注

LabelStudio页面进行标注,并提交
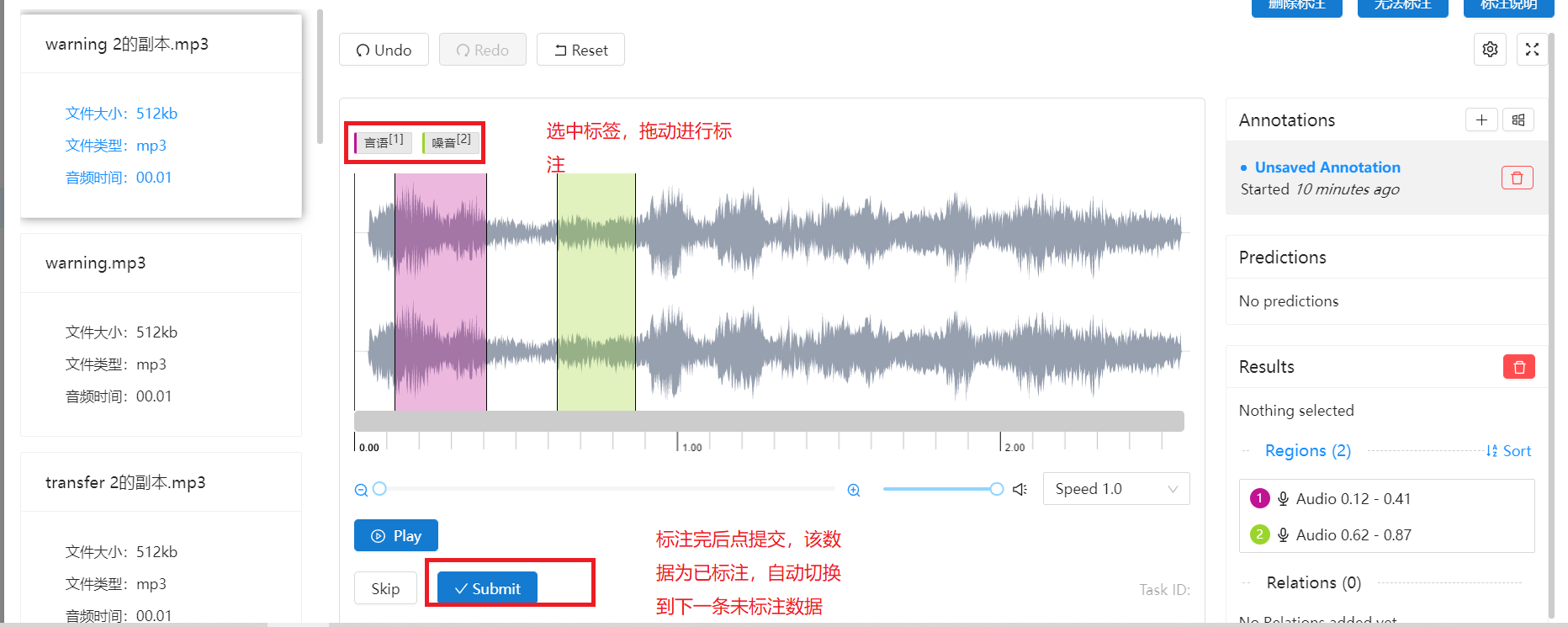
作业标注完后,点作业列表刷新按钮,若该作业进度为100%时,作业列表操作列出现发布按钮,点发布按可进行标注作业发布
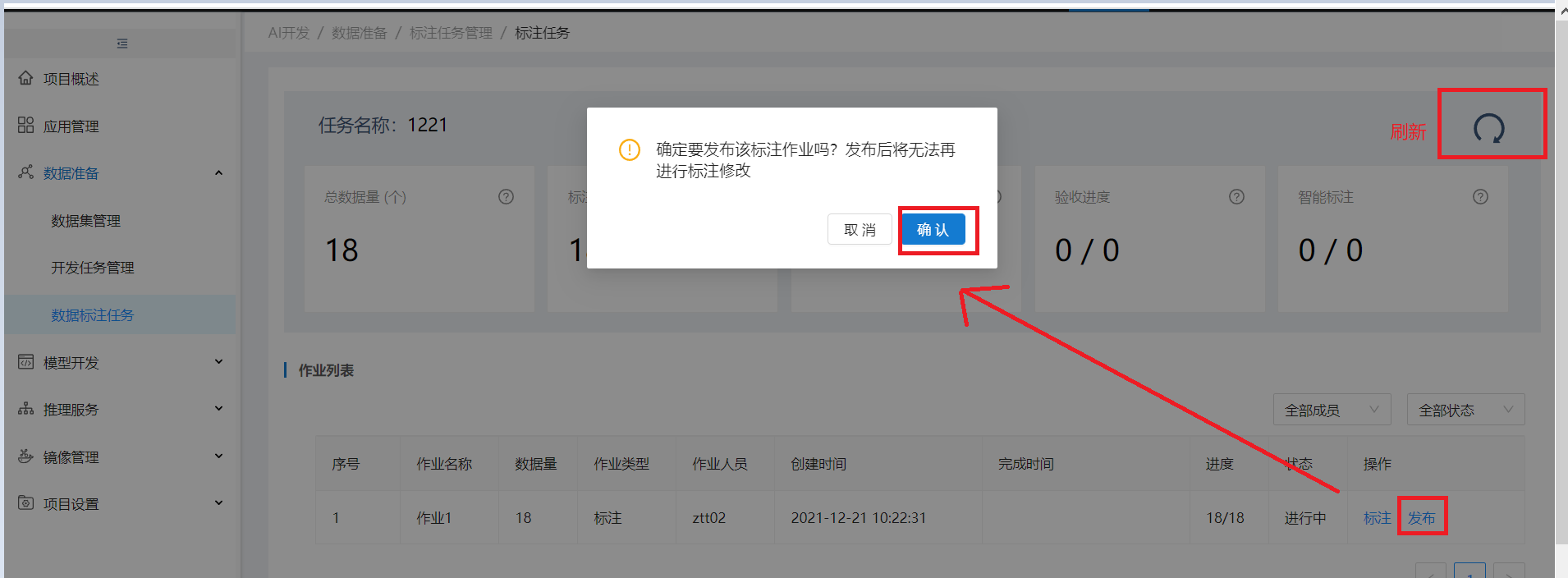
发布后该作业状态为:已完成
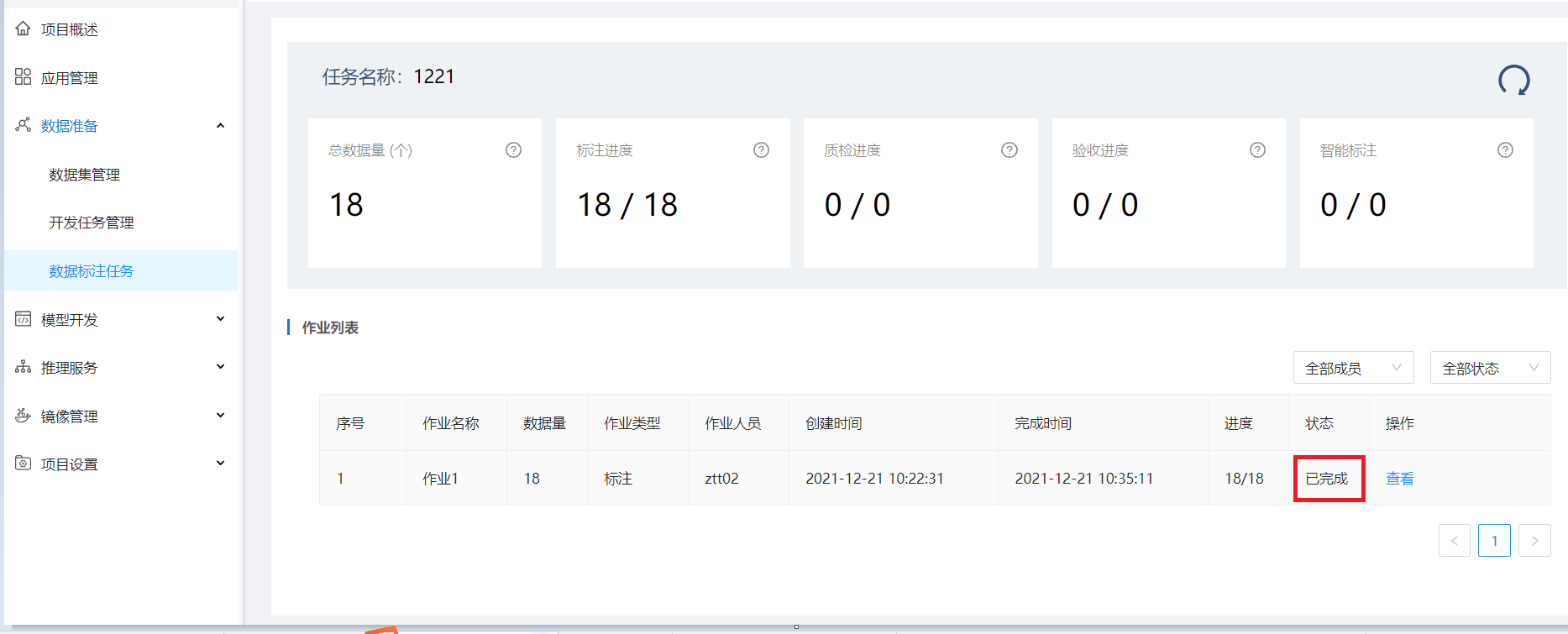
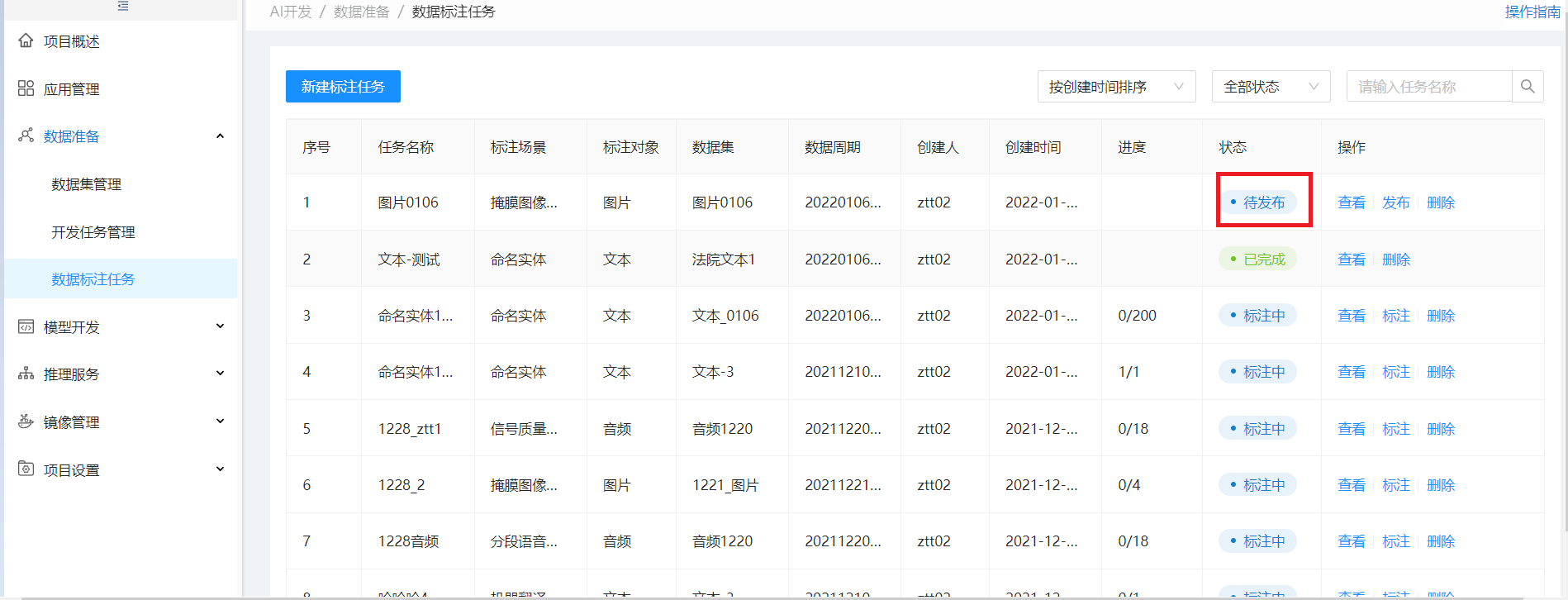
步骤4:发布标注任务
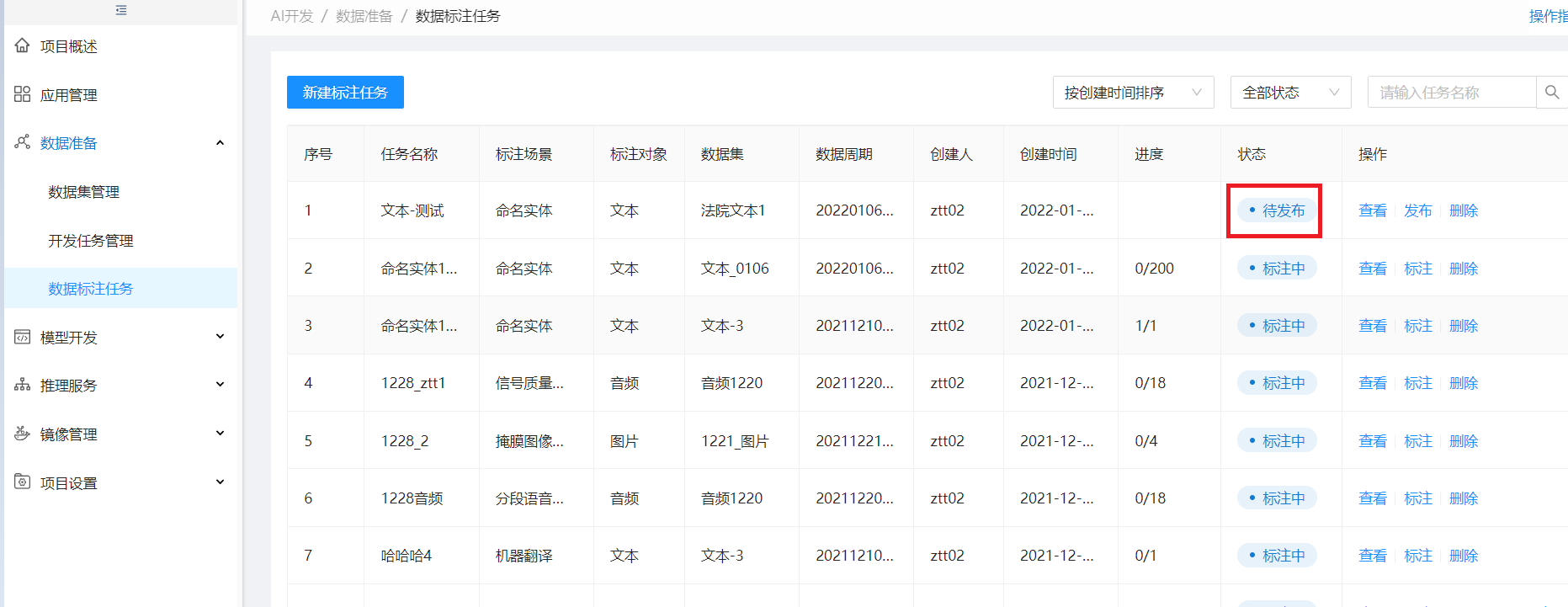
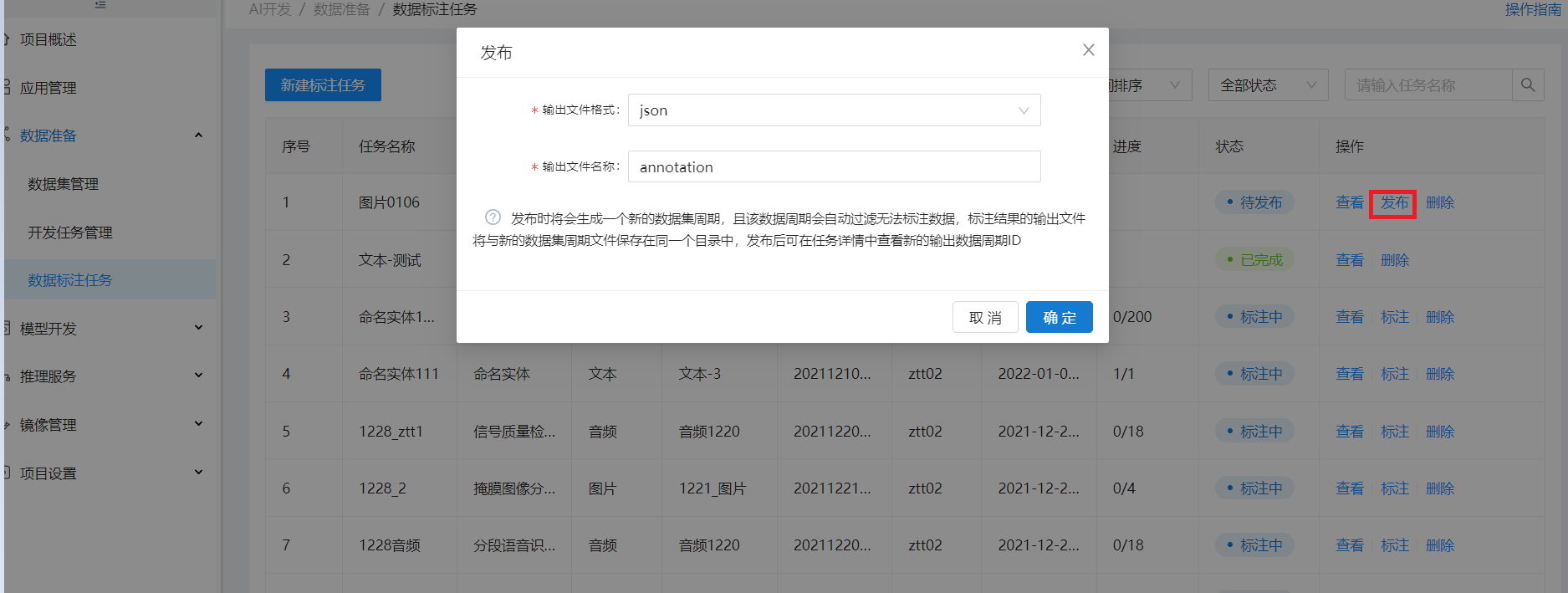
当该标注任务下的所有标注作业状态都为“已完成” 时,标注任务列表该任务状态为待发布,操作列出现发布按钮,点发布可发布该标注任务
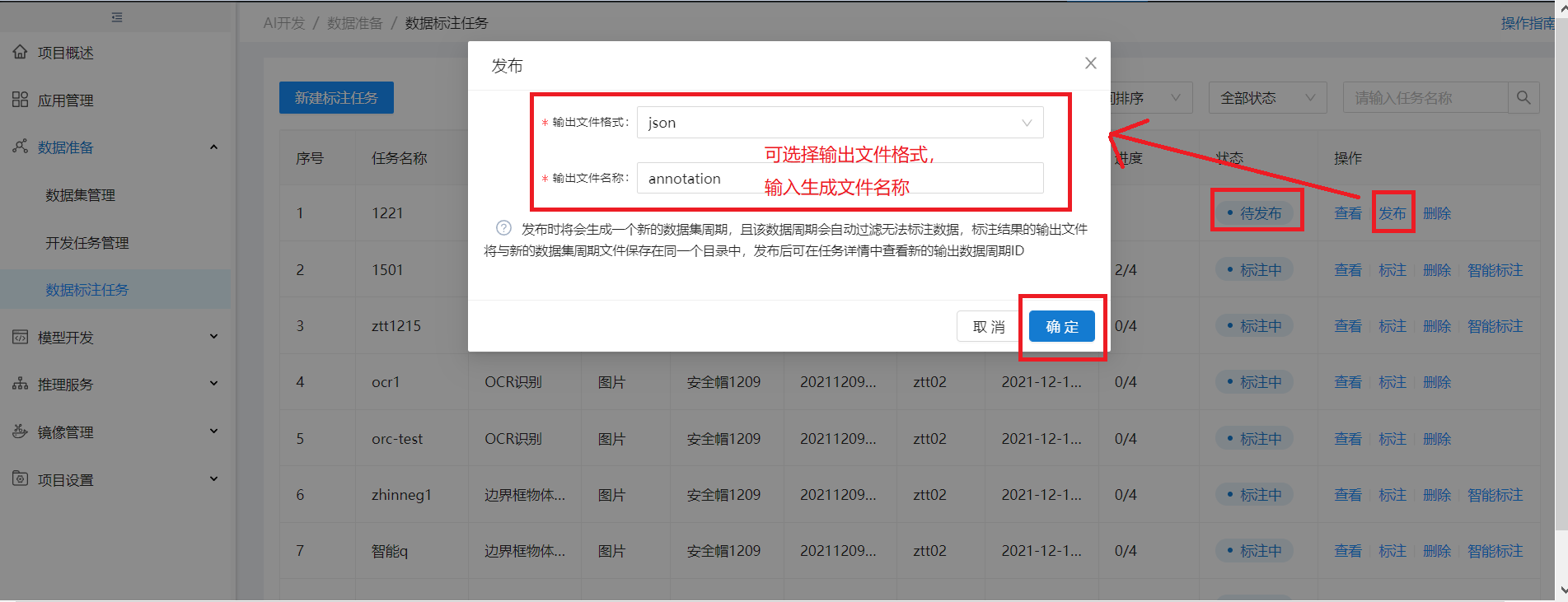
发布后,该任务状态为已完成
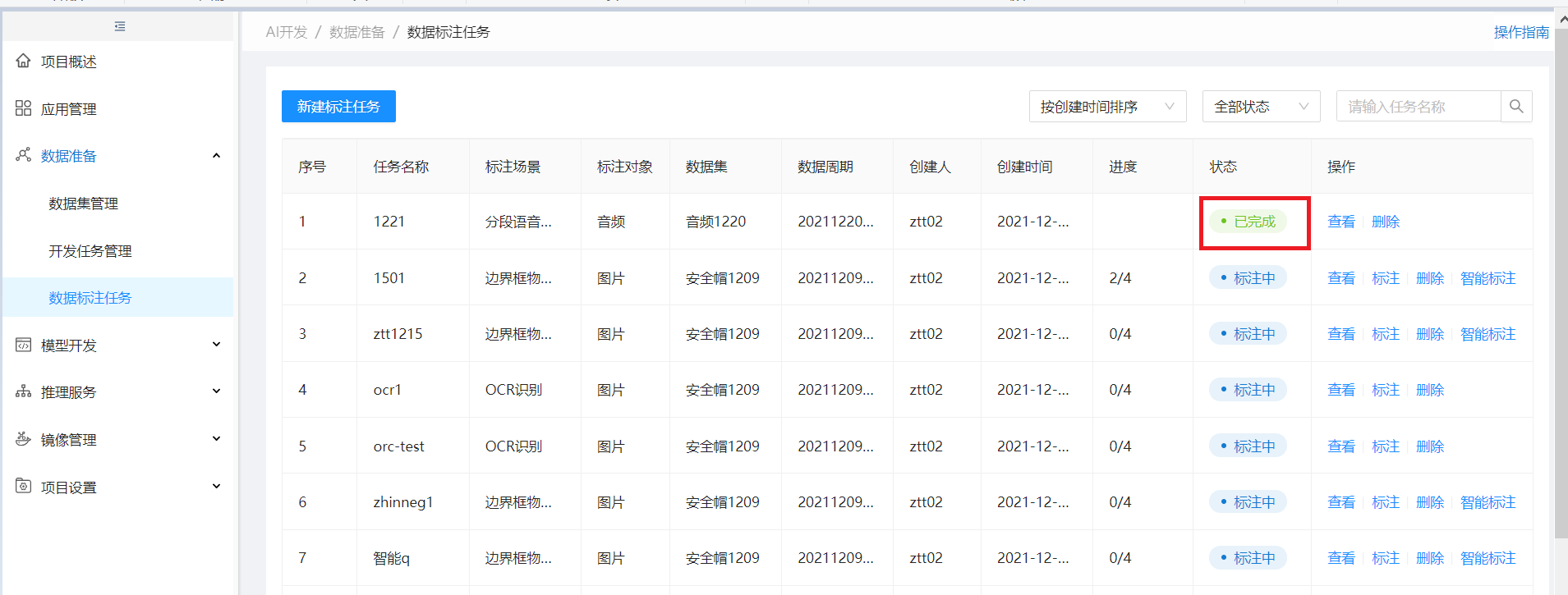
步骤5:下载标注输出文件
选择状态为已完成的标注任务,点查看

点击文件名称进行下载,输出文件默认删除无法标注数据;且生成新的周期数据

查看生成数据周期

步骤6:查看标注数据状态
标注任务点查看,切到数据信息页签,可查看标注状态,开始为:未标注、后面根据LabelStudio标注情况显示:已标注或无法标注
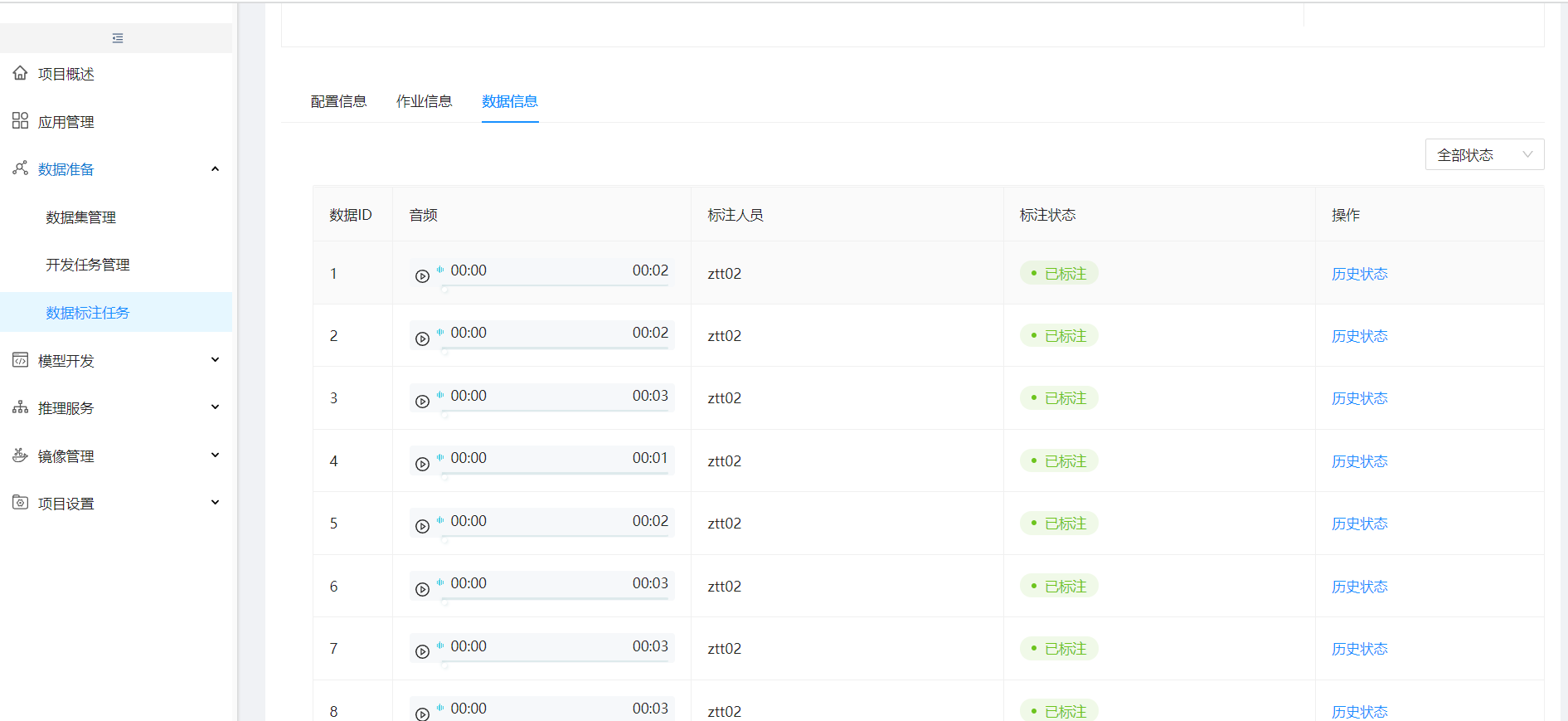
测试数据
1.2.6.2 文本标注
操作步骤
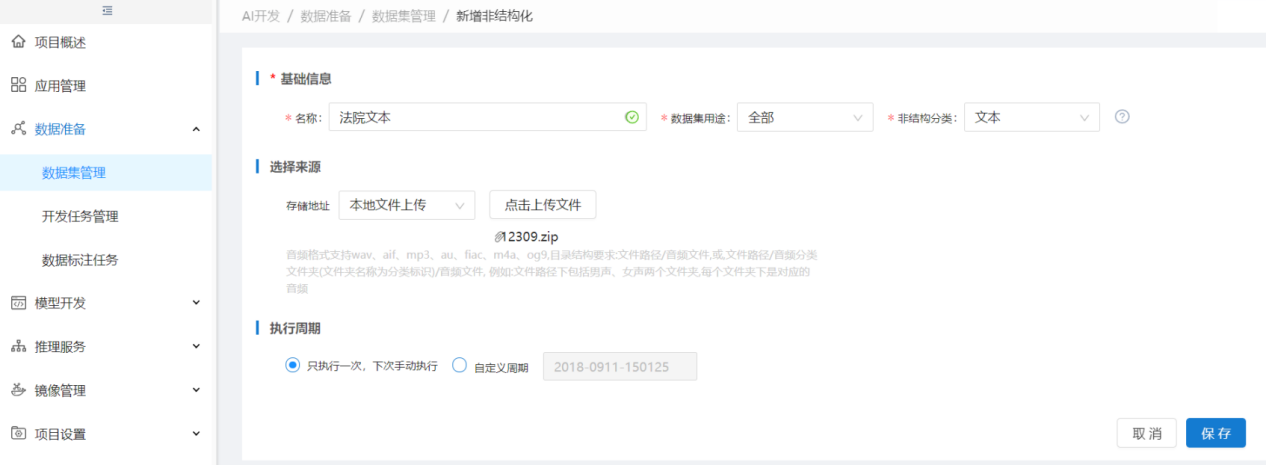
步骤1:新增非结构化数据集,选择非结构分类为:文本
步骤2:创建标注任务,标注对象选择文本,其他与音频标注一致

步骤3:标注人员登陆,进行数据标注
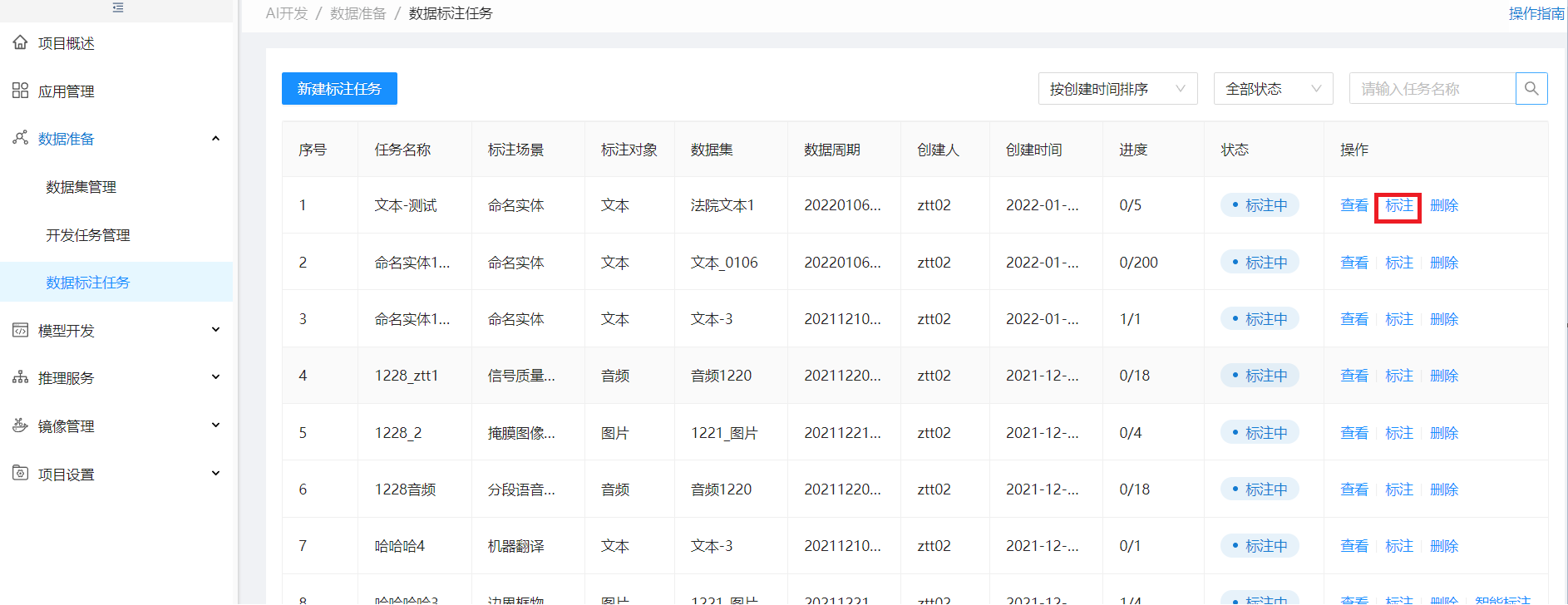
进入作业列表,点标注进入LabelStudio进行标注
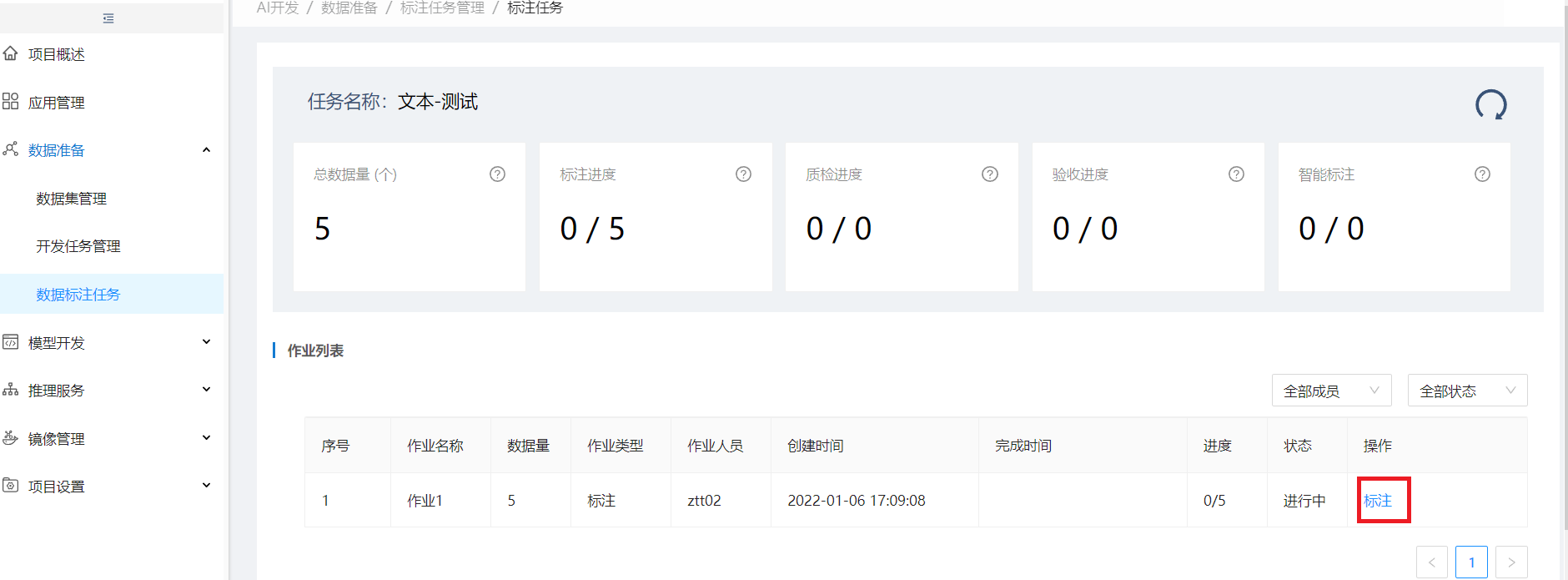
LabelStudio标注,选中标签进行标注
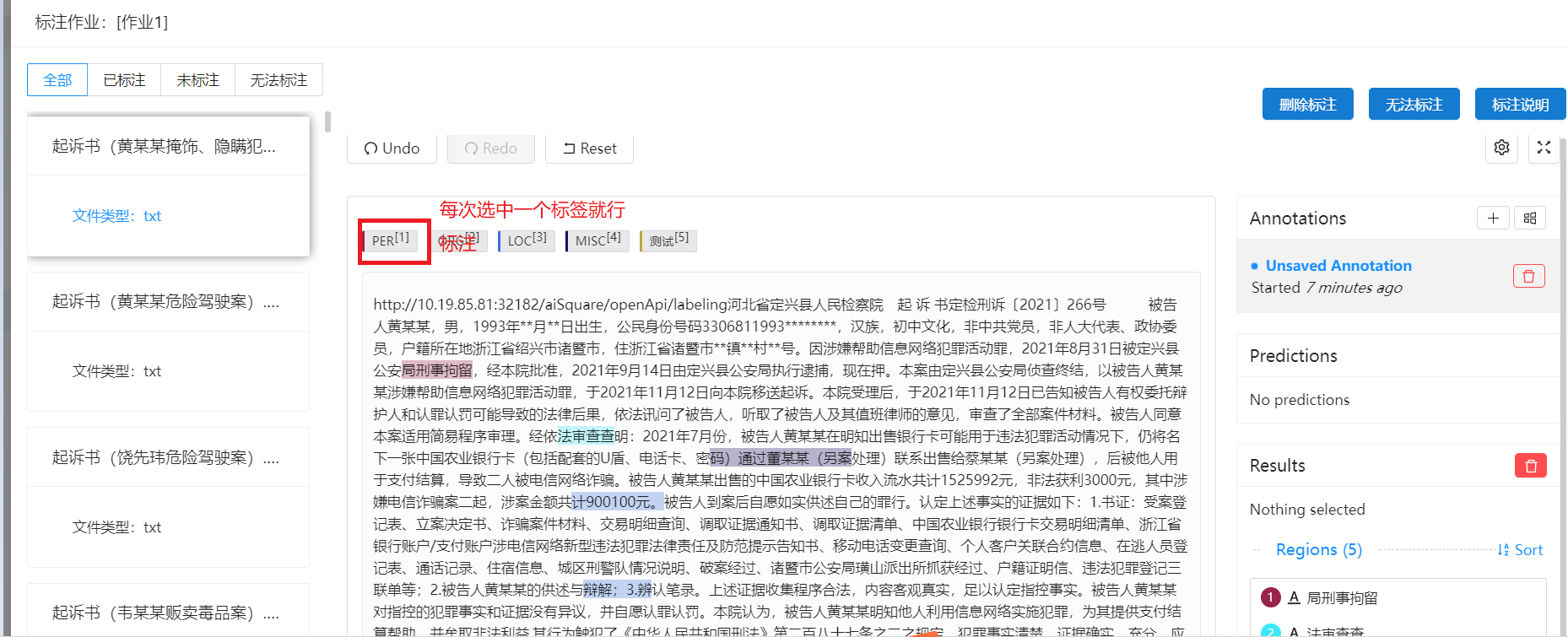
标注完后提交,继续标注下一个文件
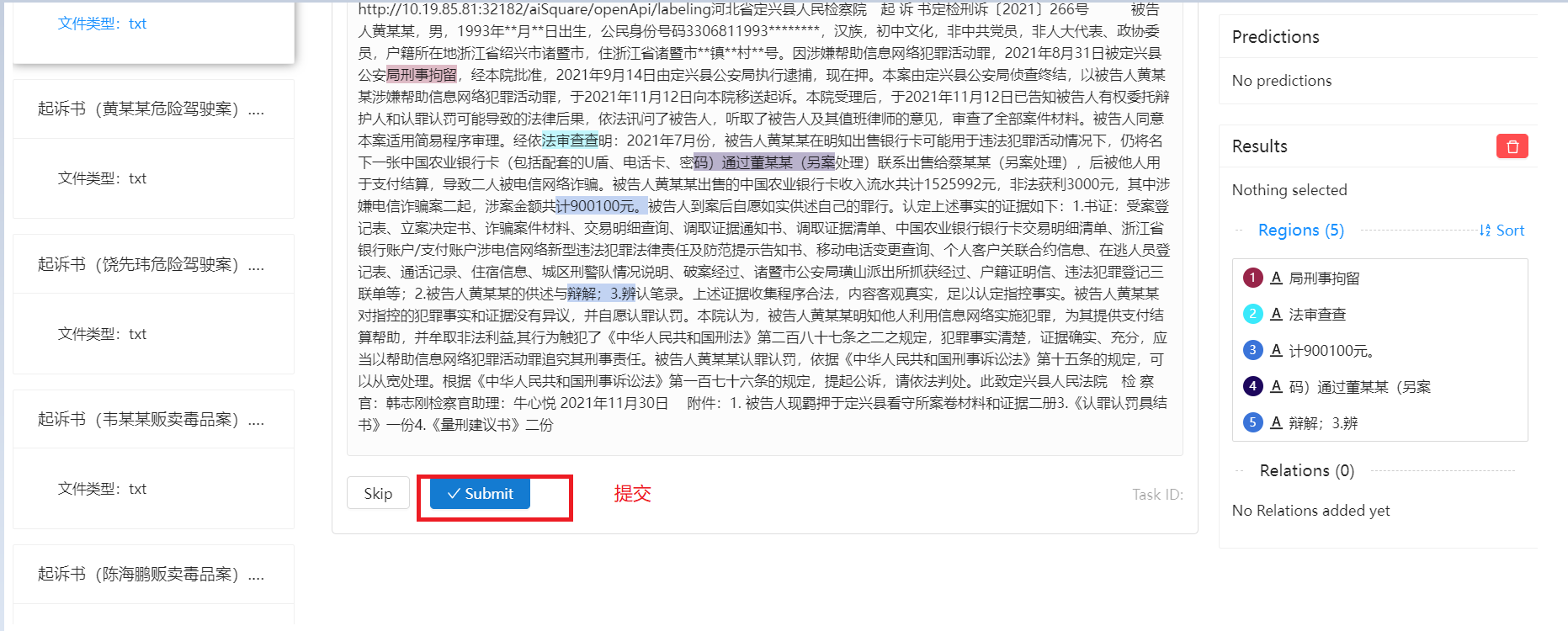
作业标注完后,点作业列表刷新按钮,若该作业进度为100%时,作业列表操作列出现发布按钮,点发布按可进行标注作业发布
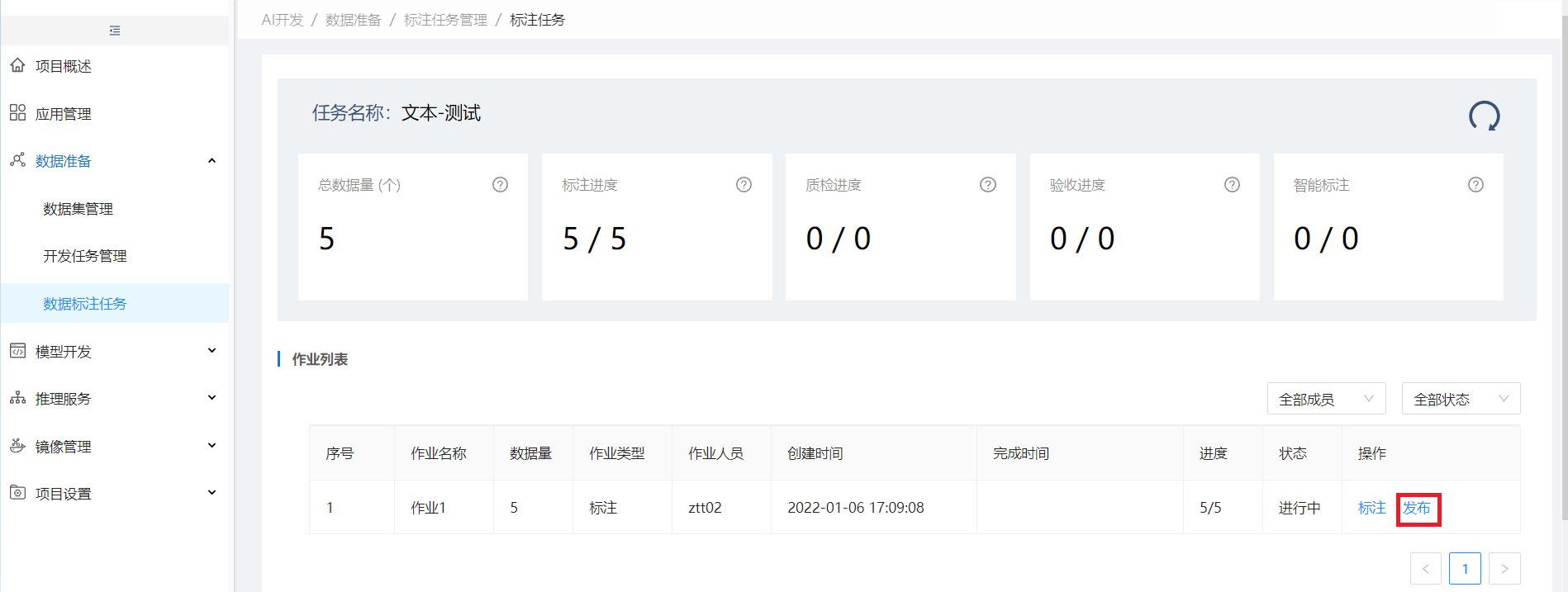
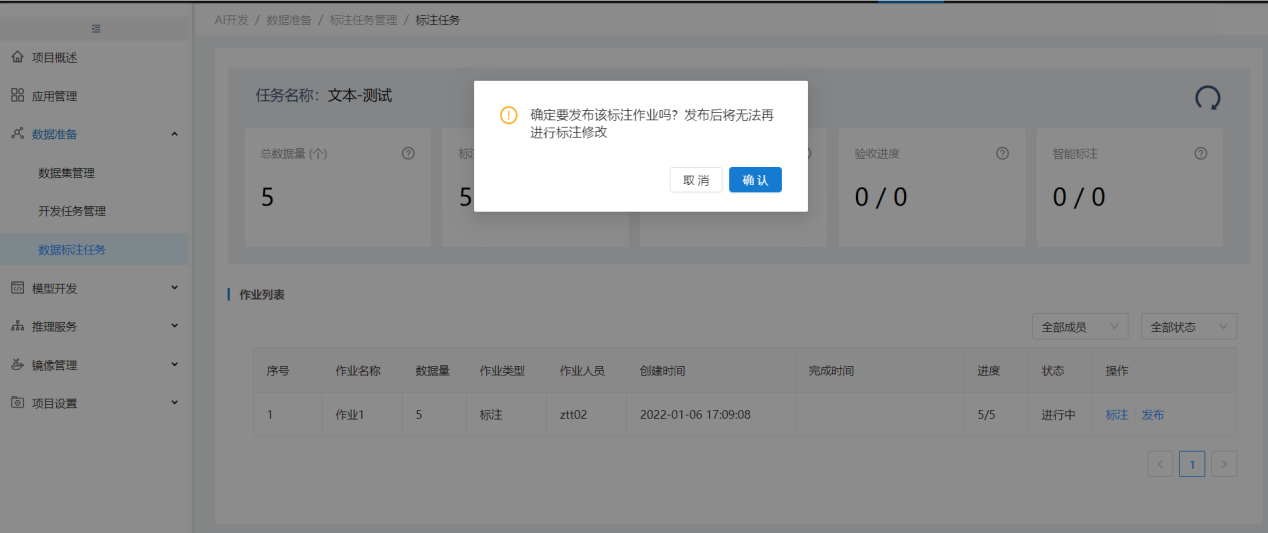
步骤4:发布标注任务
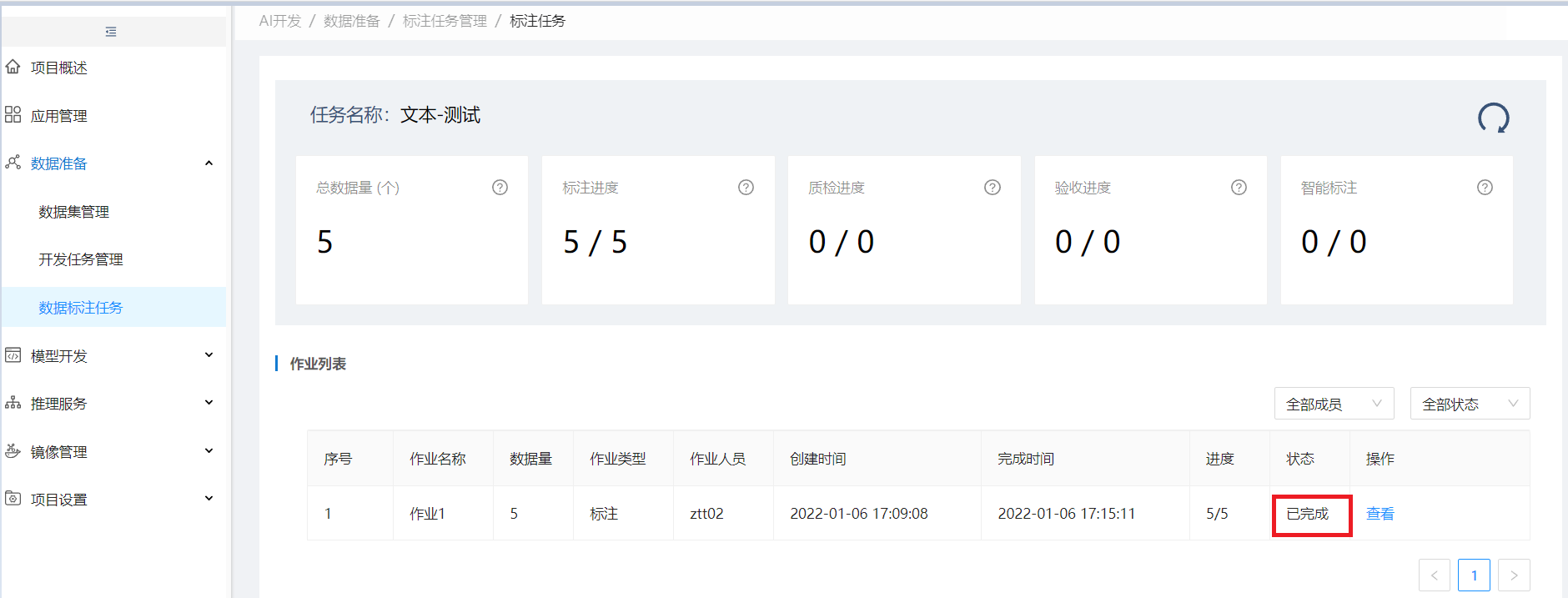
当该标注任务下的所有标注作业状态都为"已完成"时,标注任务列表该任务状态为待发布,操作列出现发布按钮,点发布可发布该标注任务
点击发布按钮,发布后,该任务状态为已完成
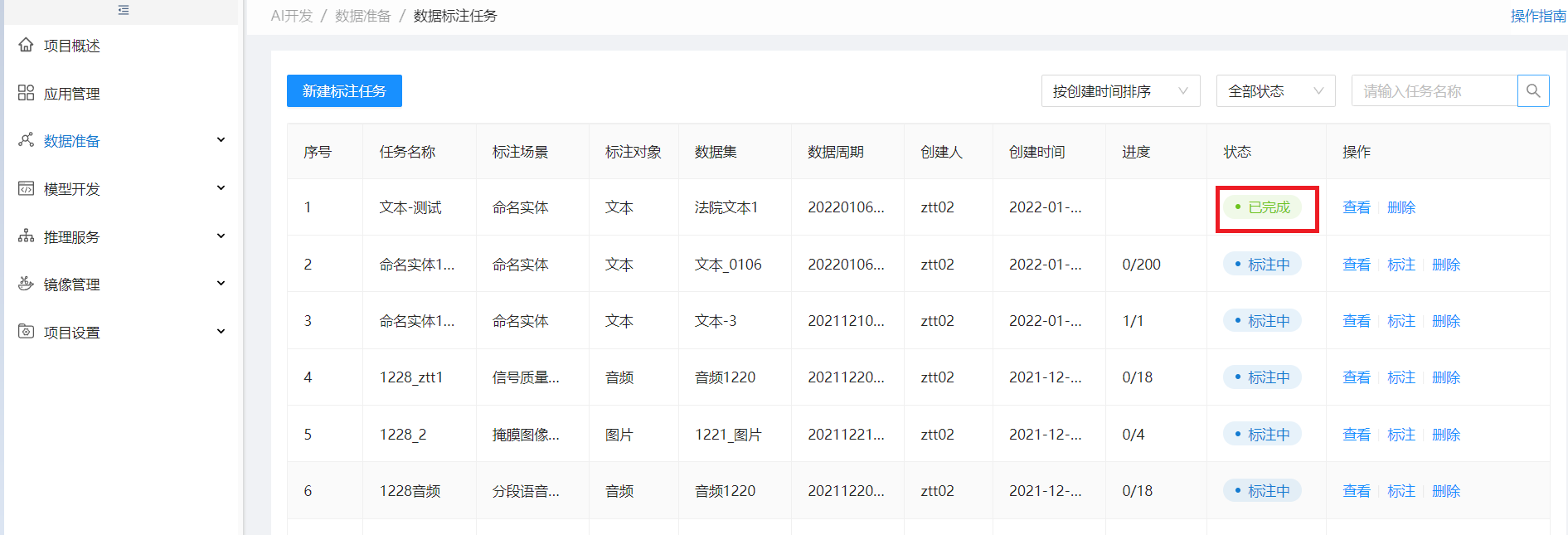
步骤5:下载标注输出文件
选择状态为已完成的标注任务,点查看
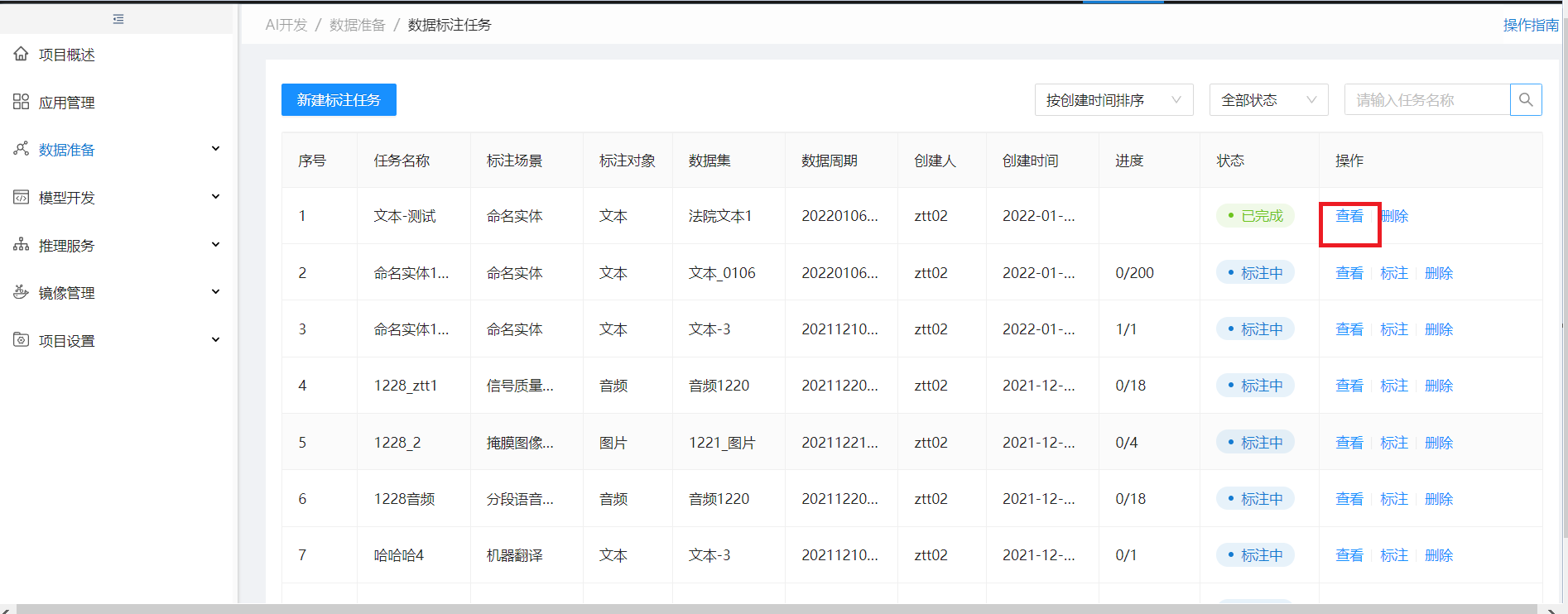
点击文件名称进行下载,输出文件默认删除无法标注数据;且生成新的周期数据
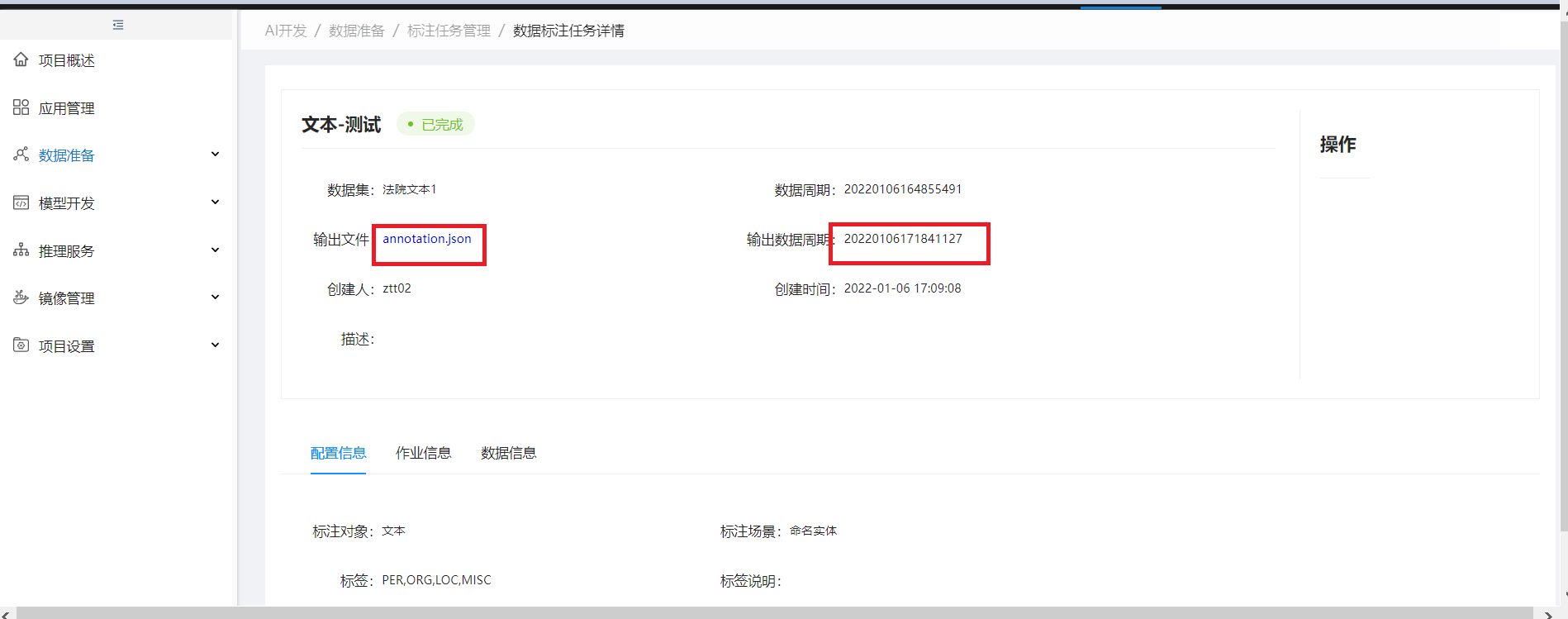
查看生成数据周期
步骤6:查看标注数据状态
标注任务点查看,切到数据信息页签,可查看标注状态,开始为:未标注、后面根据LabelStudio标注情况显示:已标注或无法标注

1.2.6.3 图片标注
操作步骤
步骤1:新增非结构化数据集,选择非结构分类为:图片
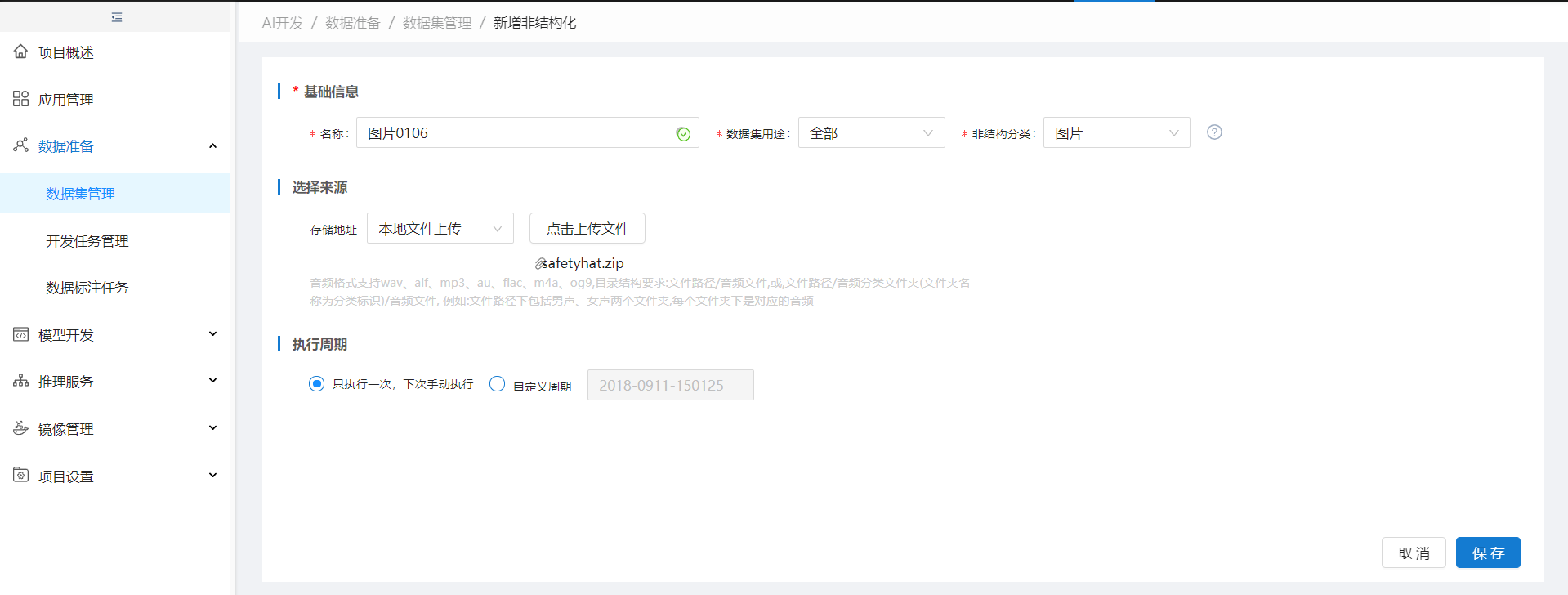
步骤2:创建标注任务,标注对象选择图片,其他与音频标注一致
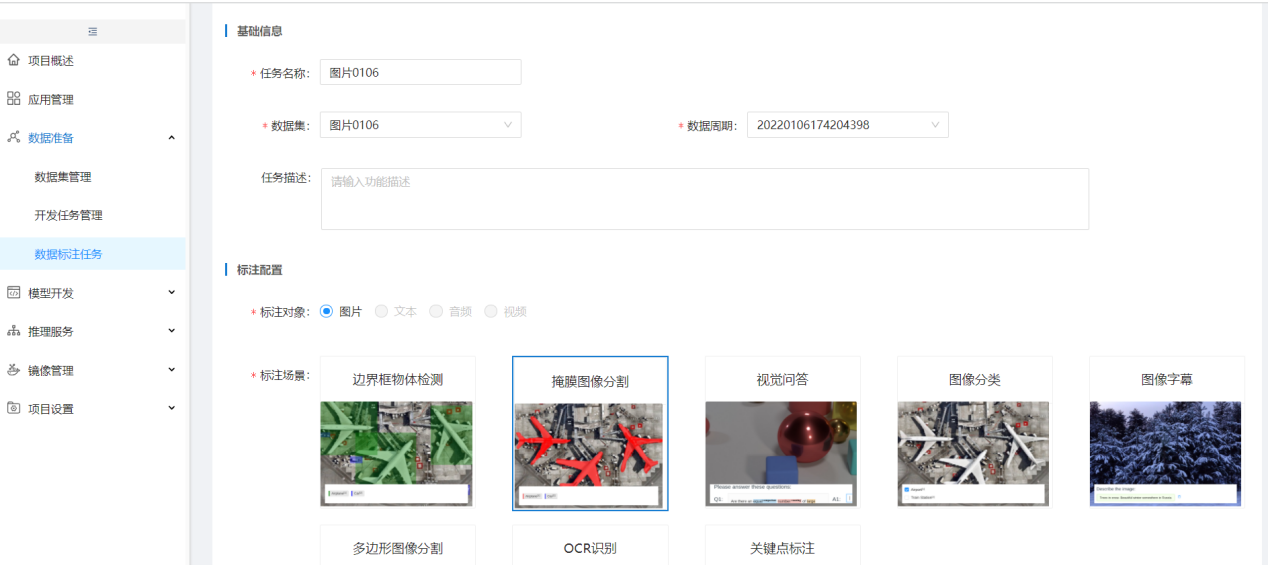
修改标签信息,选择标注人员
步骤3:标注人员登陆,进行数据标注
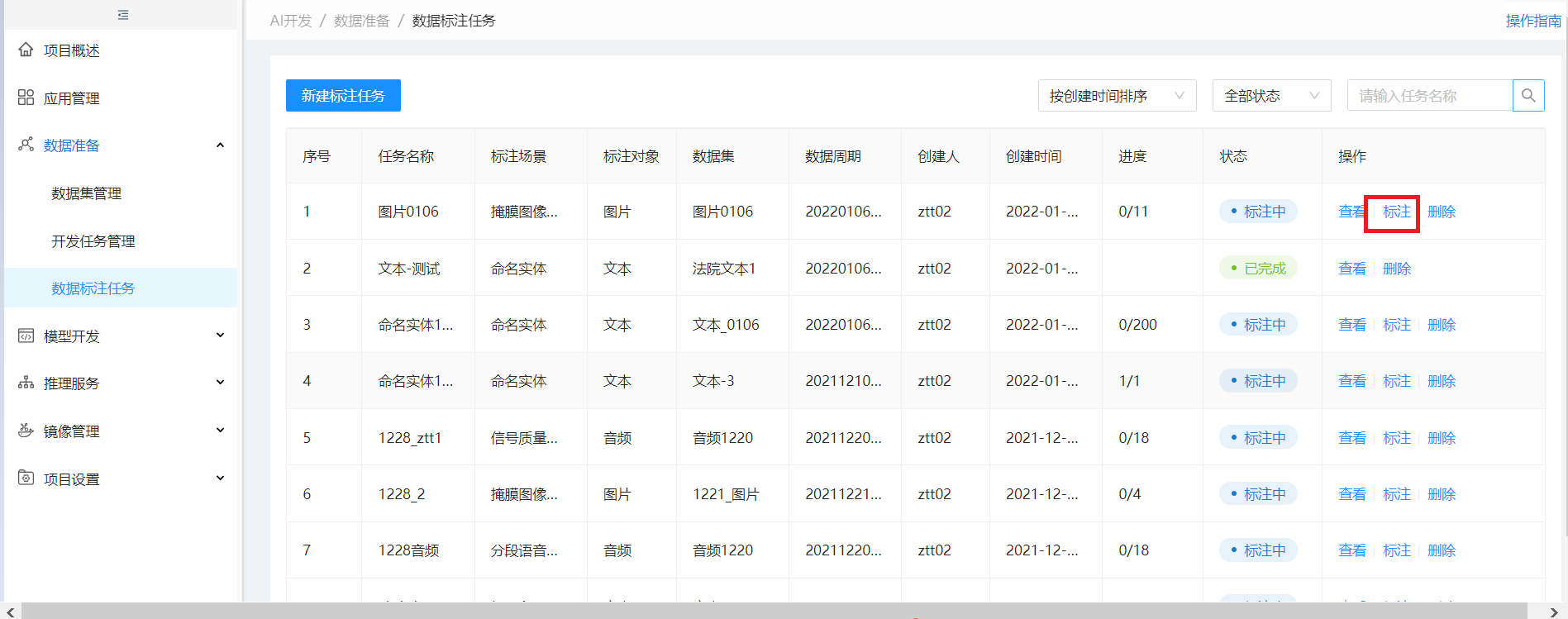
进入作业列表,点标注进入LabelStudio进行标注
LabelStudio标注,选中标签进行标注

标注完后提交,继续标注下一个文件

作业标注完后,点作业列表刷新按钮,若该作业进度为100%时,作业列表操作列出现发布按钮,点发布按可进行标注作业发布

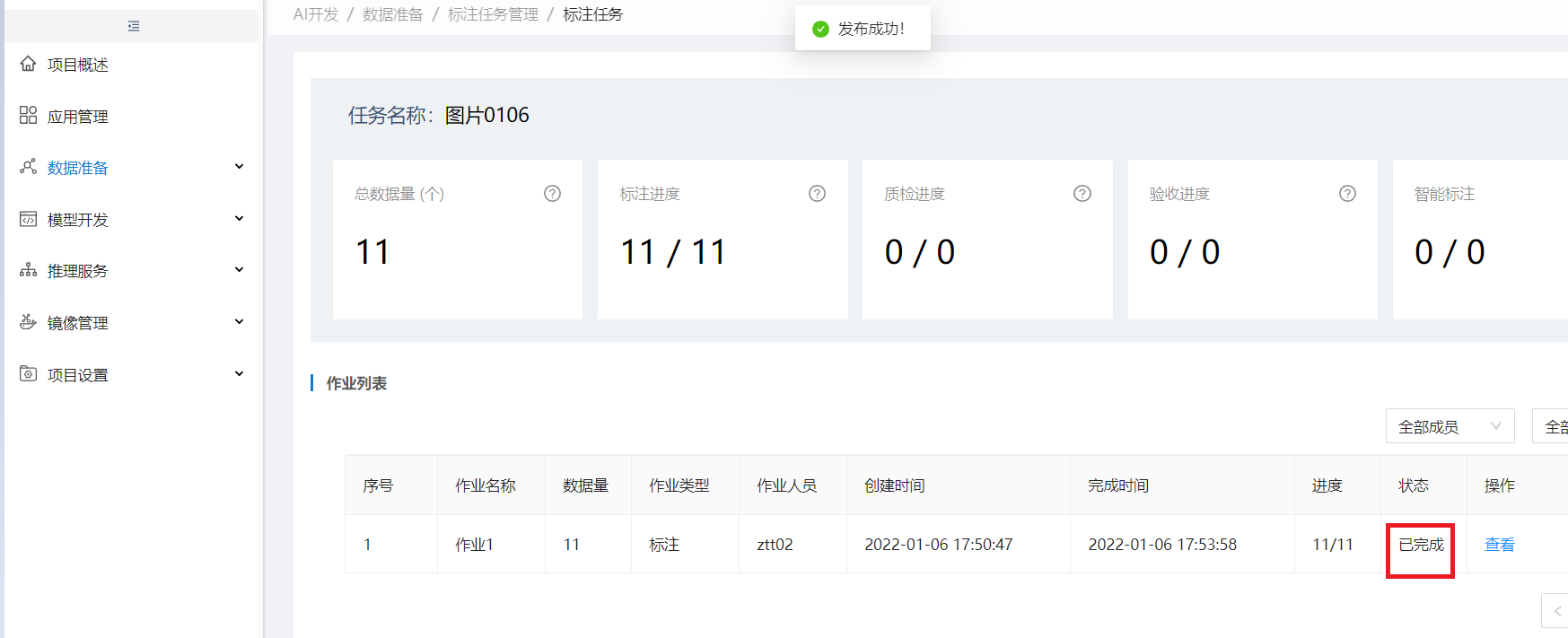
步骤4:发布标注任务
当该标注任务下的所有标注作业状态都为"已完成" 时,标注任务列表该任务状态为待发布,操作列出现发布按钮,点发布可发布该标注任务
发布后,该任务状态为已完成
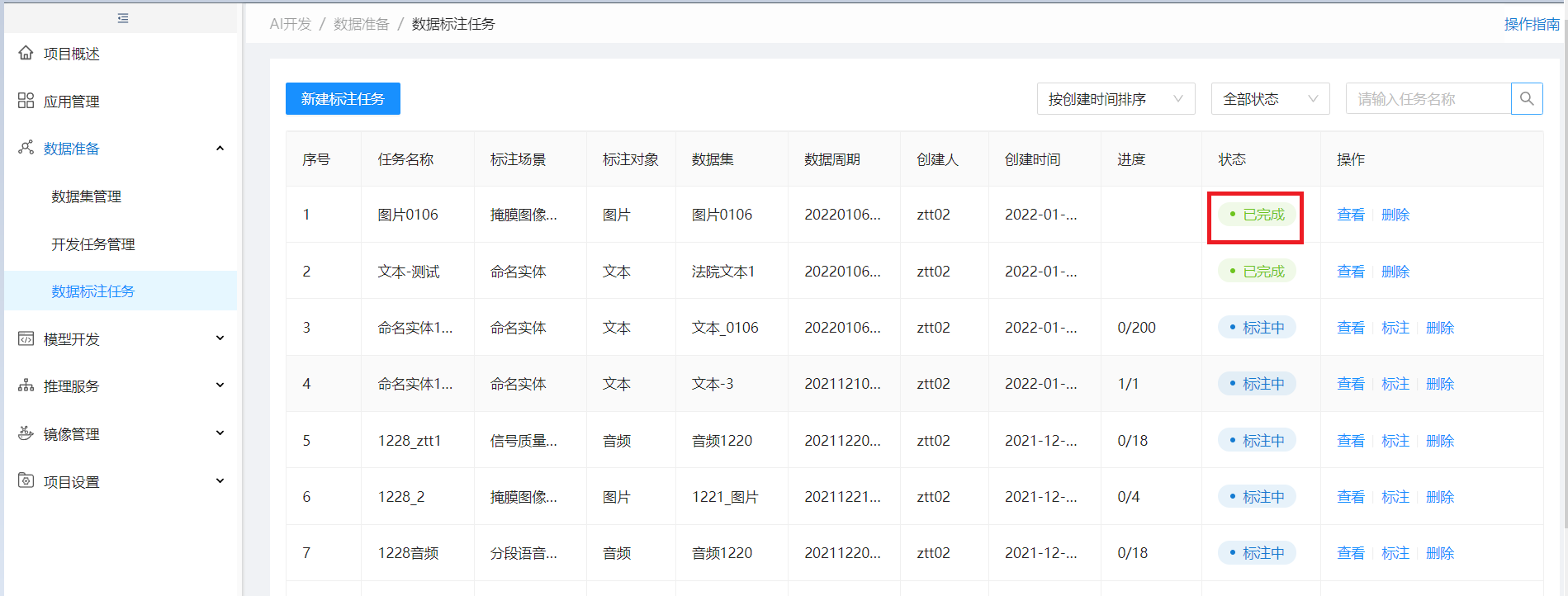
步骤5:下载标注输出文件
选择状态为已完成的标注任务,点查看

点击文件名称进行下载,输出文件默认删除无法标注数据;且生成新的周期数据
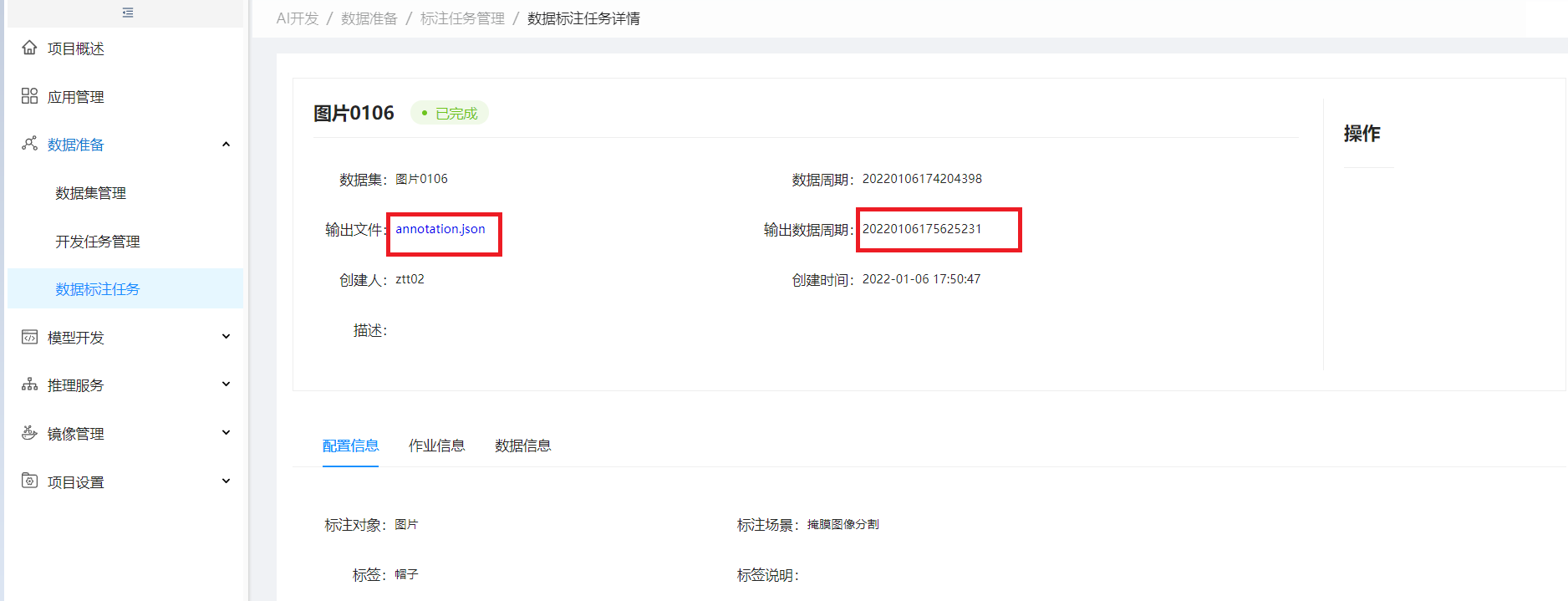
查看生成数据周期
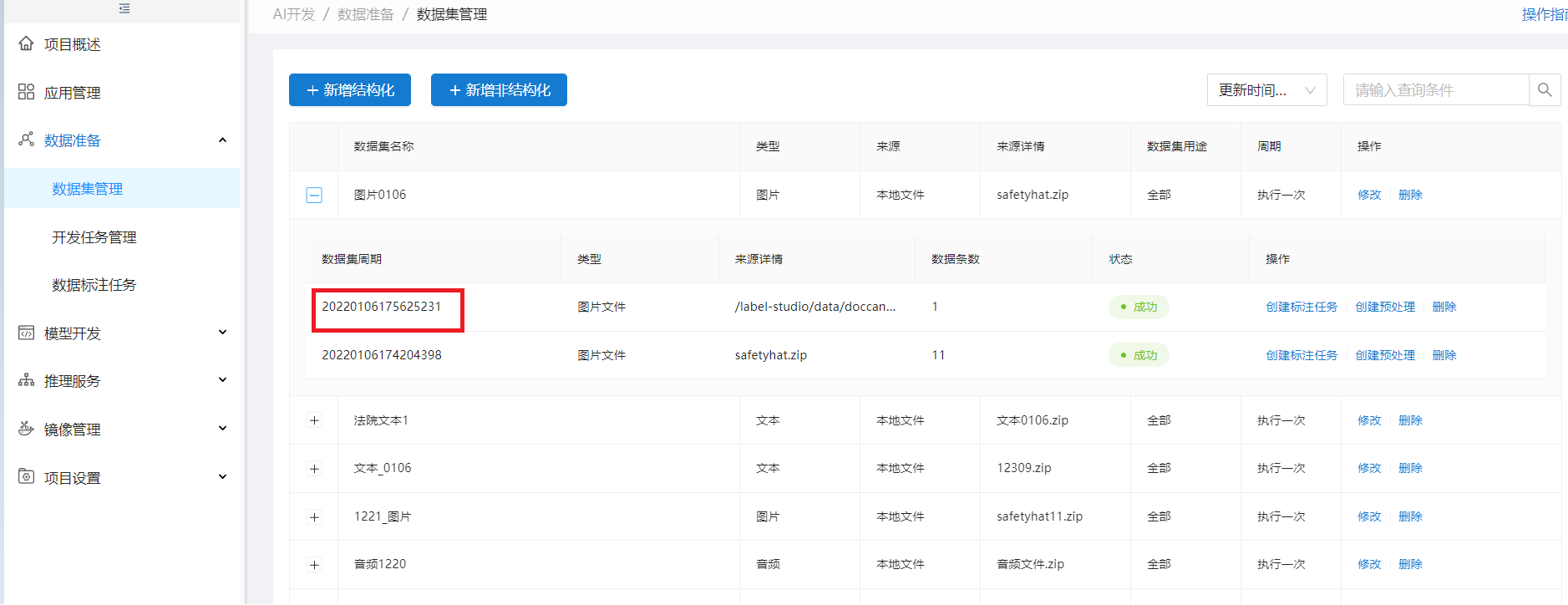
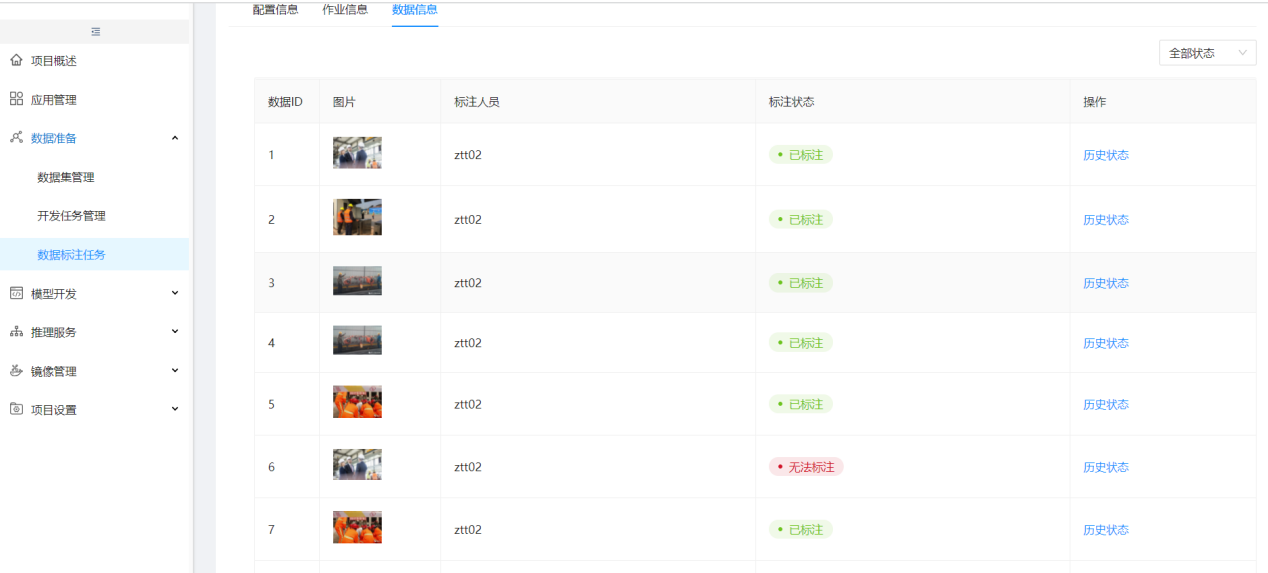
步骤6:查看标注数据状态
标注任务点查看,切到数据信息页签,可查看标注状态,开始为:未标注、后面根据LabelStudio标注情况显示:已标注或无法标注
1.2.7. 编码式建模
数据准备好后,用户可在【编码式建模】中点击"新增编码服务"创建应用的个人编码服务:

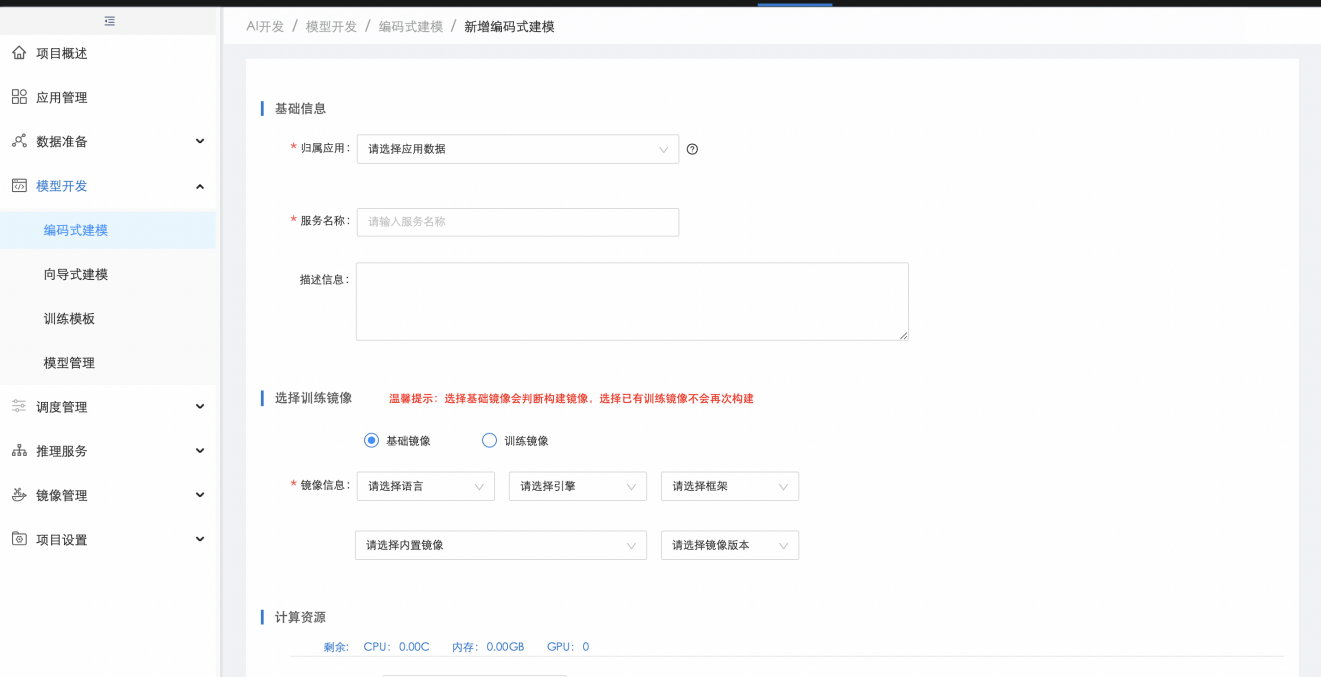
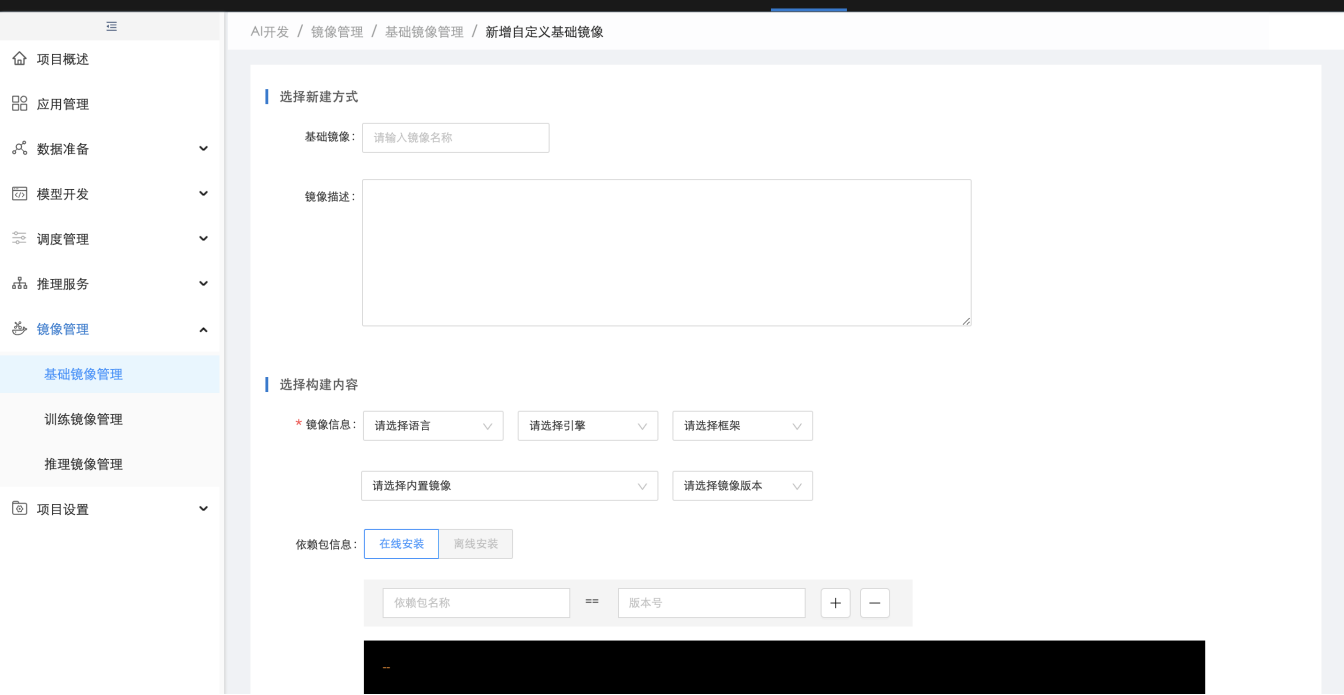
创建编码服务时,用户可选择基础镜像或训练镜像,基础镜像为仅包含语言、框架等的基础环境,训练镜像为包含语言、框架、在线编码工具Jupyterlab以及一些使用广泛的算法依赖包等的训练环境,当训练镜像不满足用户环境需求时,用户可在【基础镜像】中,基于预置基础镜像自定义安装依赖包生成新的自定义基础镜像供创建编码服务时选择,选择基础镜像并创建编码服务后,系统会将基础镜像加入Jupyterlab编码工具自动生成相应训练镜像:
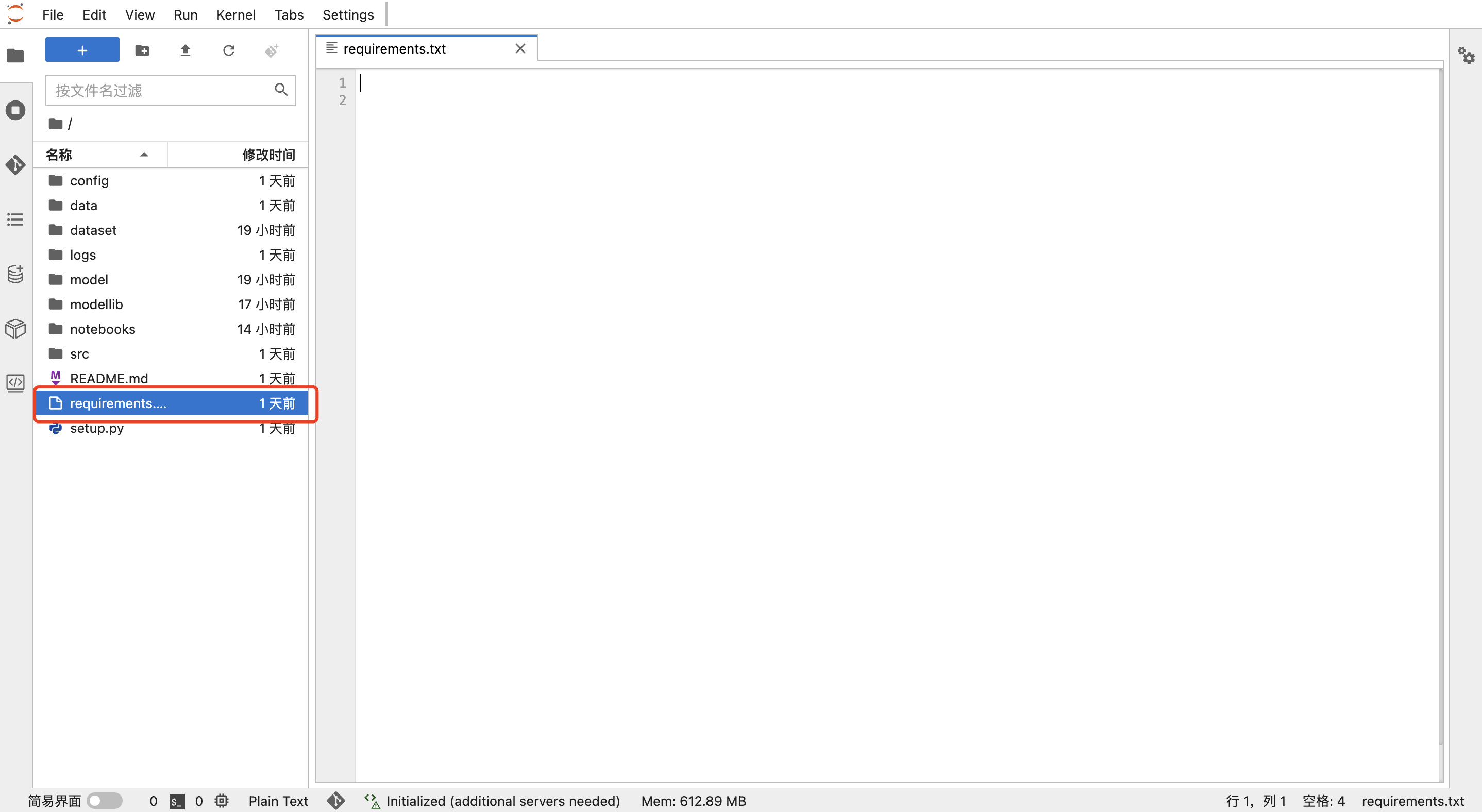
已经创建了编码服务后,若训练环境不满足用户环境需求时,用户可在【Jupyterlab】中,使用requriements自定义添加依赖包,然后重启编码服务即可:
创建编码服务后,等待编码服务启动,启动后可点击"编码"进入【Jupyterlab】进行编码开发,用户仅能对自己创建的编码服务进行编码,无法对其他用户的编码服务进行编码操作:

编码时,用户可使用文件浏览器查看应用个人开发目录,并对目录文件进行编辑及新建、上传等管理操作等,编辑notebook文件,可以使用编辑栏或右键对cell的进行各项操作:
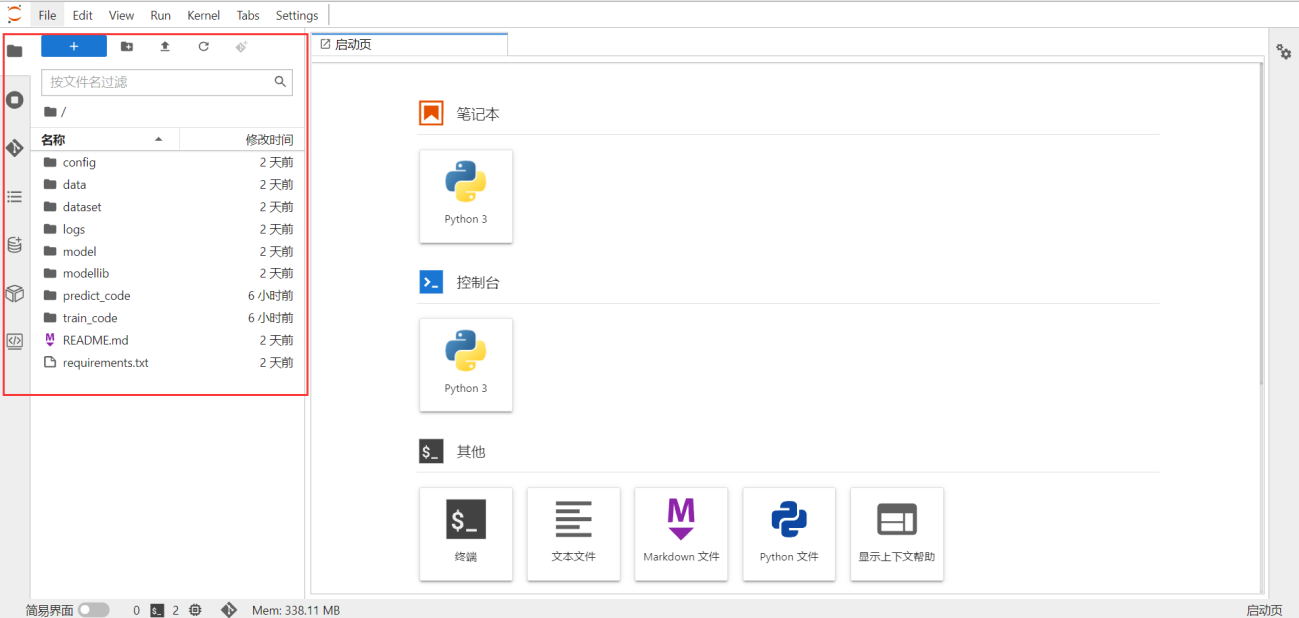
编码时,可选择内置模板新建notebook文件进行训练代码、向导训练模板代码或预测代码的参考编写:

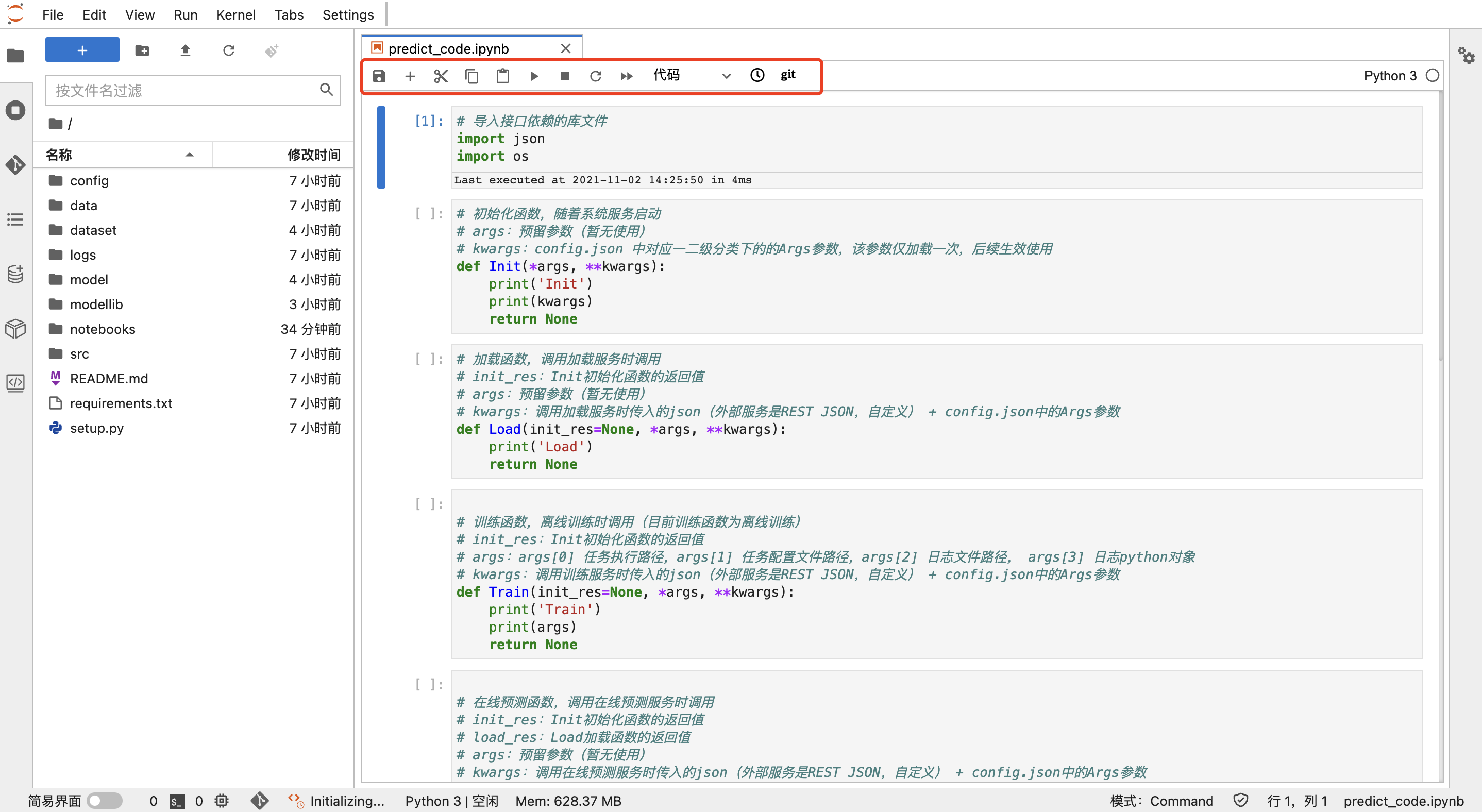
编码时,用户可使用运行文件监控管理打开的标签页及运行中的内核、终端等:
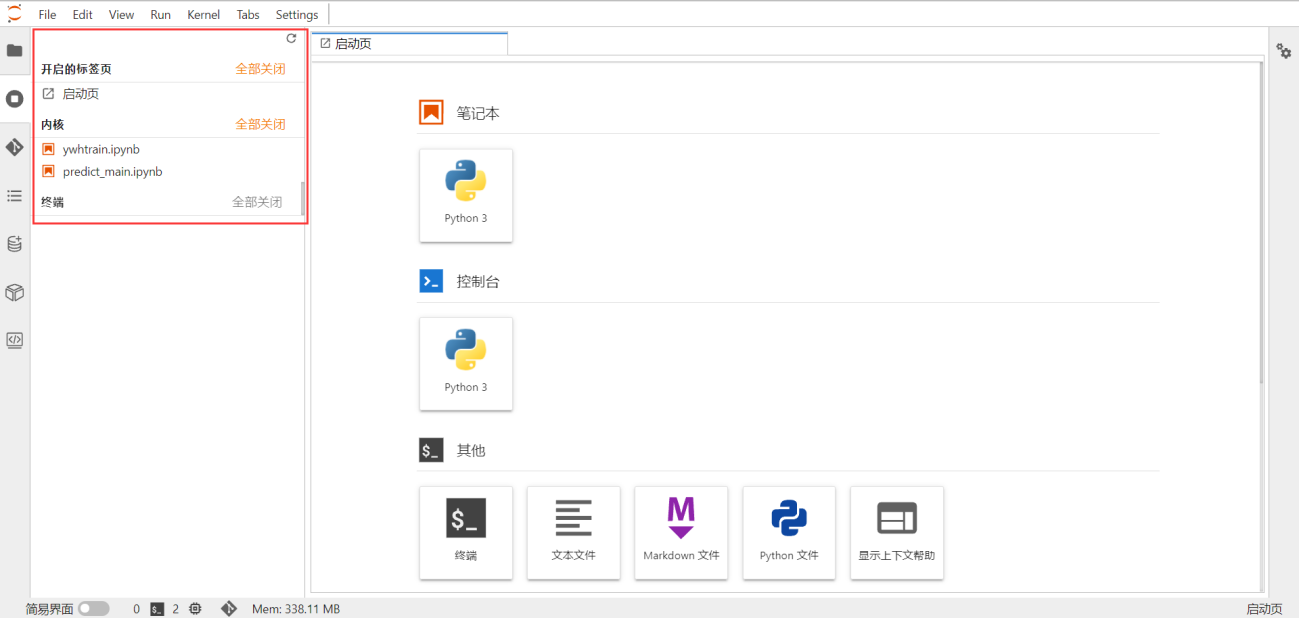
编码时,用户可以利用markdown来创建文件标题目录,以便快速定位到文件标题处:

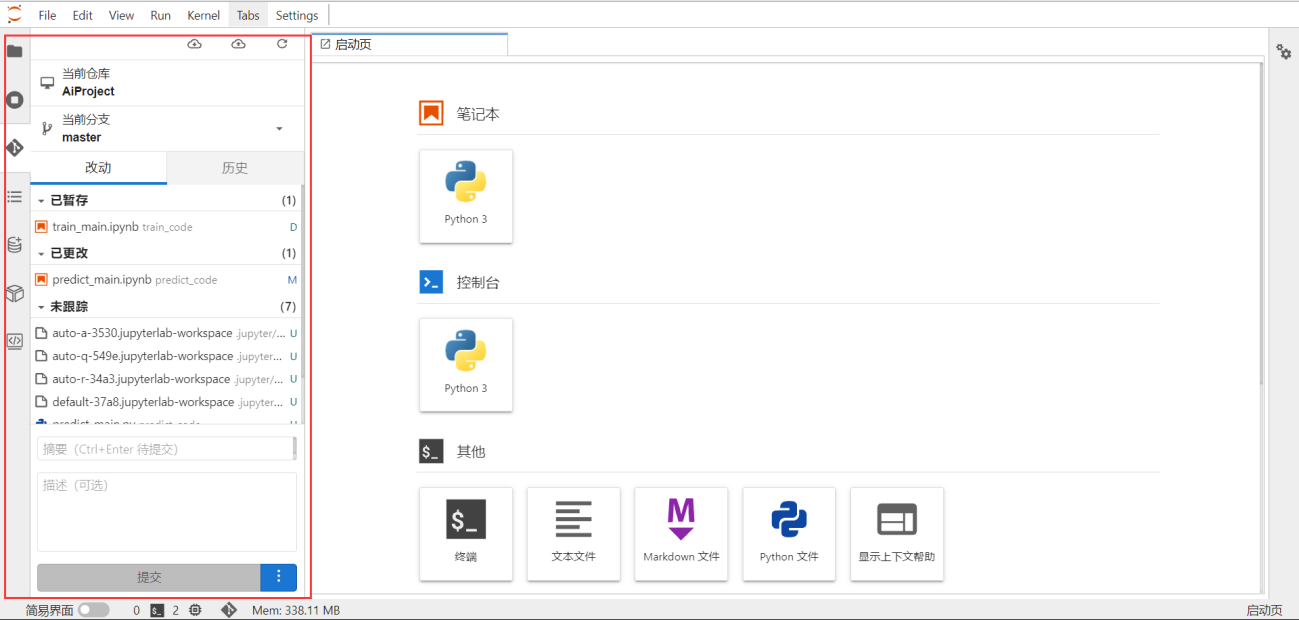
编码时,对接了Git仓库,用户可以将应用的个人代码提交到Git对应的应用下进行代码合并、管理等:
编码时,用户可查看与应用绑定的数据集及数据周期,对结构化数据可插入数据周期引用代码到文件中进行引用,对非结构化数据可加载数据周期到开发目录中并进行路径复制引用:
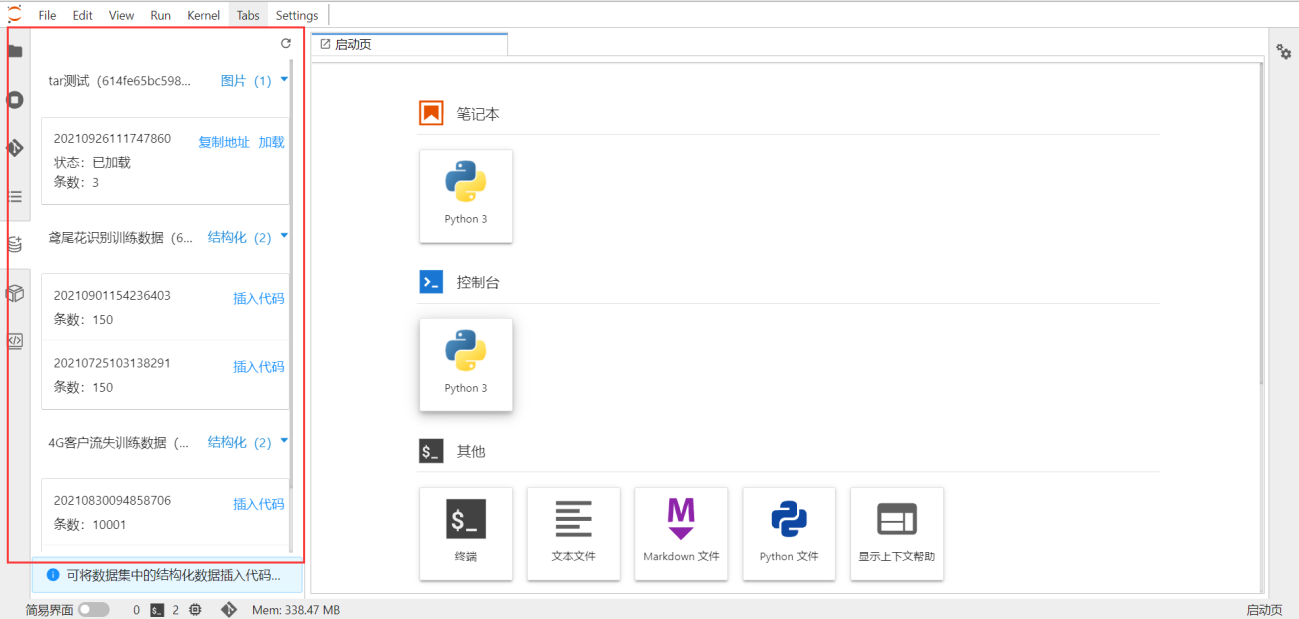
编码时,用户可查看应用已发布的模型,并可将模型加载到开发目录中进行路径复制引用:

编写训练代码后,运行代码进行模型训练,在训练完成并输出模型文件后,用户可将输出的模型发布到【模型管理】:
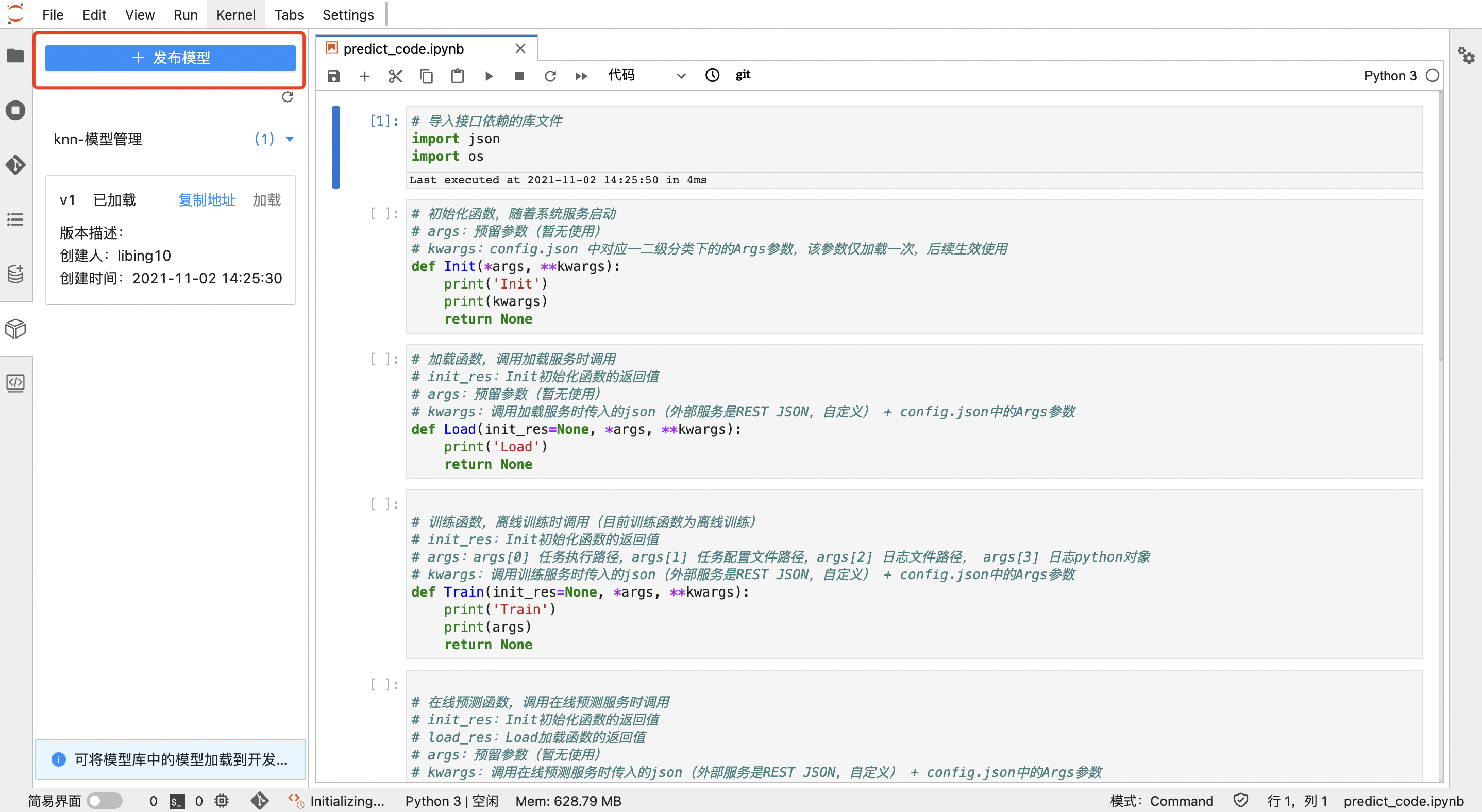
发布模型后,编写预测代码,用户可将预测代码发布到相应模型上,预测代码发布后,在【模型管理】中系统会自动生成模型和接口的可部署代码包,以便后续在线或离线推理部署
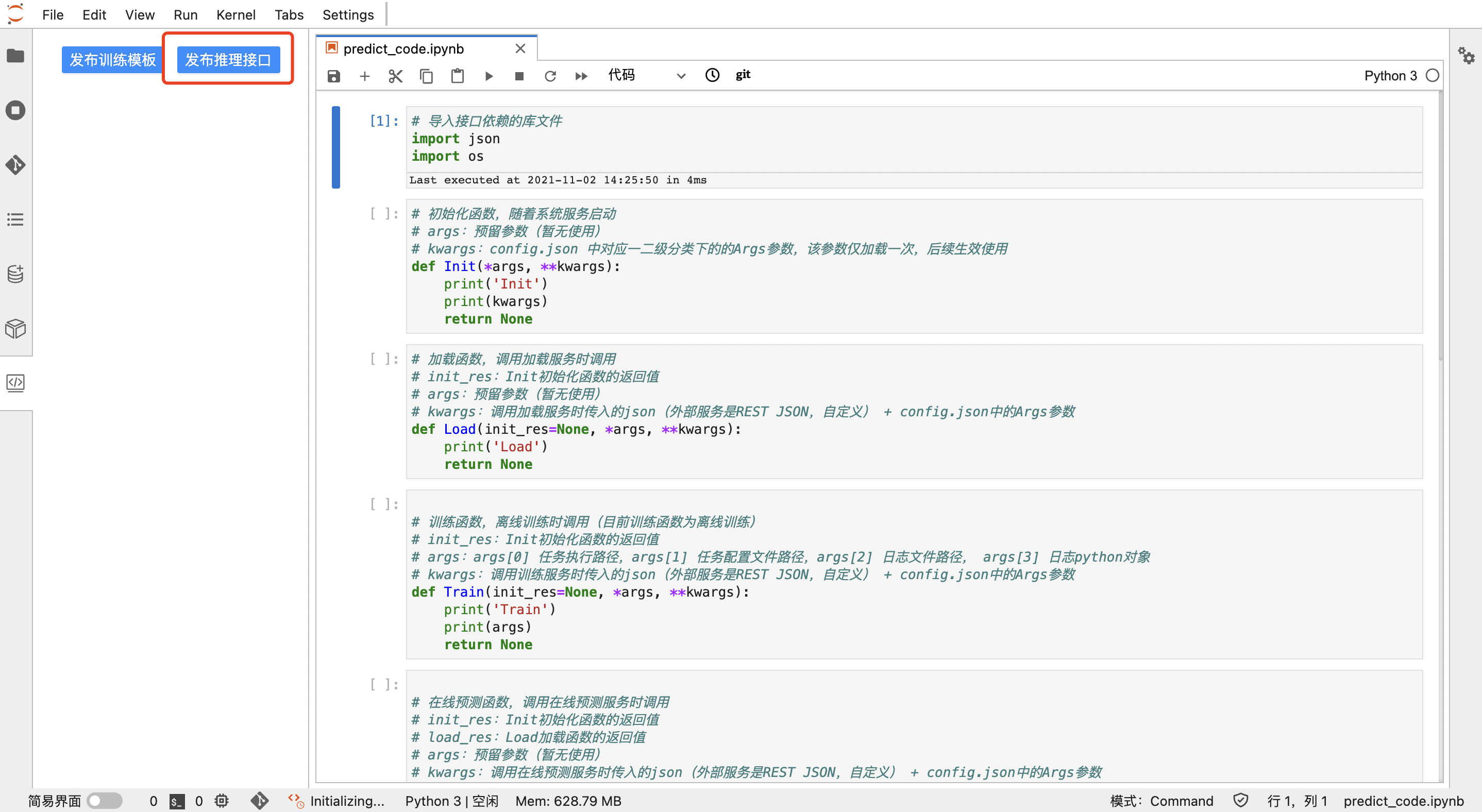

编写训练代码后,用户可将训练代码调整为训练模板代码,发布成向导训练模板到【训练模板】中,同时编写训练模板输出模型的预测代码,并将预测代码发布到相应向导训练模板上,以便后续向导式建模使用:
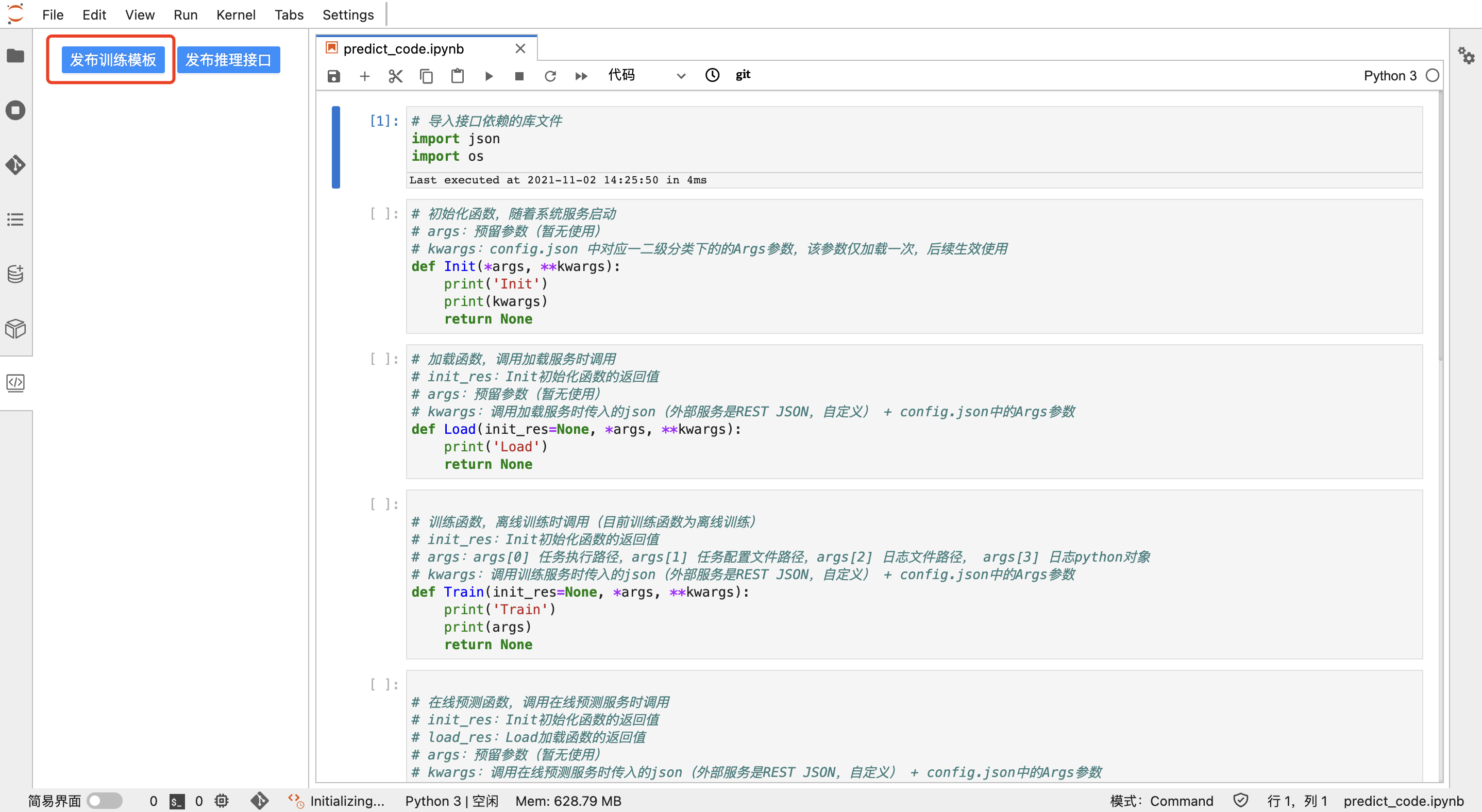


1.2.8. 模型管理
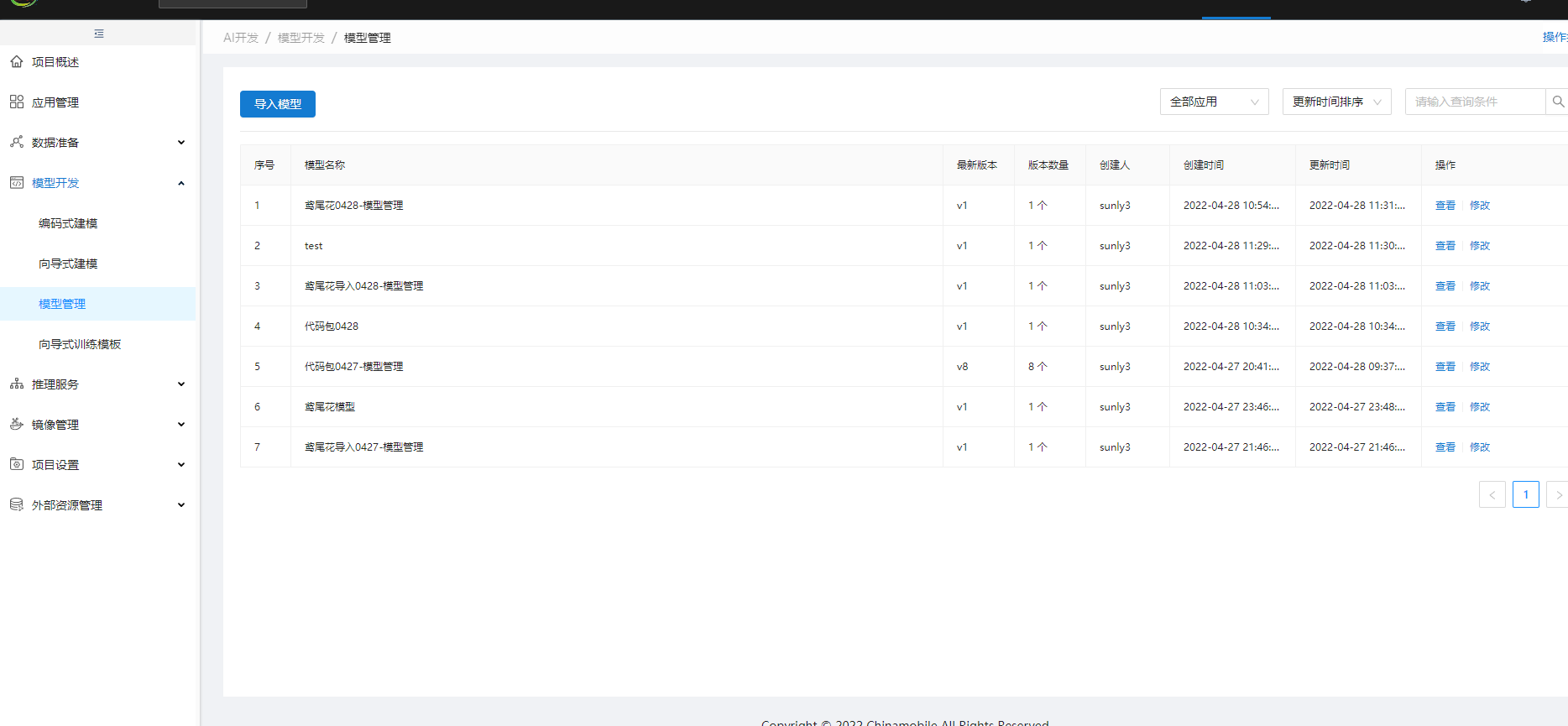
整个模型展示列表,包括编码建模保存的模型、第三方导入的模型。

编码保存的模型可以在模型管理看到,同样也可支持从外部导入模型。
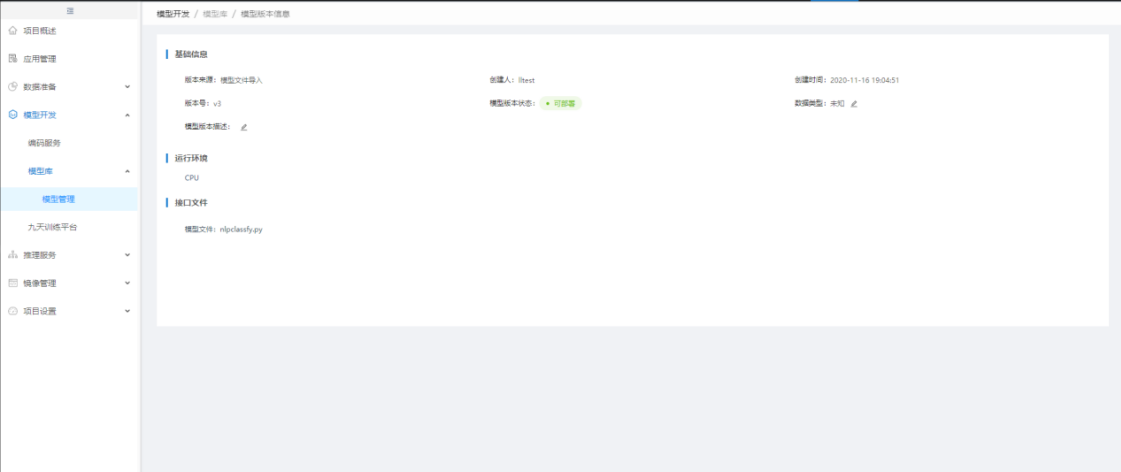
第三方模型可导入。(可选)
1.2.9. 向导式建模
使用向导式建模前,需要有向导式训练模板,用户可以使用【编码式建模】自定义编写向导式训练模板及输出模型接口并进行发布,发布后,在【训练模板】中将模板"上线":
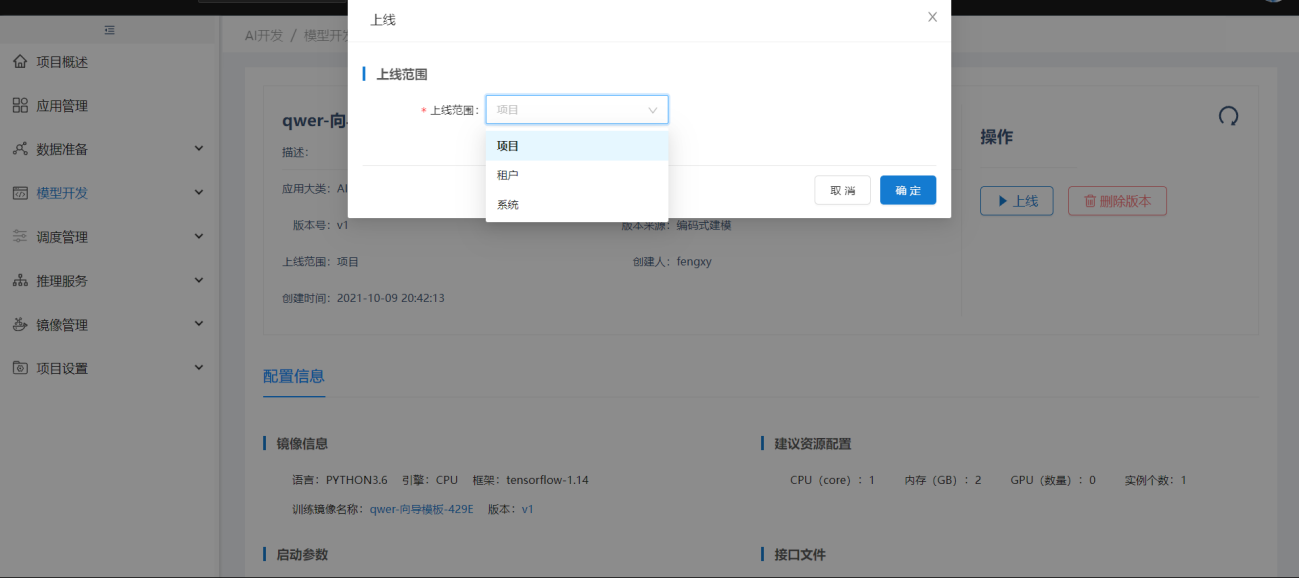
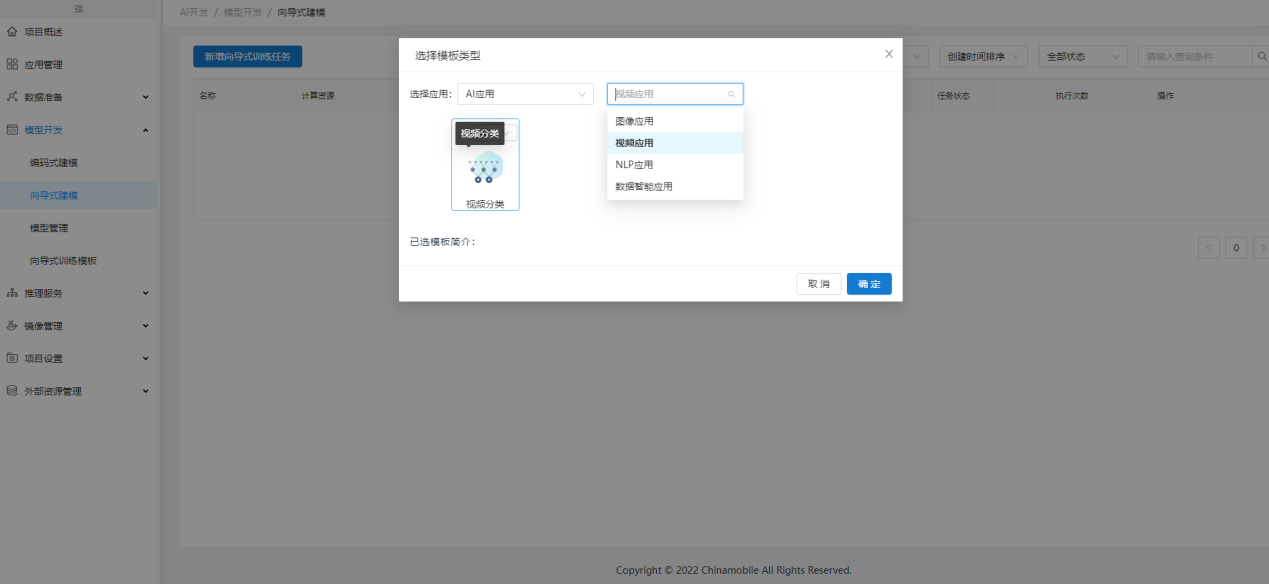
向导模板准备好后(如果系统预置了向导式训练模板,用户也可以直接使用预置的向导模板进行向导式建模),用户可在【向导式建模】中点击"新增向导任务",选择上线或预置的向导模板,创建应用的向导训练任务并"立即执行":

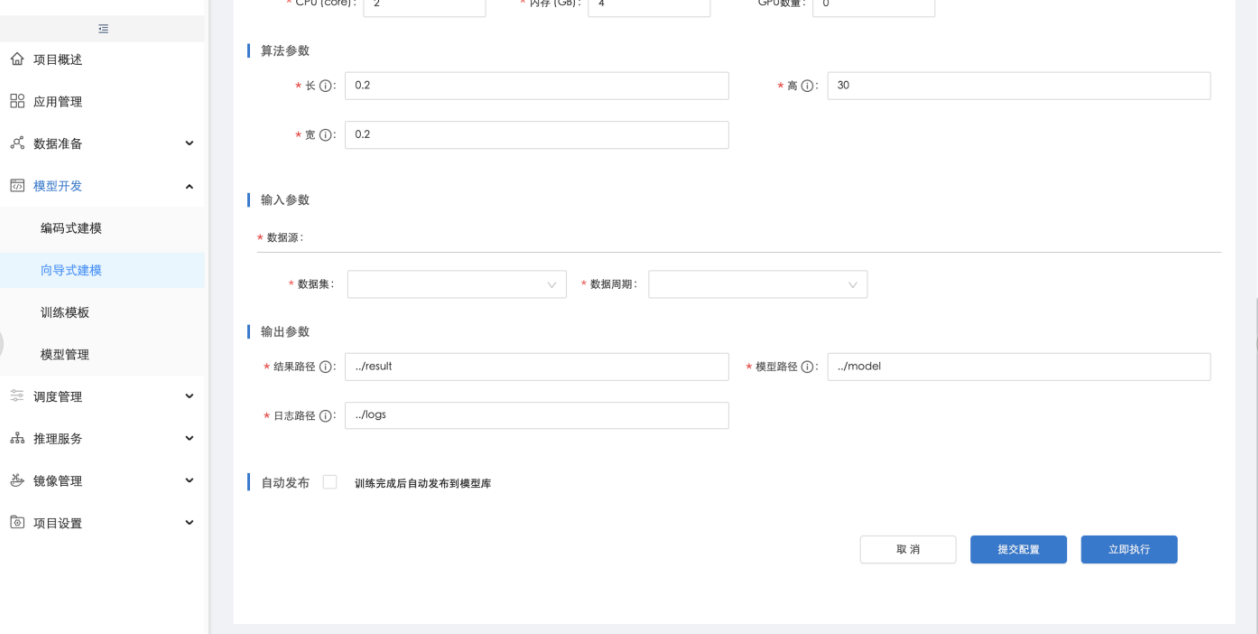
执行完成向导训练任务后,如果在新建任务时选择了自动发布,则训练完成后会自动发布模型及推理接口到【模型库】,如果新建任务时未选择自动发布,则可在【向导式训练任务详情】的"执行任务"标签页,查看执行的任务,并在执行完成后,点击操作栏的"发布模型",将模型及推理接口手动发布到【模型管理】,发布后,在【模型管理】中系统会自动生成模型和接口的可部署代码包,以便后续在线或离线推理部署:
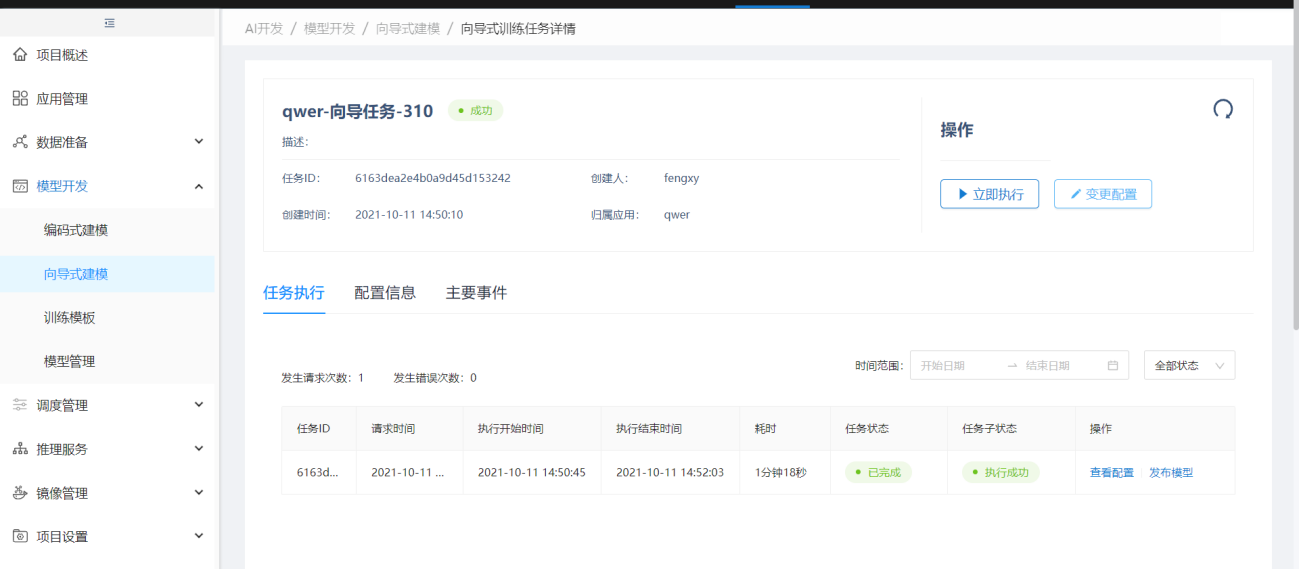
执行完一次训练任务后,在【向导式训练任务详情】中点击"立即执行"可修改调整参数,进行多次执行:

1.2.10. 第三方模型导入
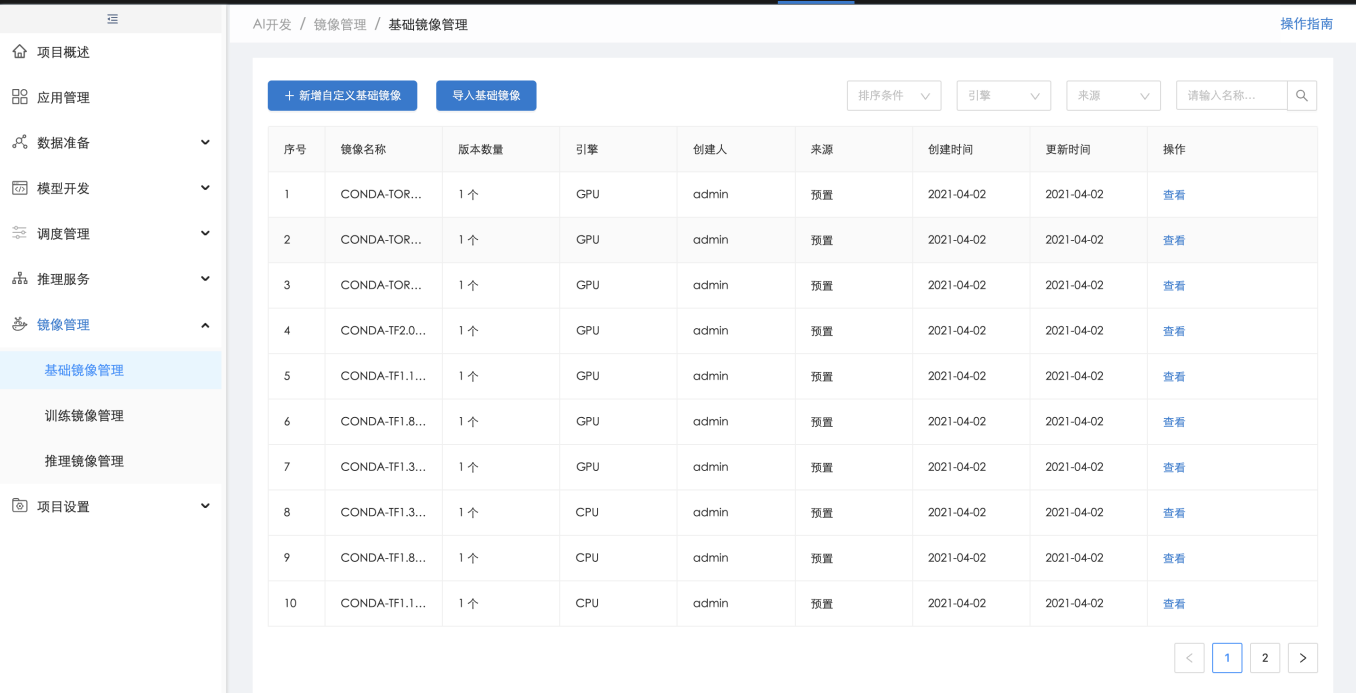
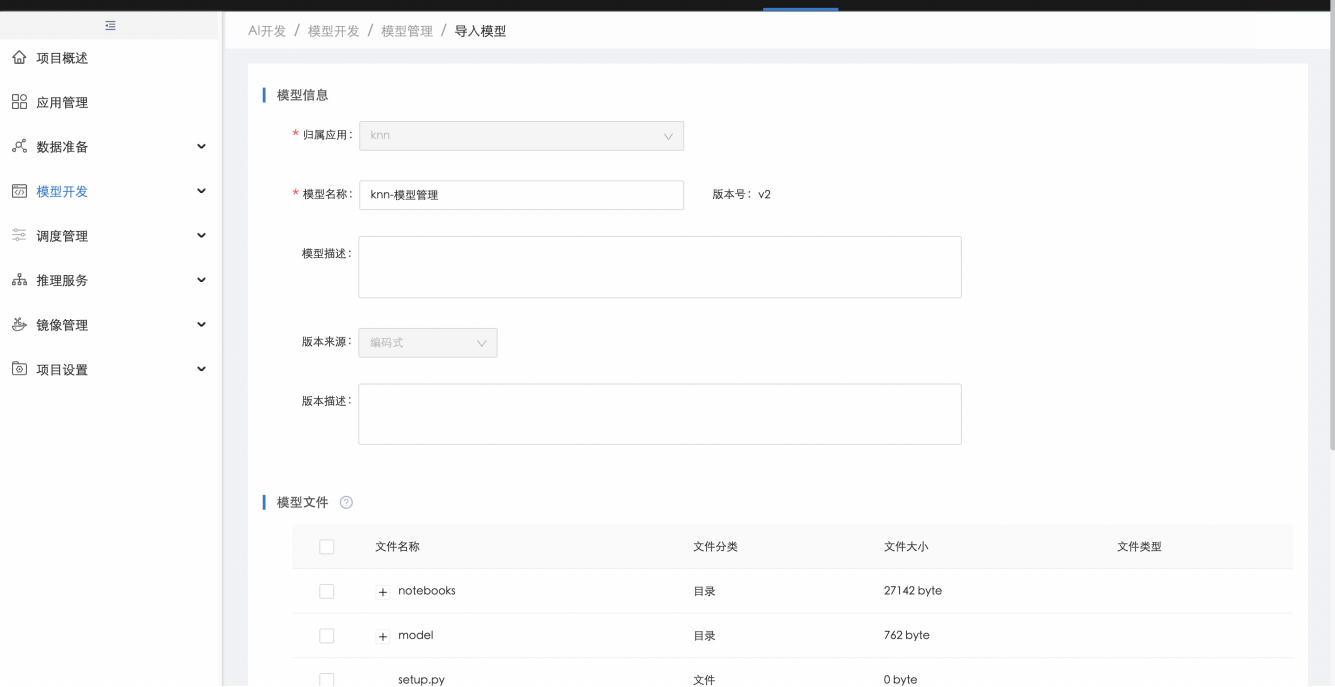
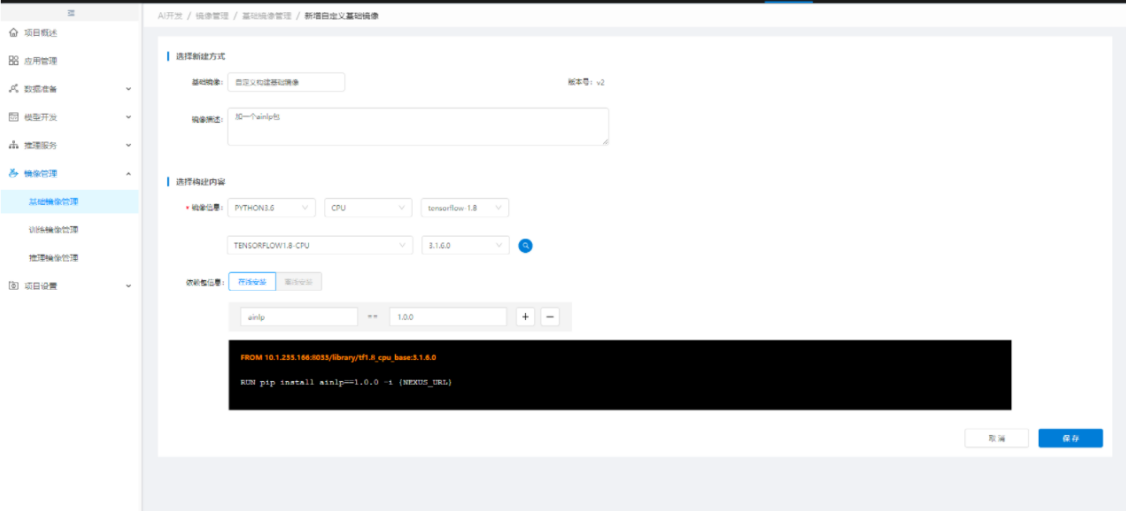
在【模型管理】中,用户可点击"导入模型"导入第三方平台训练的模型,导入时,需选择模型的运行环境,即含有语言、框架及计算引擎的基础镜像,如果模型还有其他依赖,需在【基础镜像管理】中进行"新增自定义基础镜像",自定义安装依赖包并生成新的基础镜像供导入模型时选择:
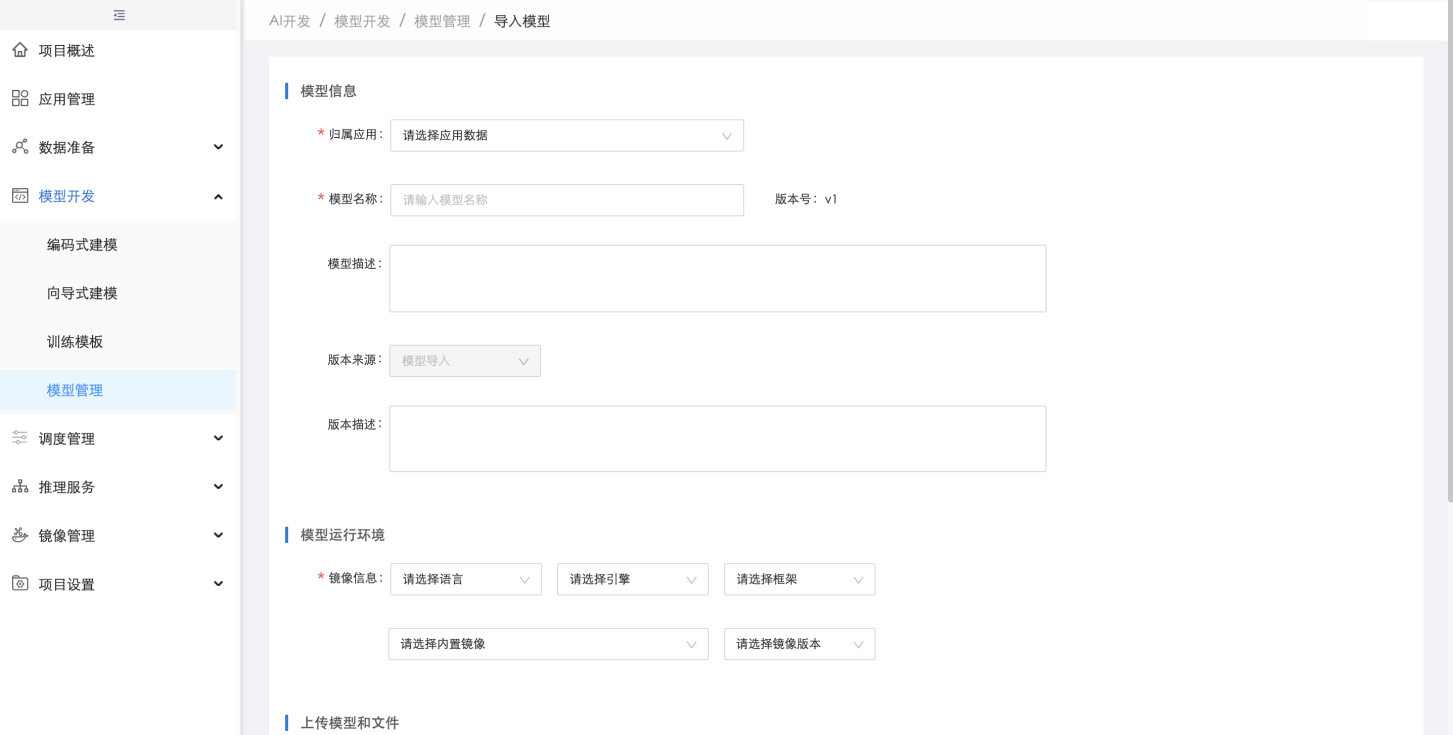
导入模型时,若导入格式为"文件"且导入了模型及推理接口,则导入后系统会自动生成可部署代码包,若导入格式为"代码包",则导入后系统直接生成可部署代码包:
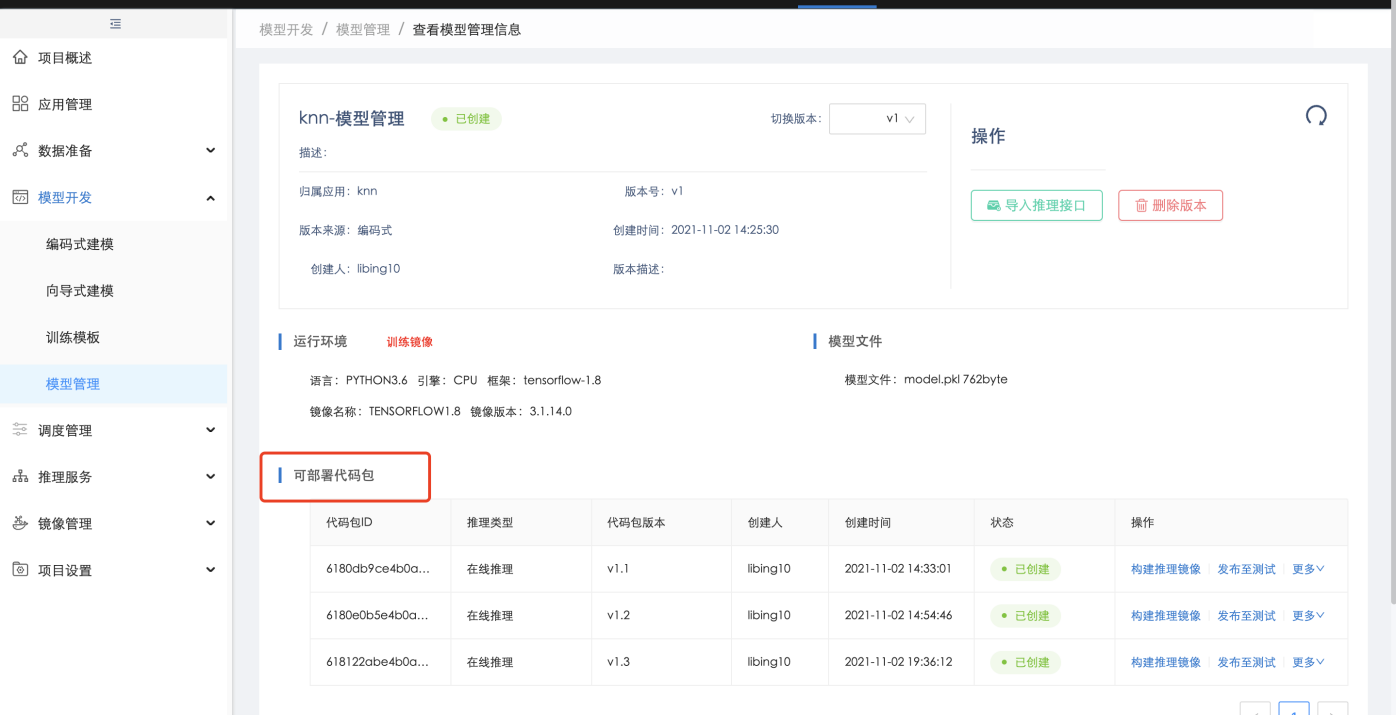
导入或发布模型后,可将模型在线推理类型的可部署代码包手动构建为在线推理服务镜像,构建后可在【推理镜像管理】中查看:

1.2.11. 第三方服务镜像导入
在【推理镜像管理】中,用户可点击"导入服务镜像"导入第三方平台构建好的模型在线推理服务镜像:


用户也可将【模型管理】中的在线推理类型的可部署代码包构建成推理镜像:
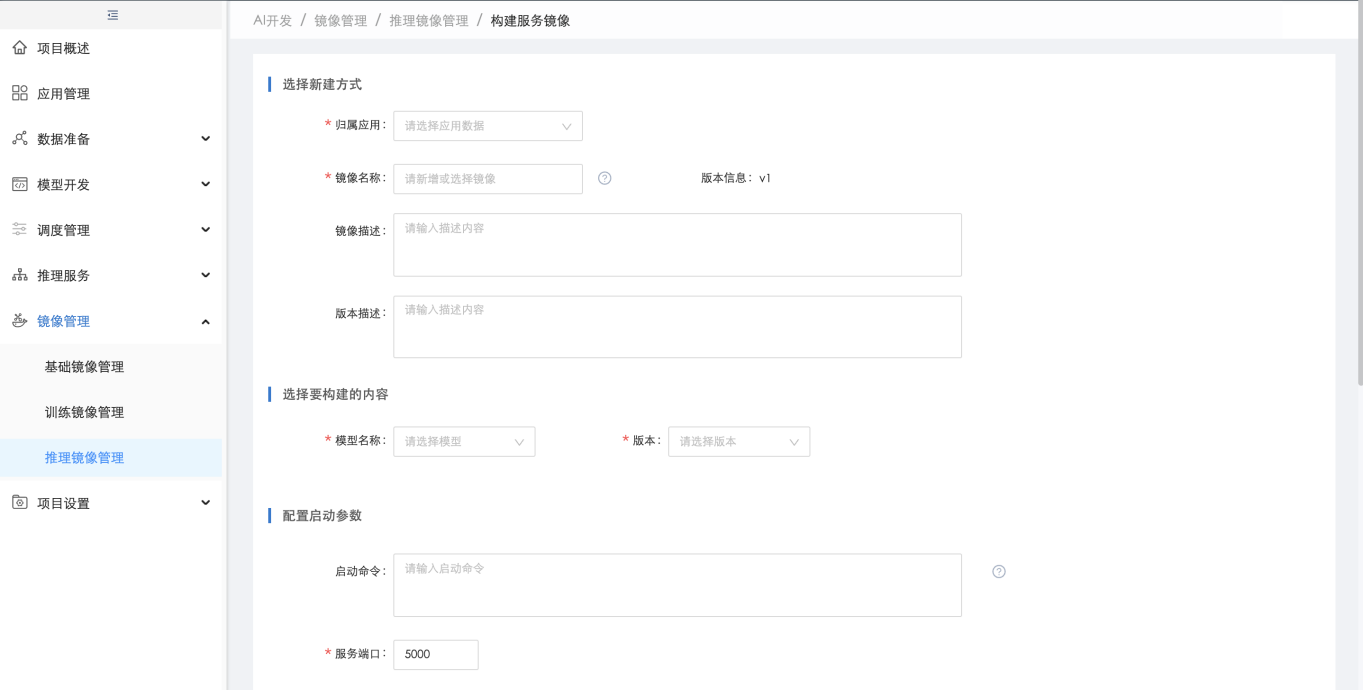
1.2.12. 部署在线推理服务
用户进入推理服务,可选择按模型/按代码包/按推理镜像进行服务部署,先部署在测试集群,再部署在生产集群。

模型及接口发布或导入后,用户可在【模型详情】中选择"在线推理"类型的可部署代码包,点击"发布至测试"或"发布至生产"部署在线推理到测试环境或生产环境,部署时系统会自动将代码包构建成在线推理服务镜像:

用户也可以在【推理镜像管理详情】中点击"发布至测试""发布至生产"直接将在线推理服务镜像部署为在线推理服务到测试环境或生产环境:

用户还可以直接在【在线推理服务】中选择测试或生产环境,点击"新增在线推理",将模型或在线推理服务镜像部署成在线推理服务:
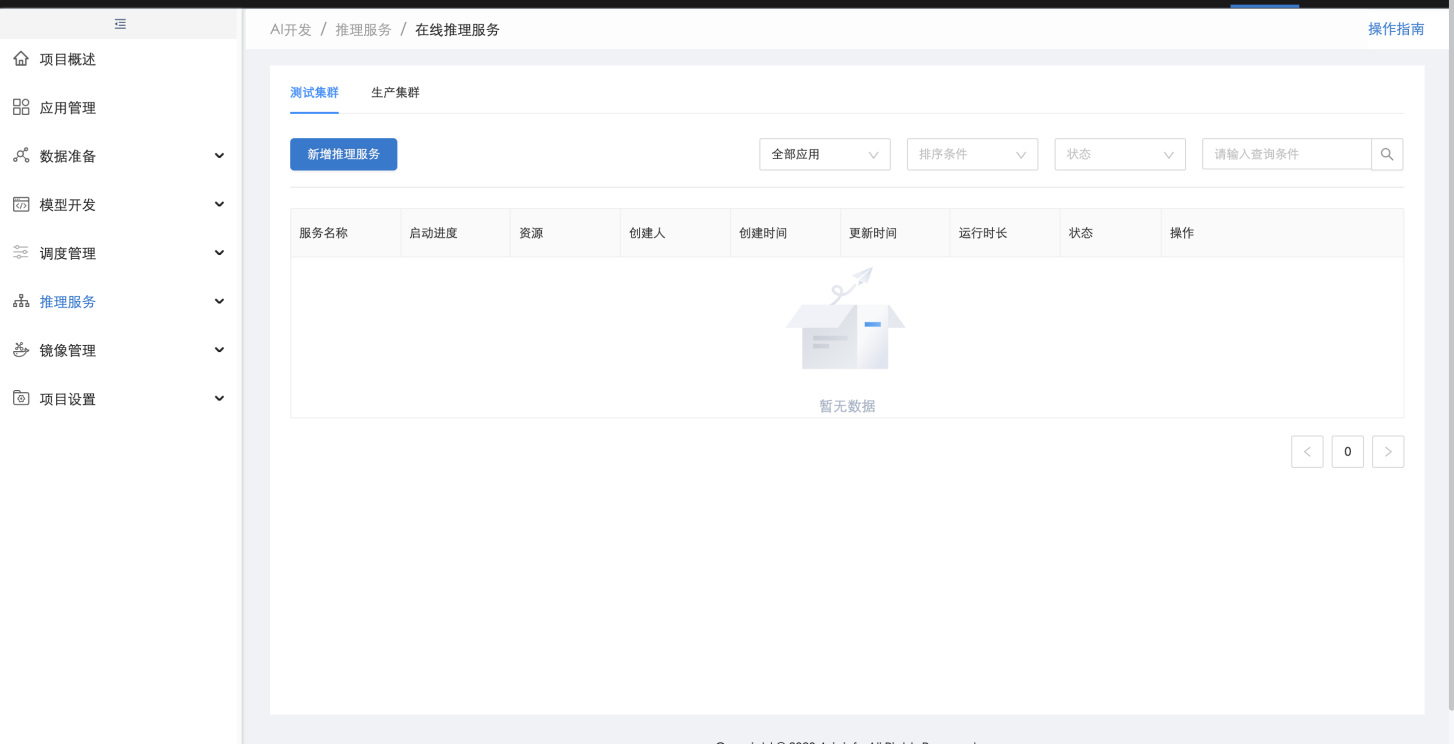

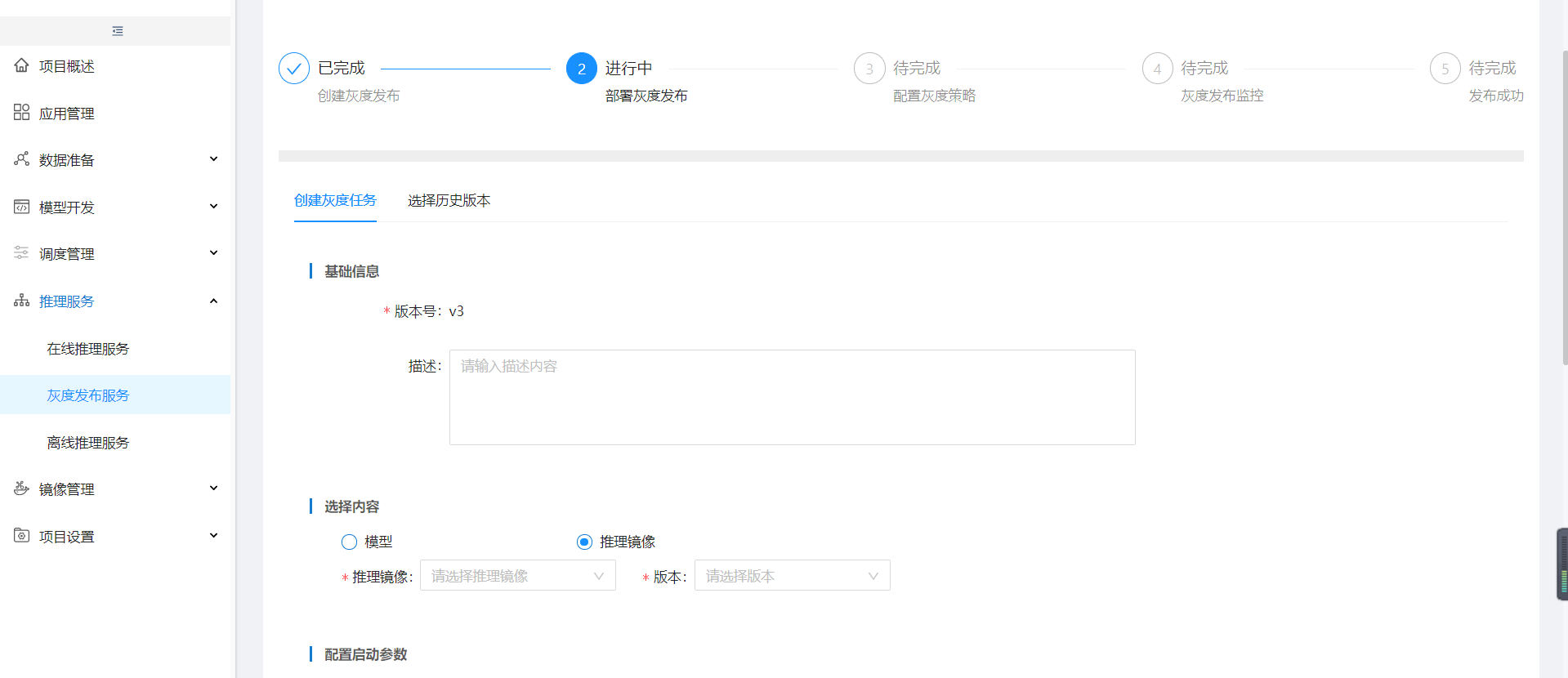
1.2.13. 部署灰度任务
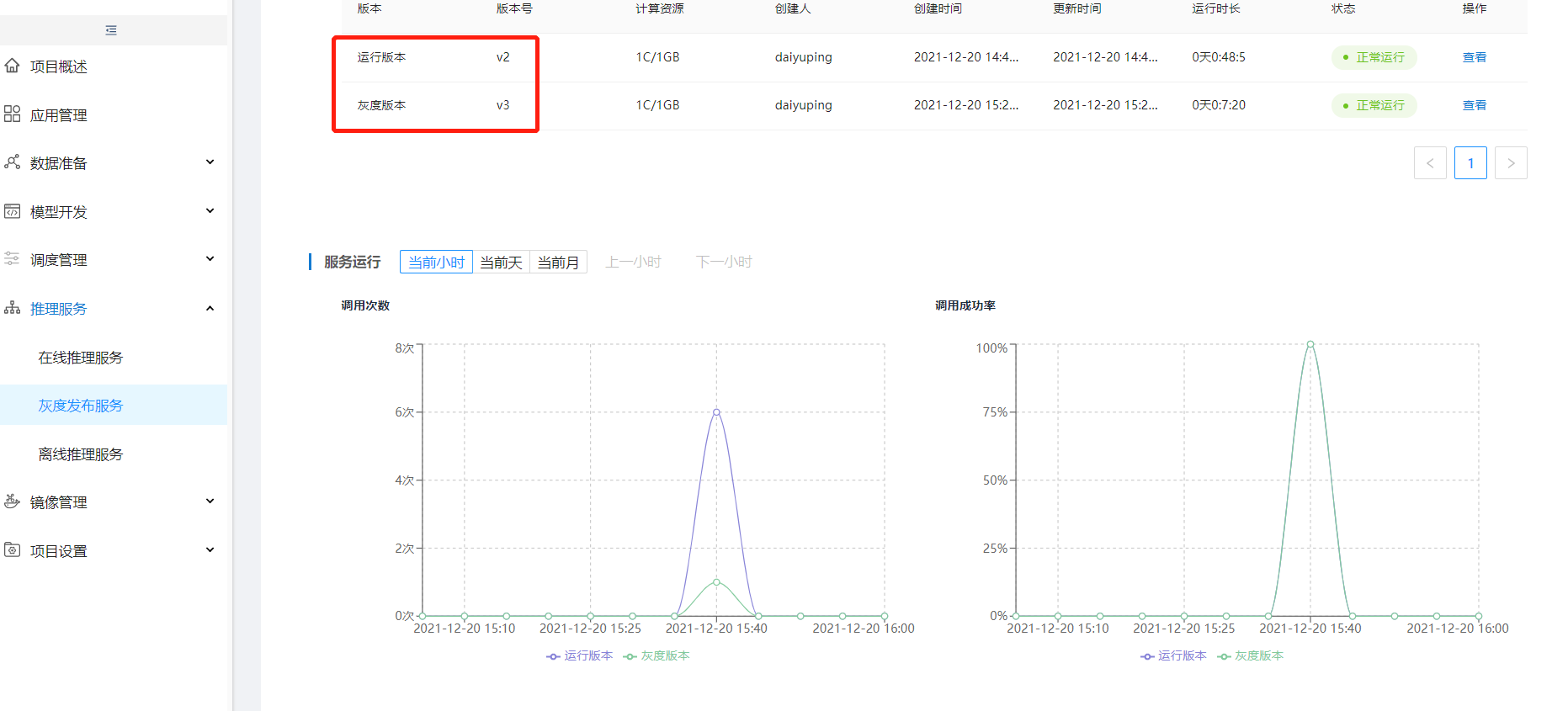
在线推理服务创建成功后可以在【灰度发布服务】中新增灰度任务,灰度任务根据不同环境创建会在选择的环境下显示新增的灰度,且创建时也只能选择该环境下运行的在线推理服务。
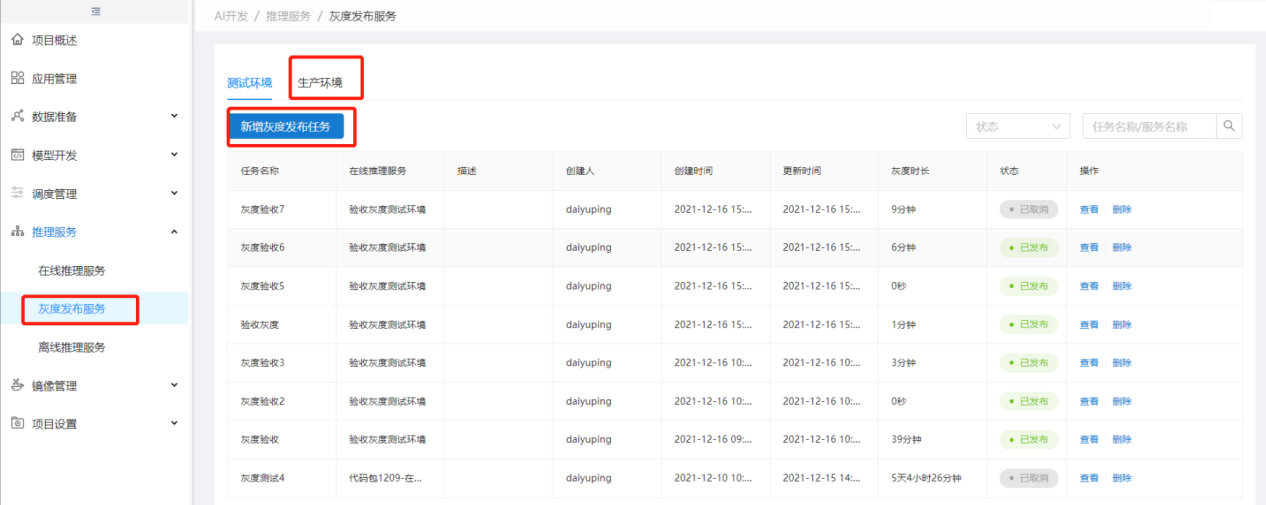
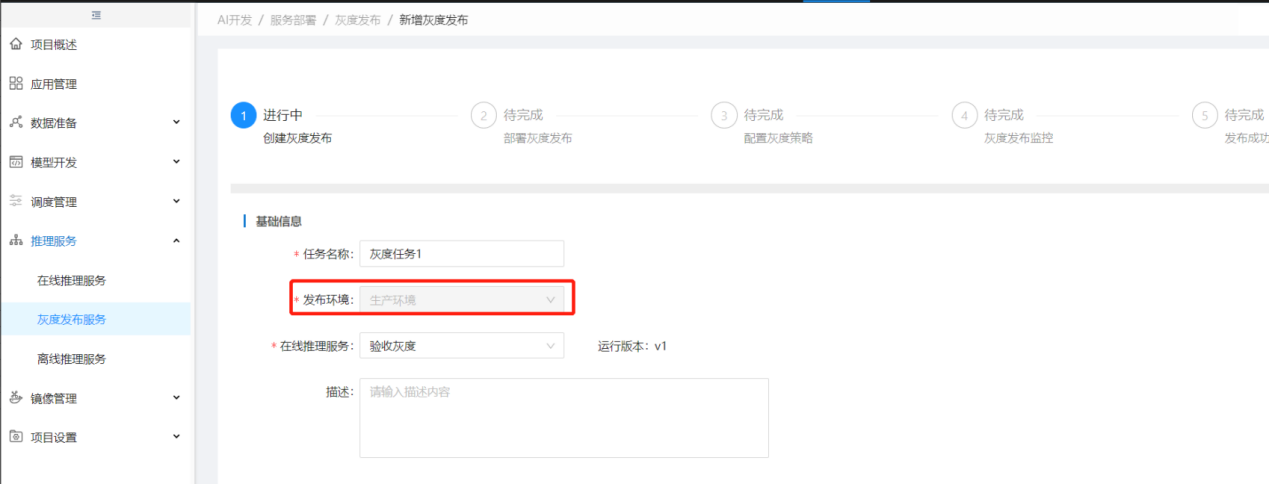
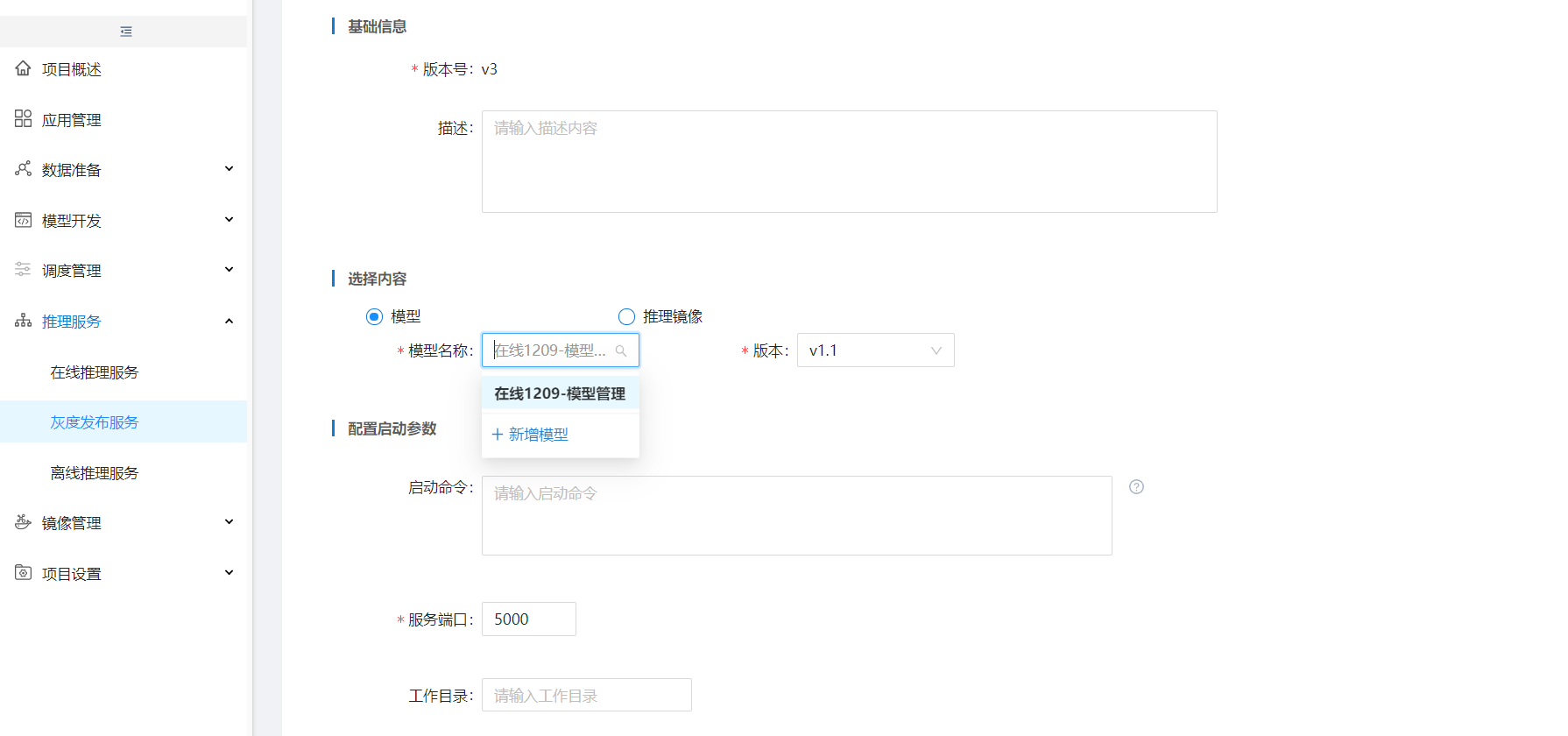
部署灰度发布时可以根据选择的在线推理服务模型或推理镜像新增灰度版本,也可以选择历史版本。
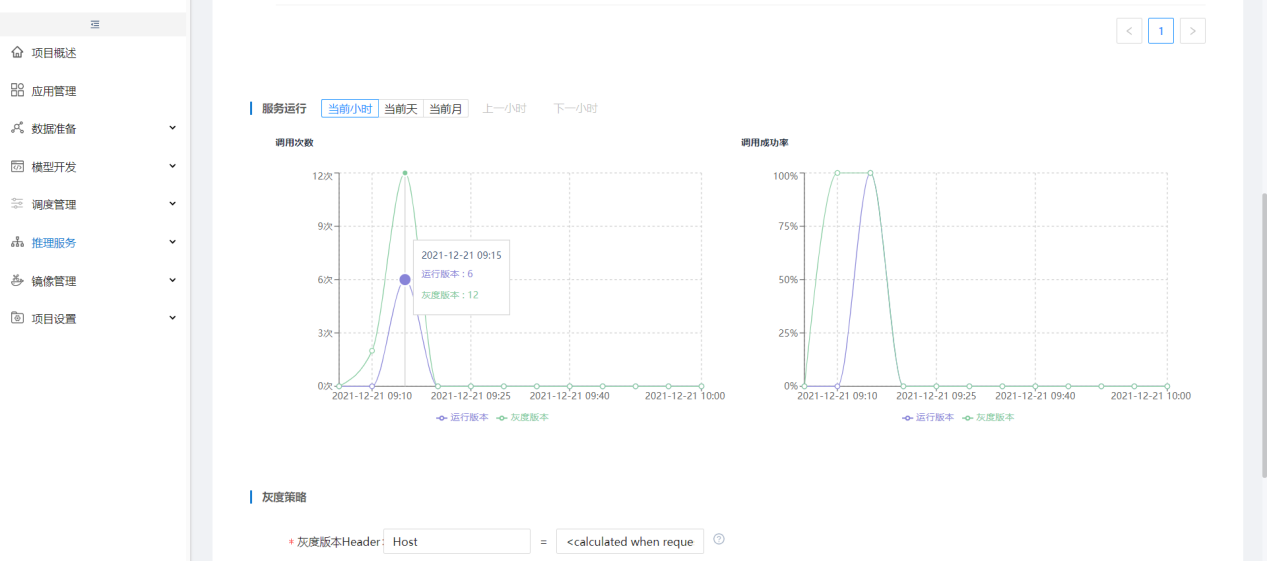
灰度策略可以按三种方式分流,方式一:按流量比例分流,用户自行选择分流比例,在服务调用时可以根据该比例将调用次数分流给灰度版本和运行版本。
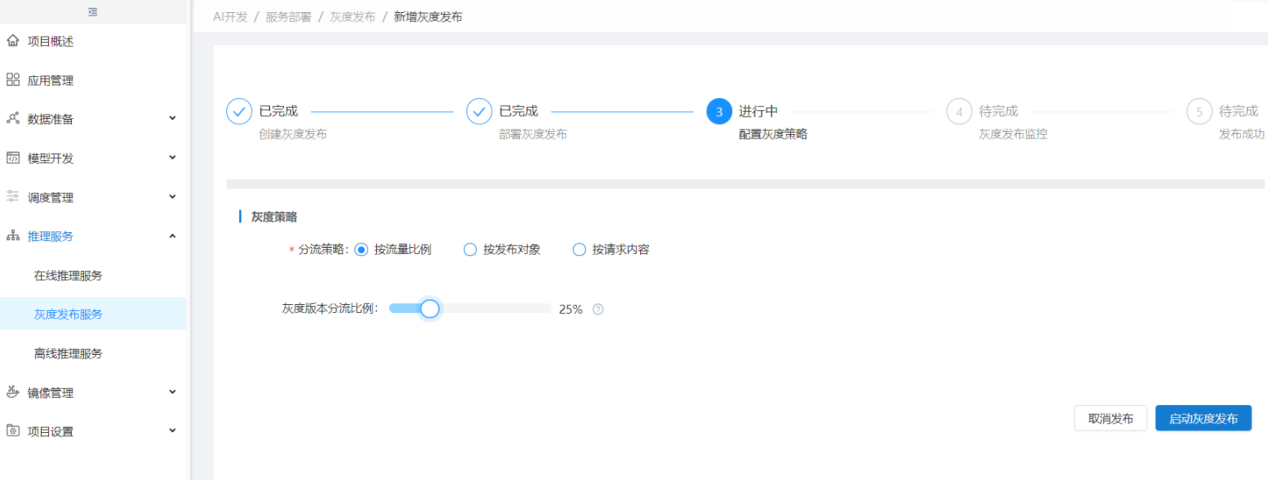
可以调整分流比例,更改灰度策略。

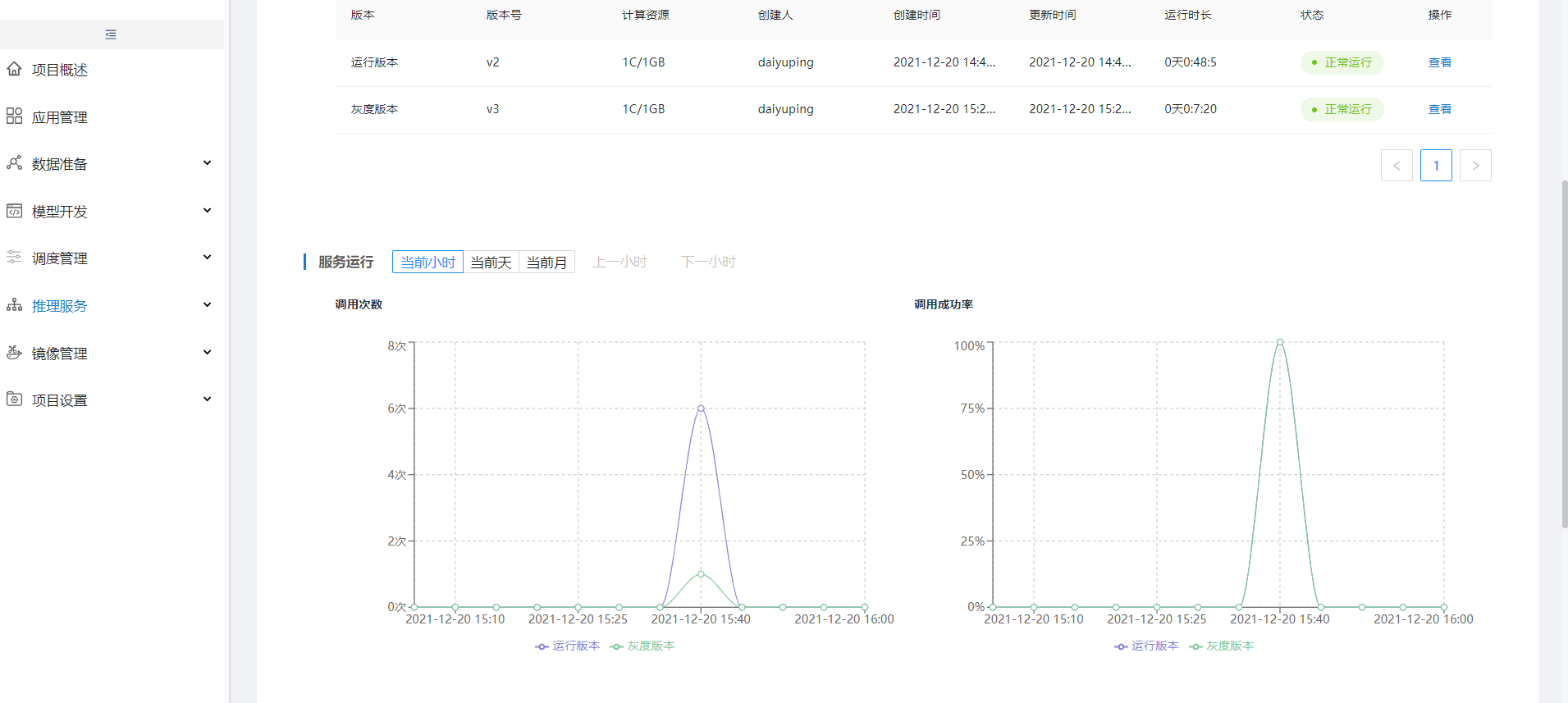
点击确认发布后,关联的在线推理服务中灰度版本会变成当前运行版本。
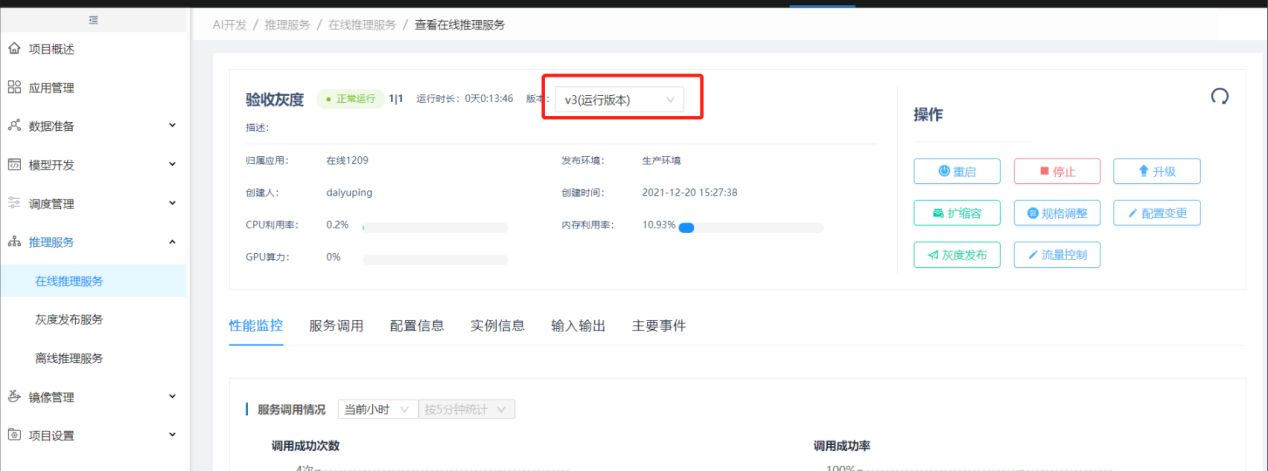
方式二:按发布对象发布需要在创建在线推理服务时勾选鉴权。
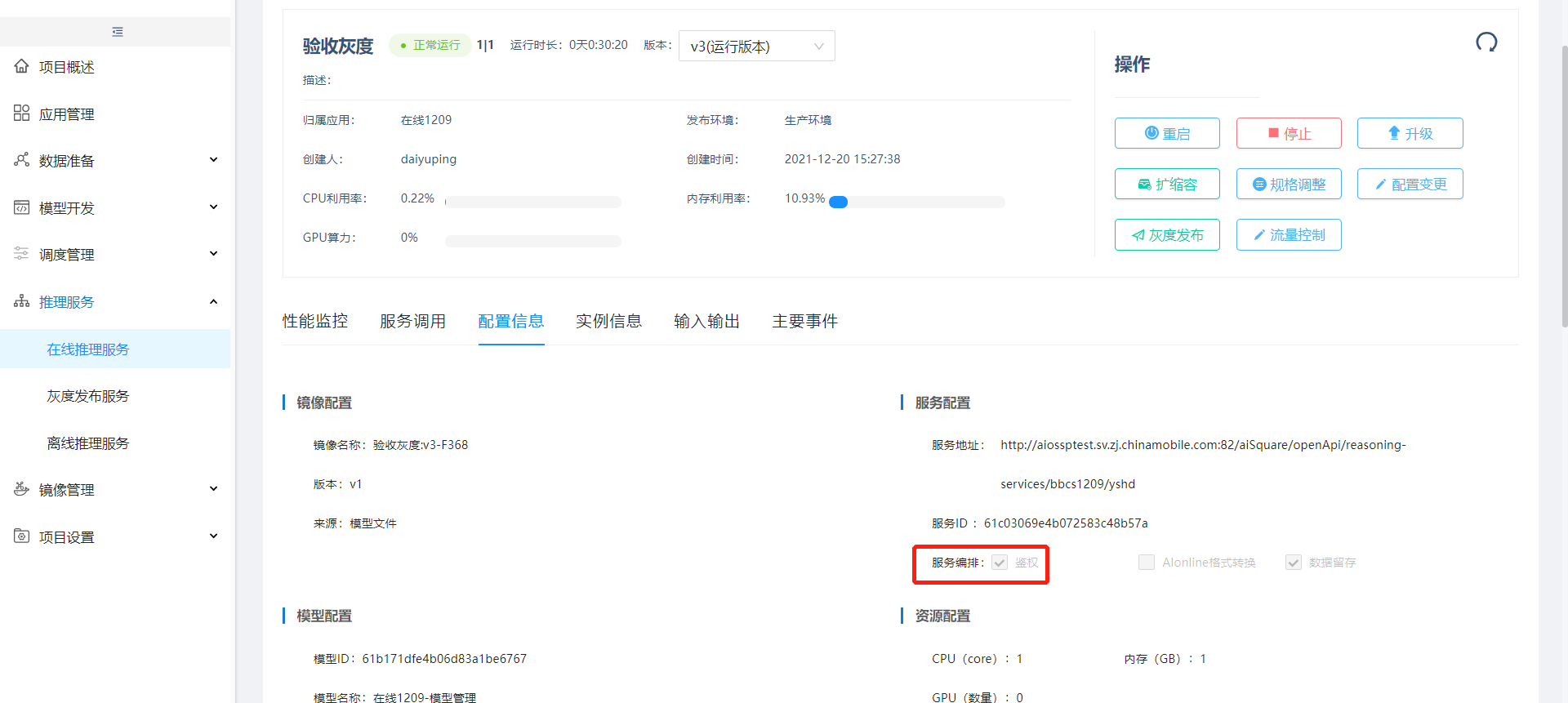
进入【AI使用】新建API用户,用于获取token。
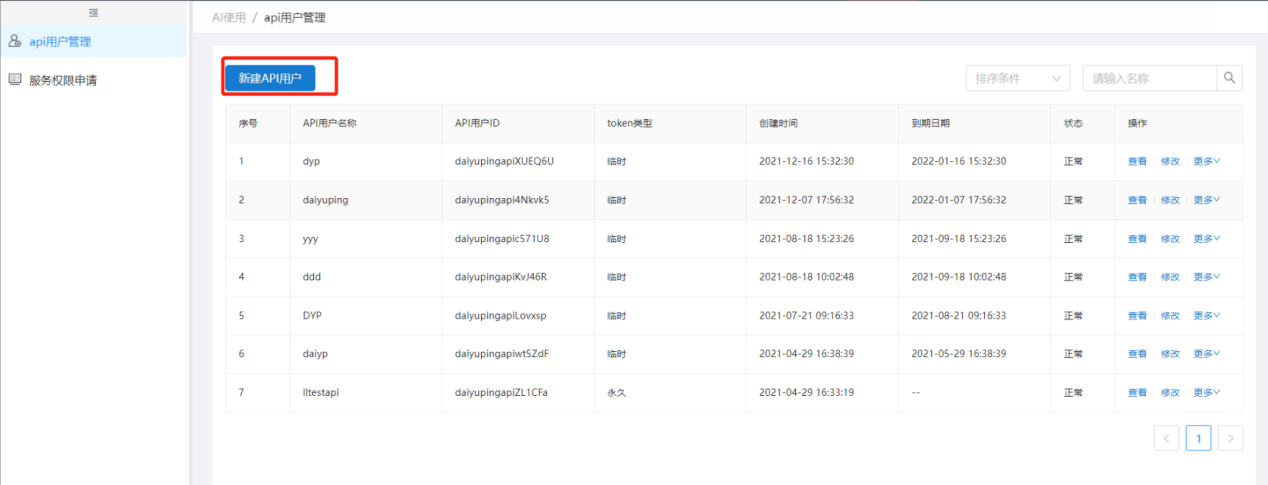
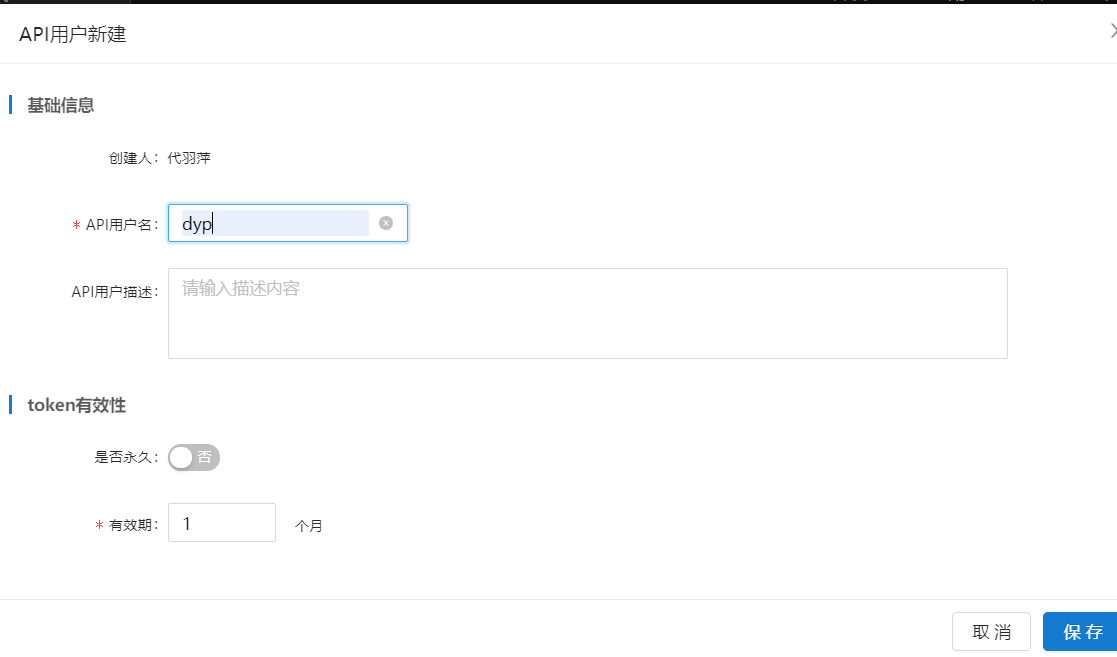
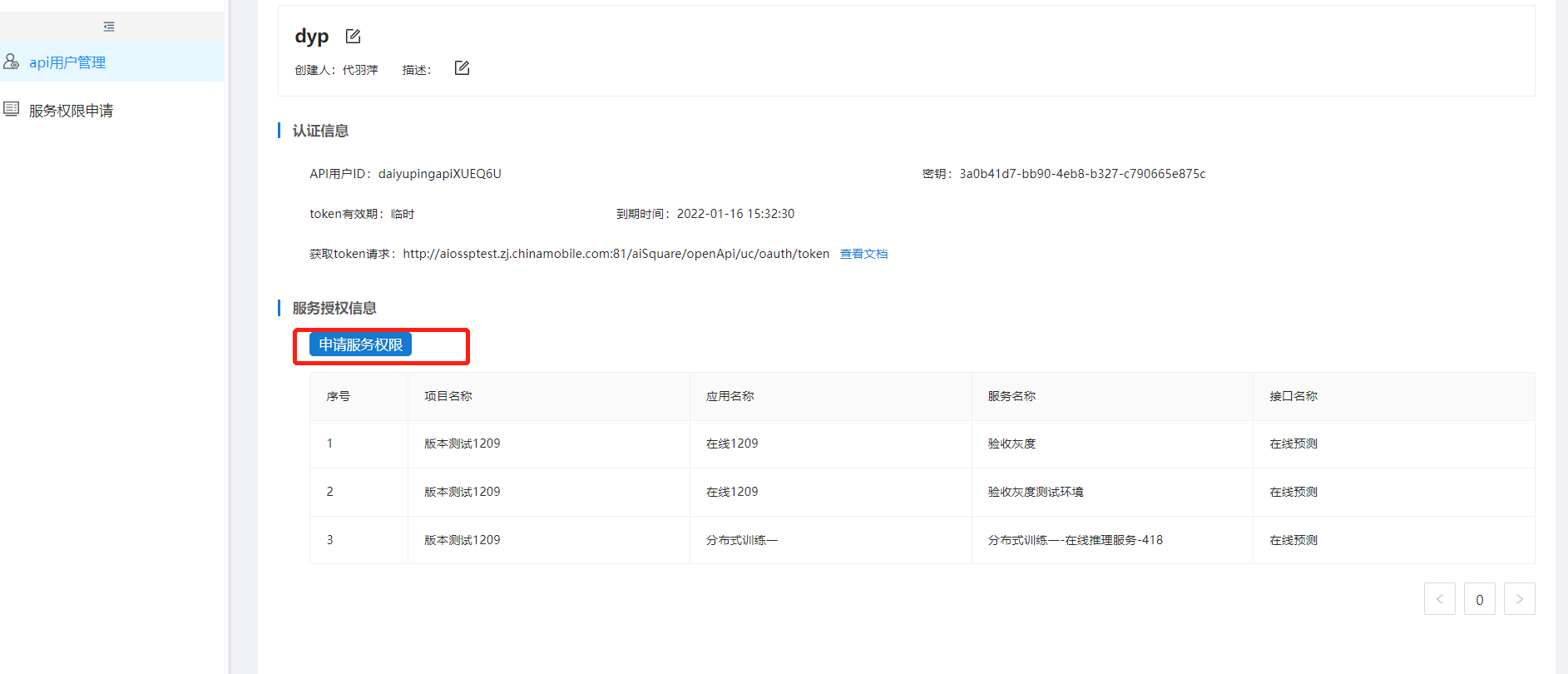
API用户新建成功后点击申请服务权限,选择项目和服务。该API用户选择项目和服务后,新增灰度任务只能选择申请的在线推理服务,且该在线推理服务勾选鉴权才可以走按内容发布流程。
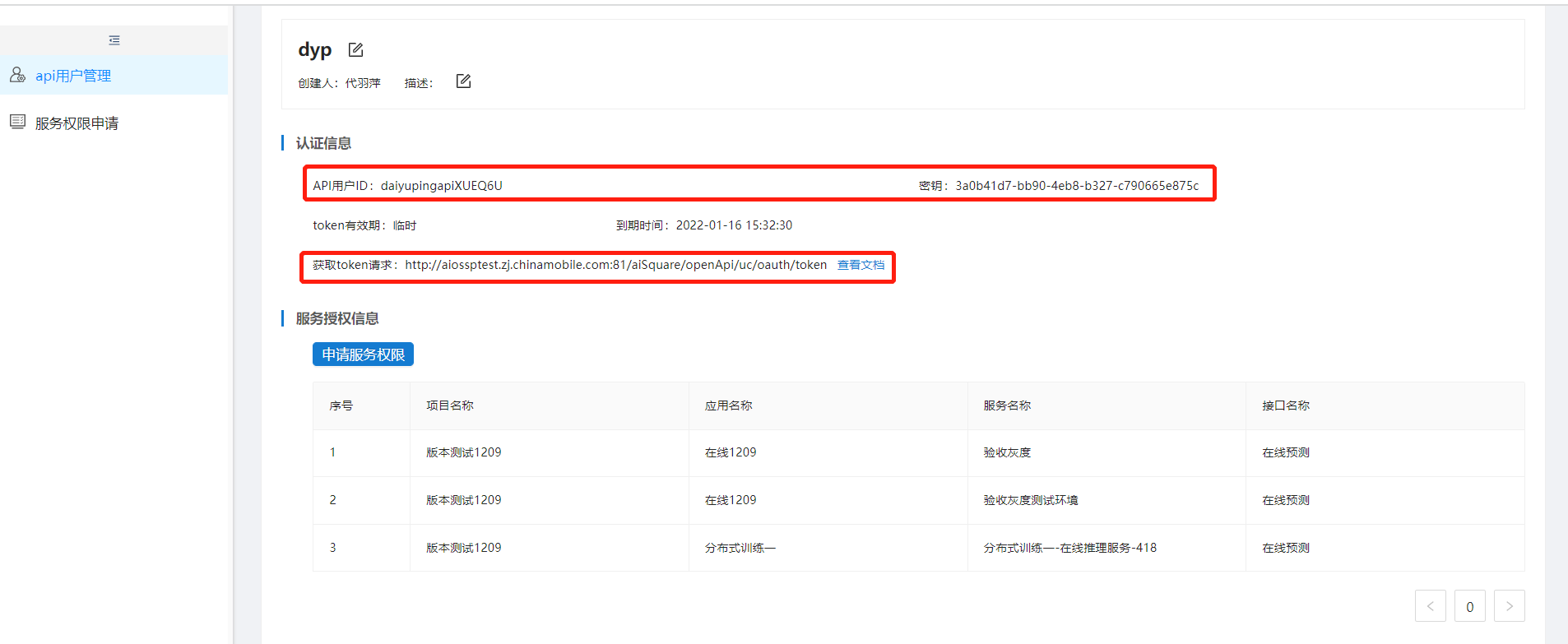
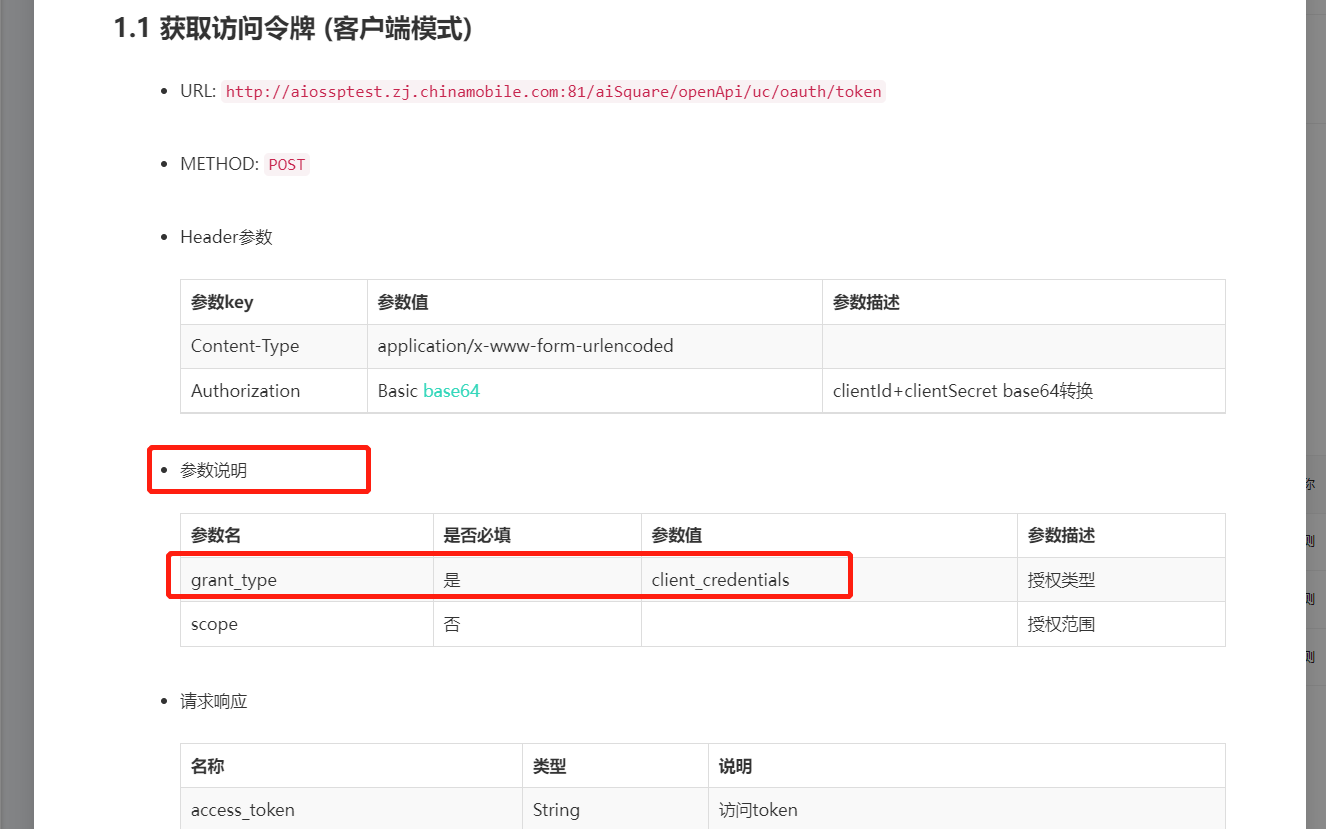
打开postman,选择Basic Auth类型,填写该API用户的用户ID和密钥,选择post方式,填写token请求地址。
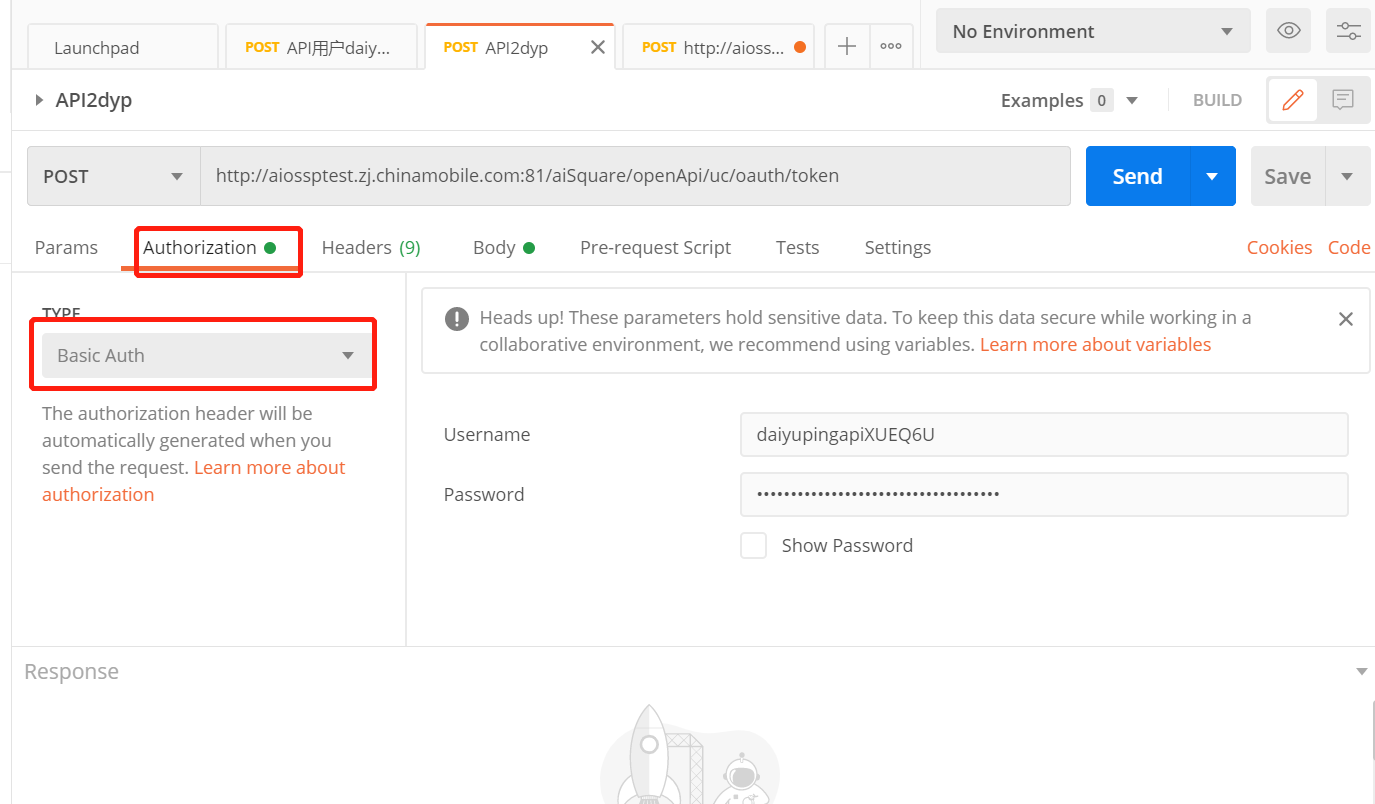
点击获取token请求后面的查看文档,找到参数说明,在postman中Body页面填写参数,点击send获取token。
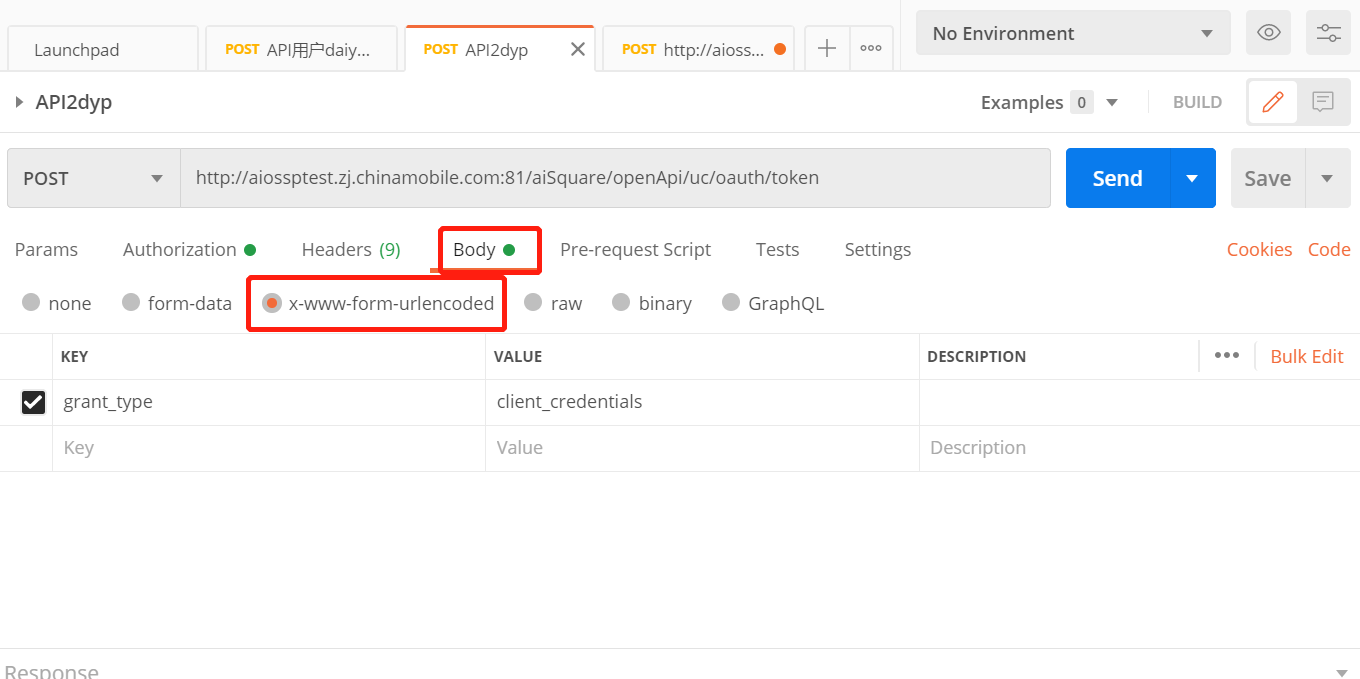

多API用户关联同一个项目和服务,也可以在该推理服务看到多个API用户。
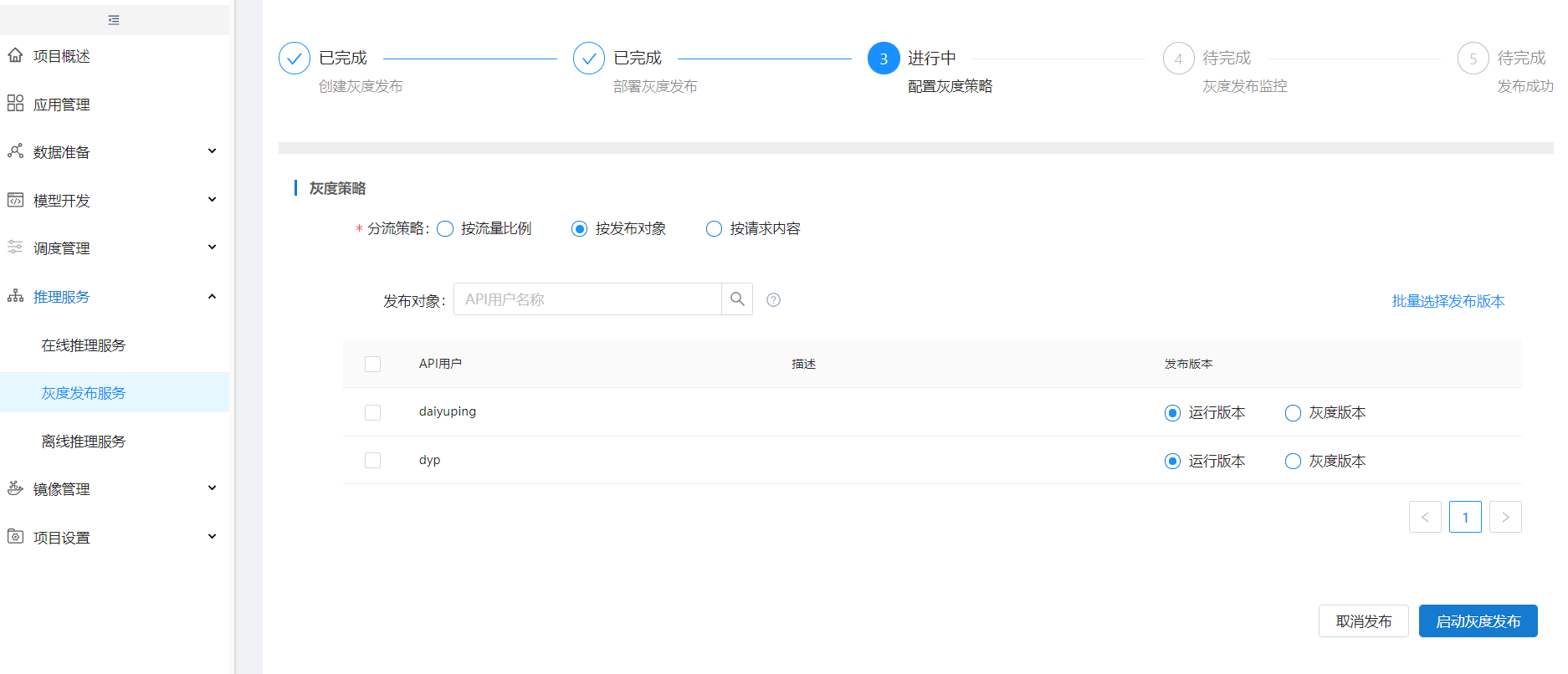
如果选择多个API,那么在postman中用API1用户的token,灰度发布监控中就显示API1选择的发布版本。
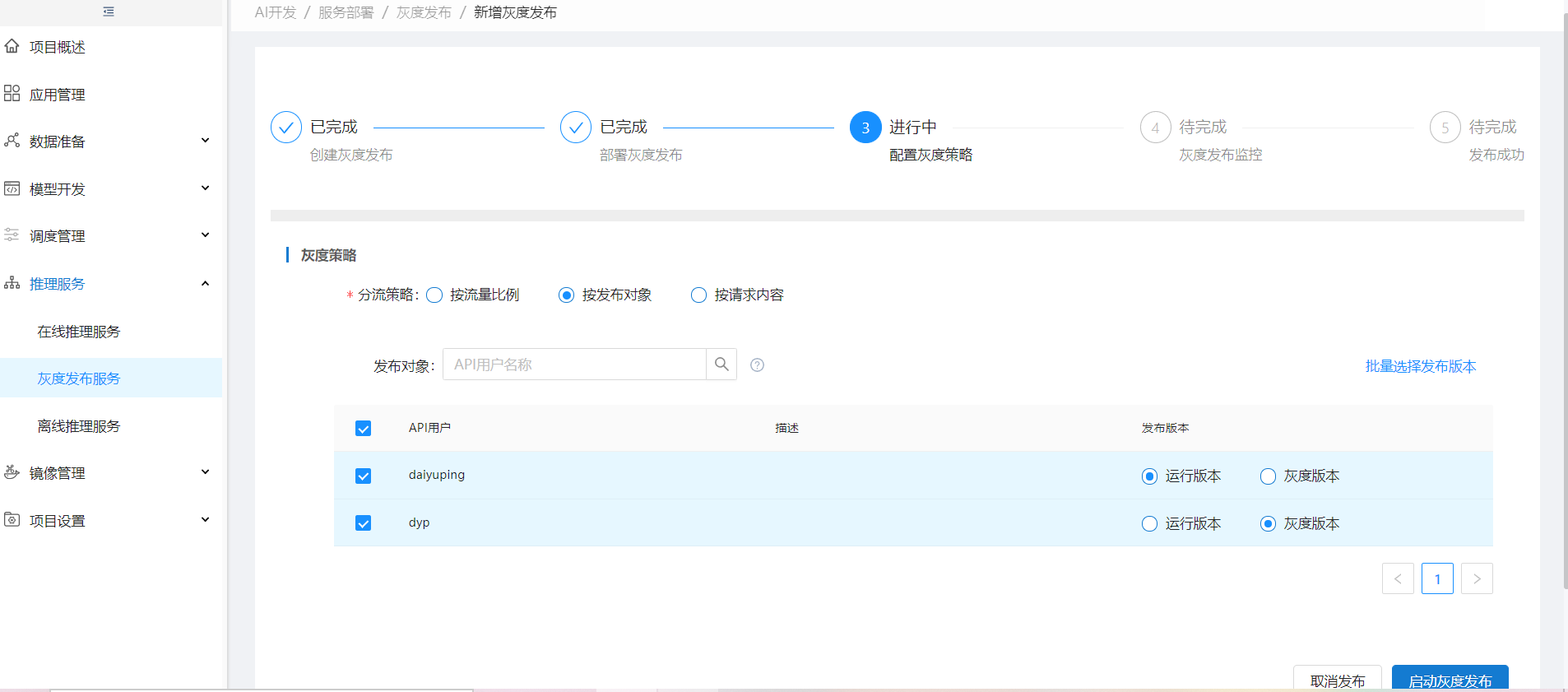


方式三:按请求内容发布。postman请求后点击Headers,选择Headers中任意value和key值。

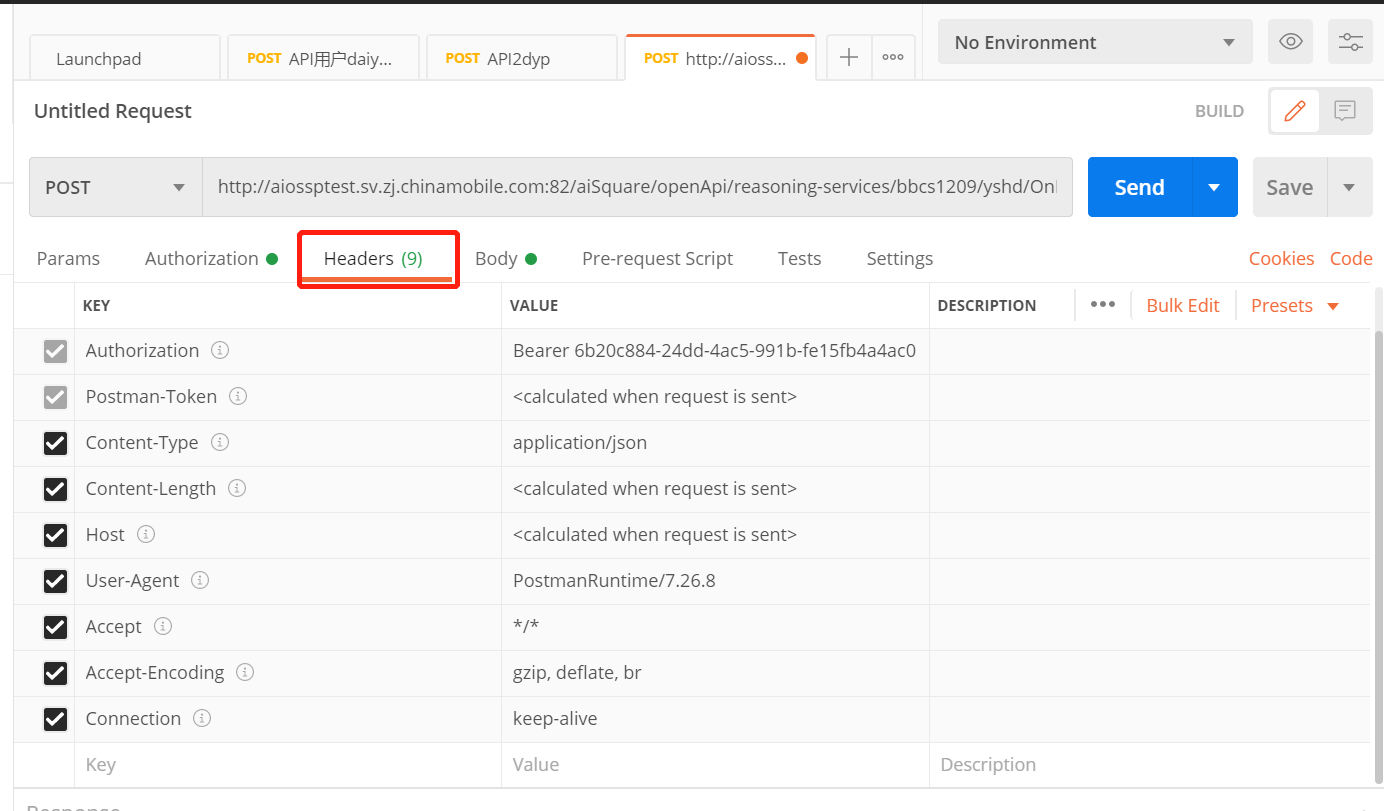
根据灰度策略,将调用量分流给灰度版本和运行版本。
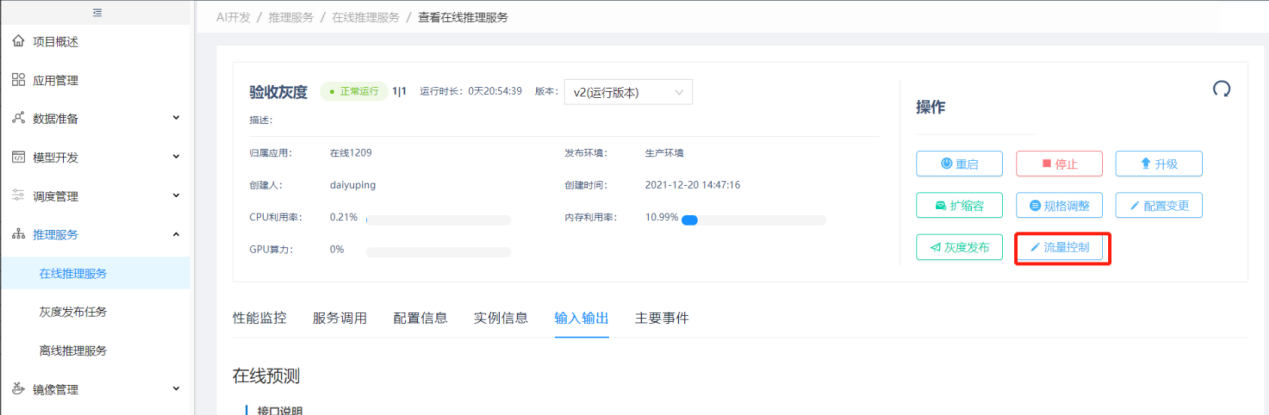
1.2.14. 流量控制
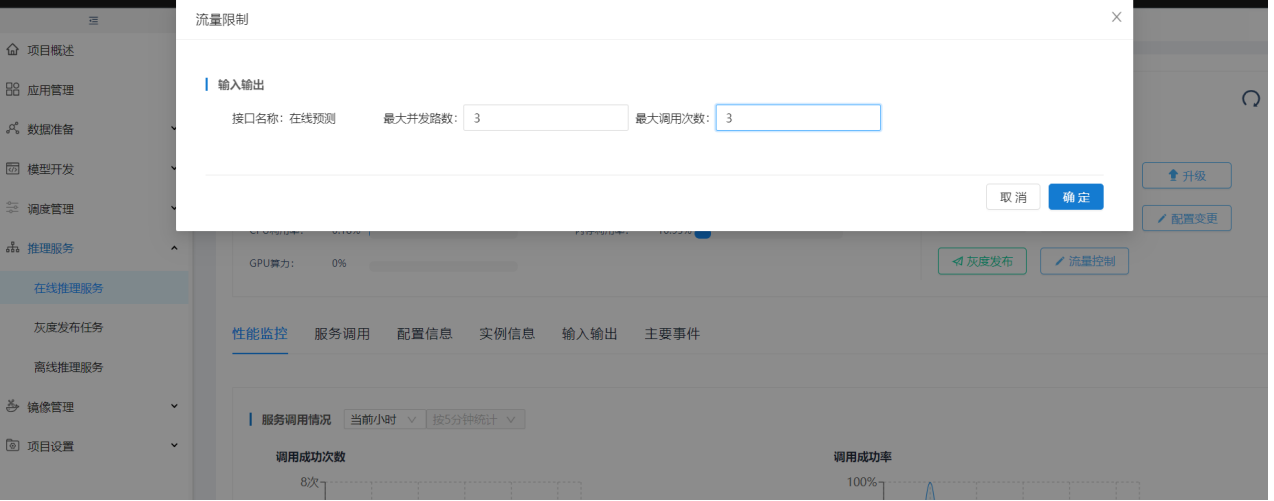
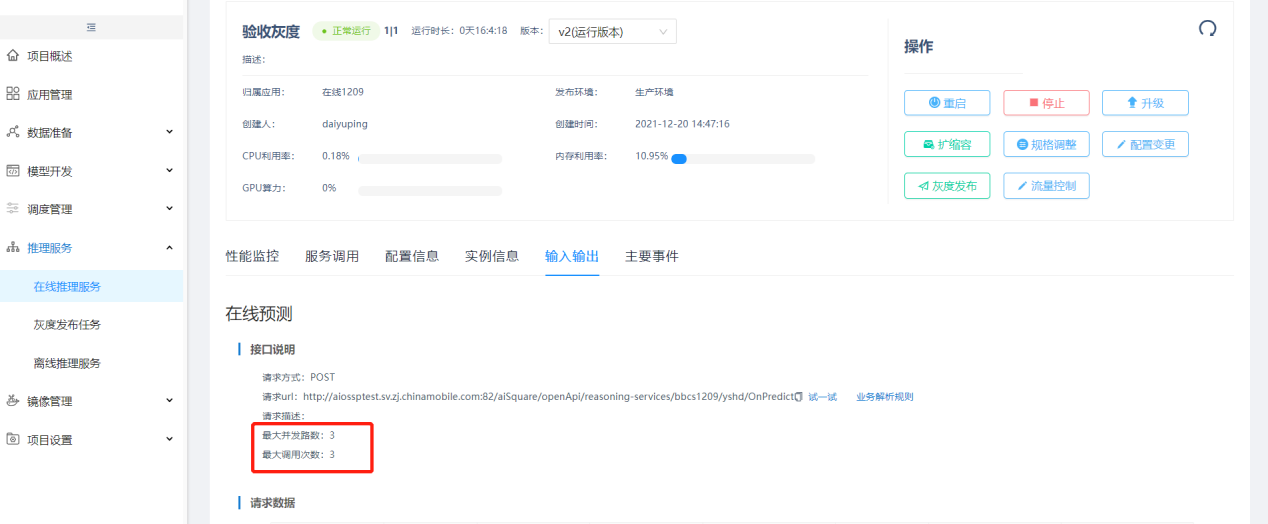
点击【在线推理服务】,点击查看服务,在操作页面点击流量控制按钮。
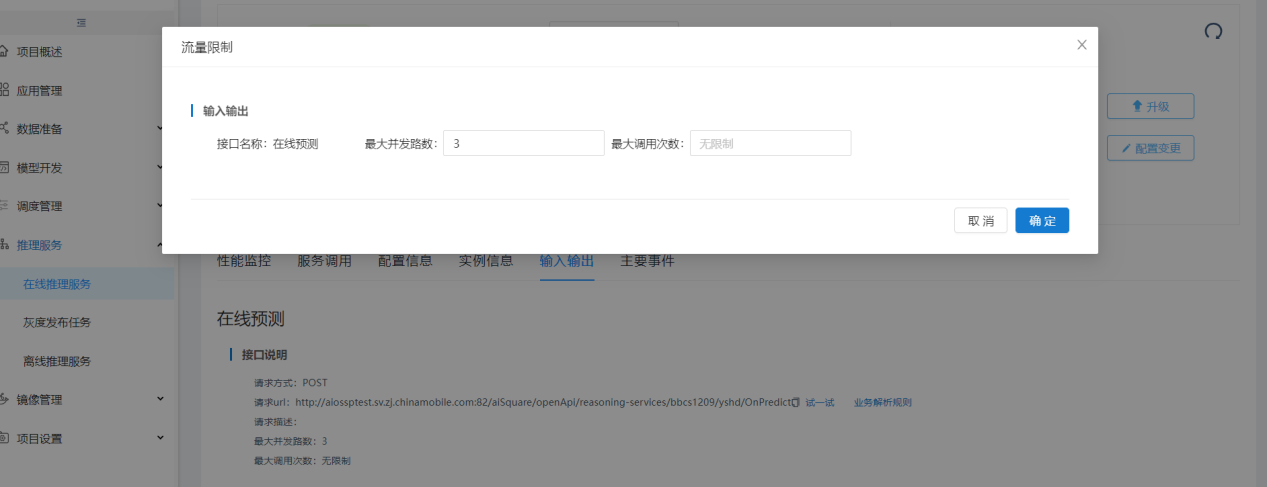
流量控制可以设置最大并发数和最大调用次数,不输入表示无限制。
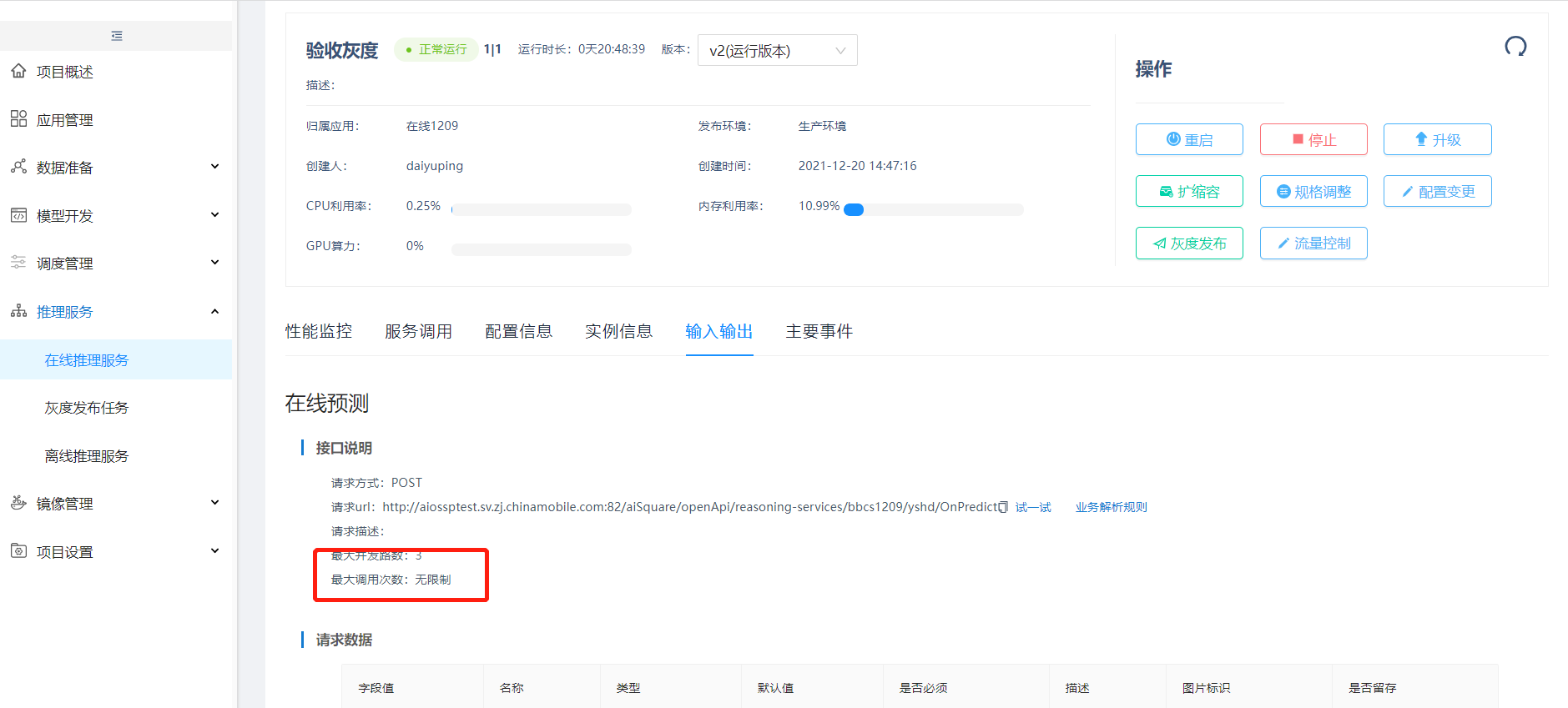
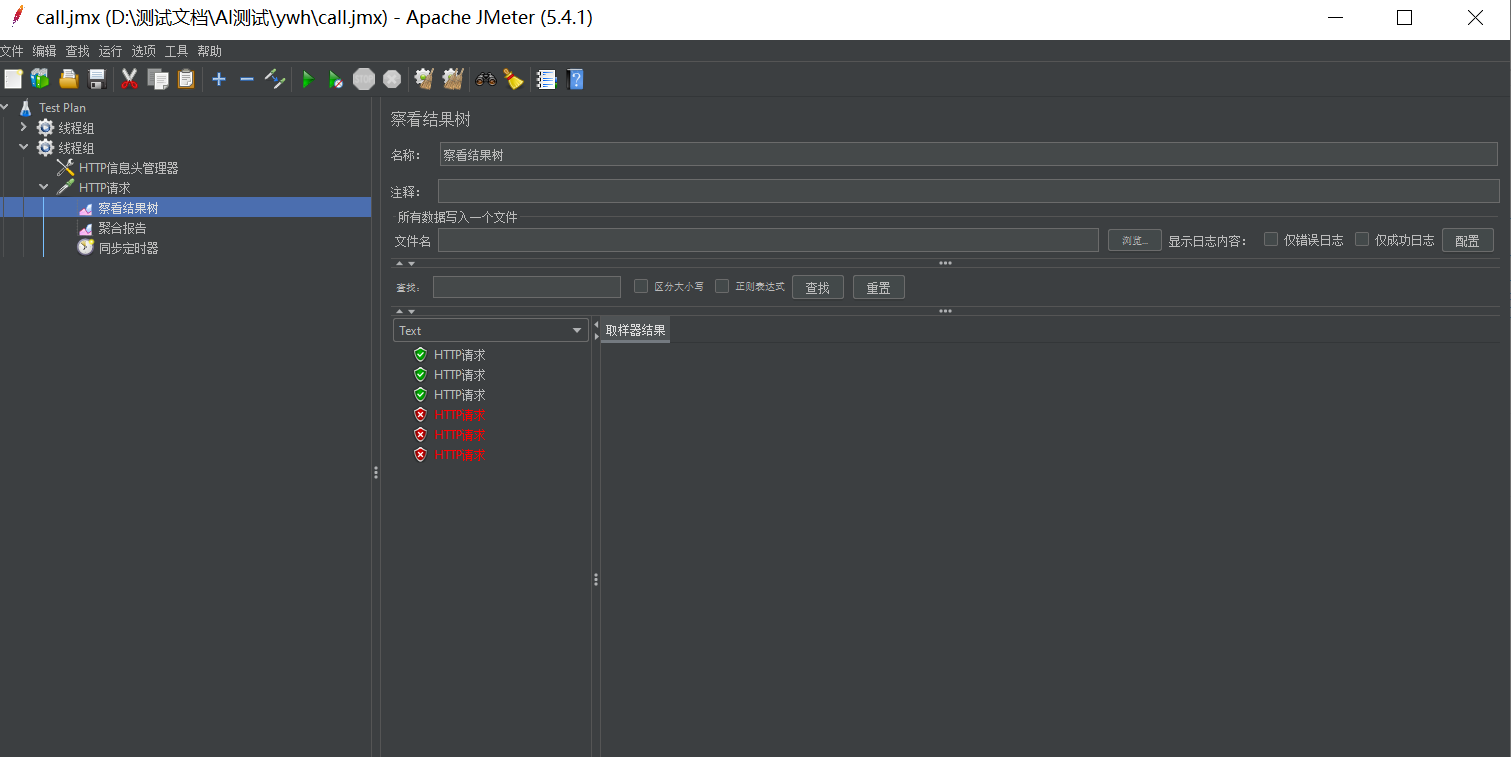
进入jmeter,新建线程组,添加HTTP信息头管理器、HTTP 请求、查看结果树、聚合报告、同步定时器;信息头管理器添加key和value值、token类型和值;
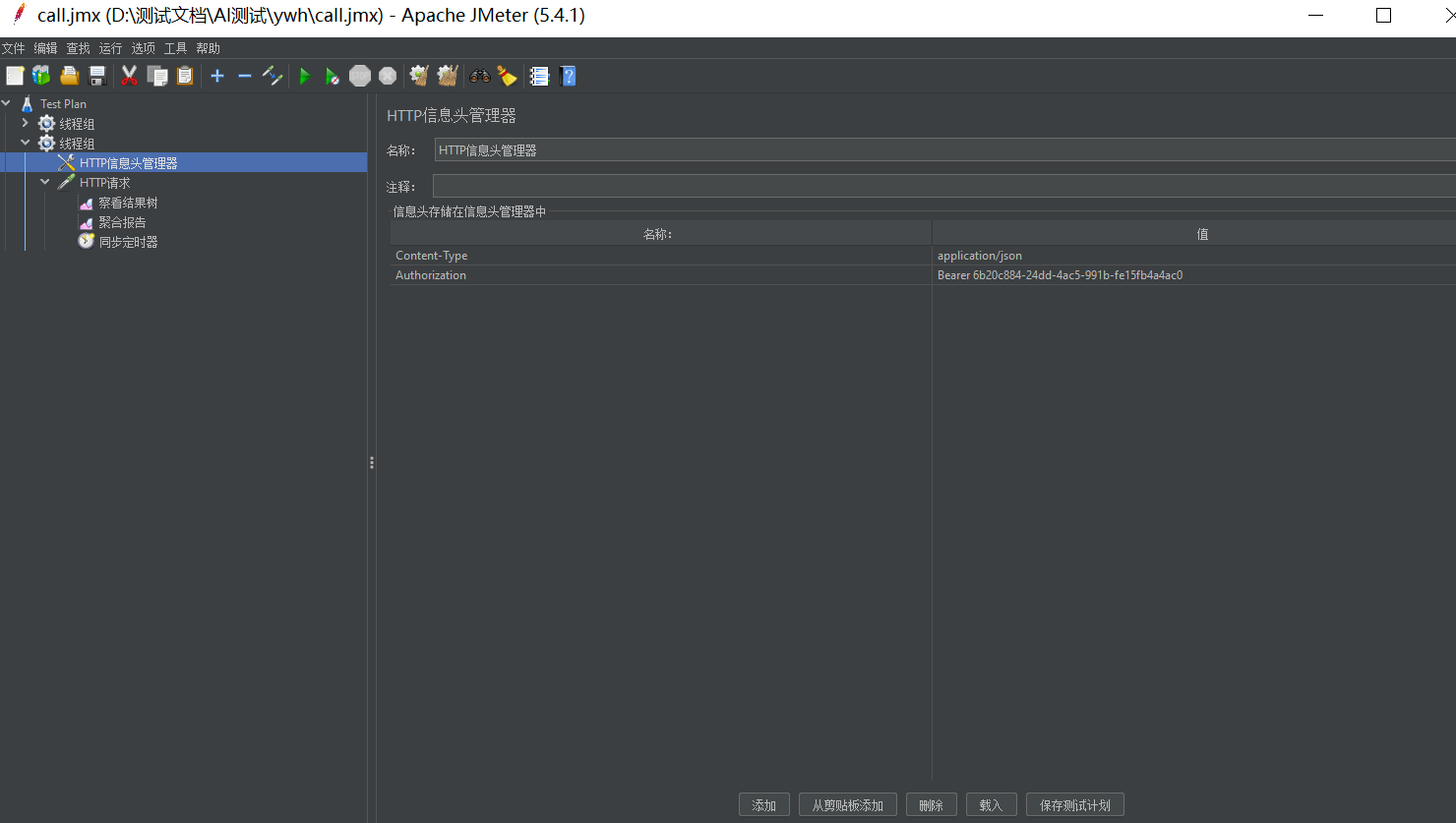
添加同步定时器,设置模拟同步的用户数量。

HTTP请求中选择post请求、添加推理服务的输入输出路径,消息体数据中添加入参。
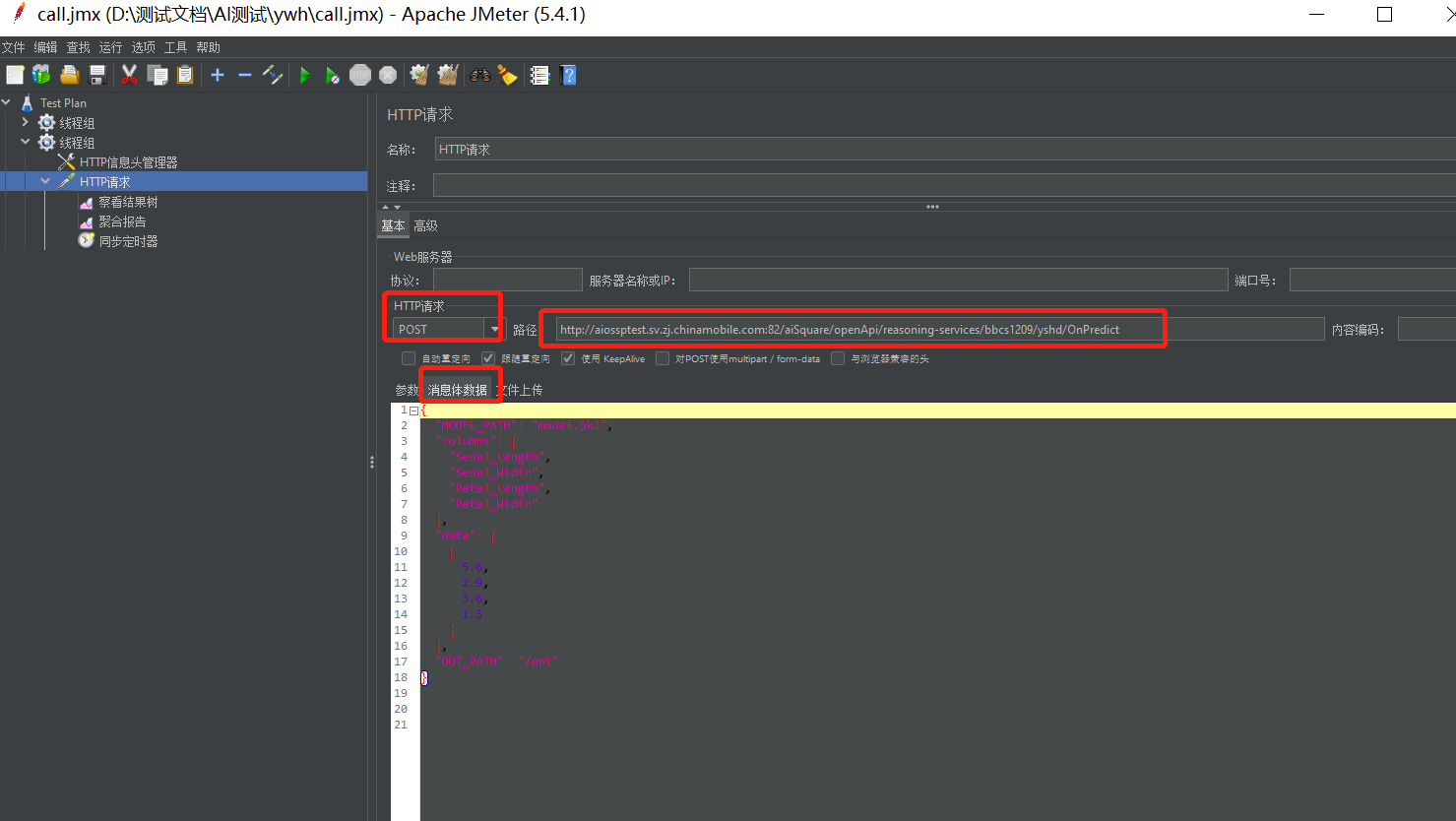
根据填写的同步并发用户数和流量控制并发数请求,6个线程数只有填写的3个同步并发通过,其余不通过。
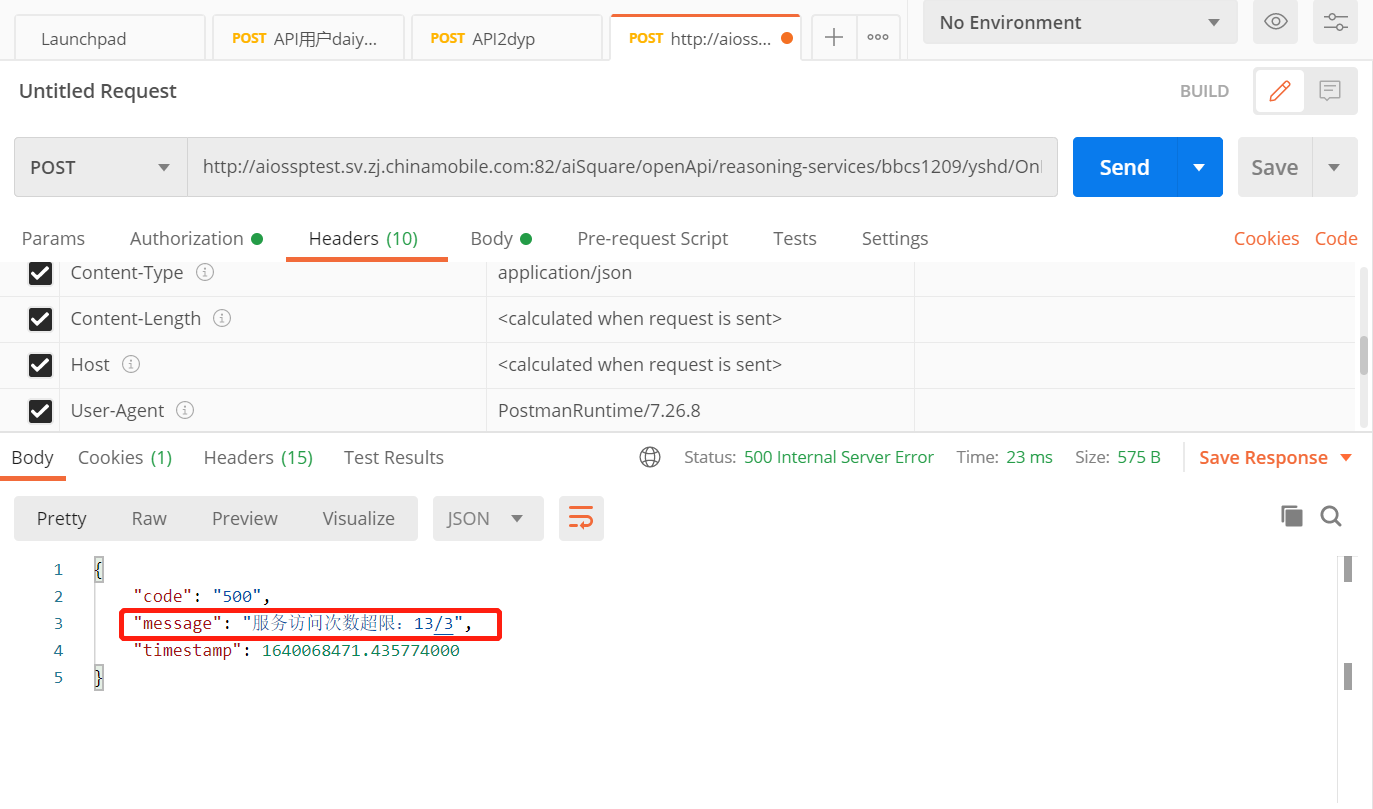
设置最大调用次数后,postman请求超过该次数,就无法在调用,显示服务访问次数超限。
1.2.15. 镜像管理
用户进入镜像管理,可选择三种不同类型的镜像。(当前构建基础镜像兼容训练镜像)
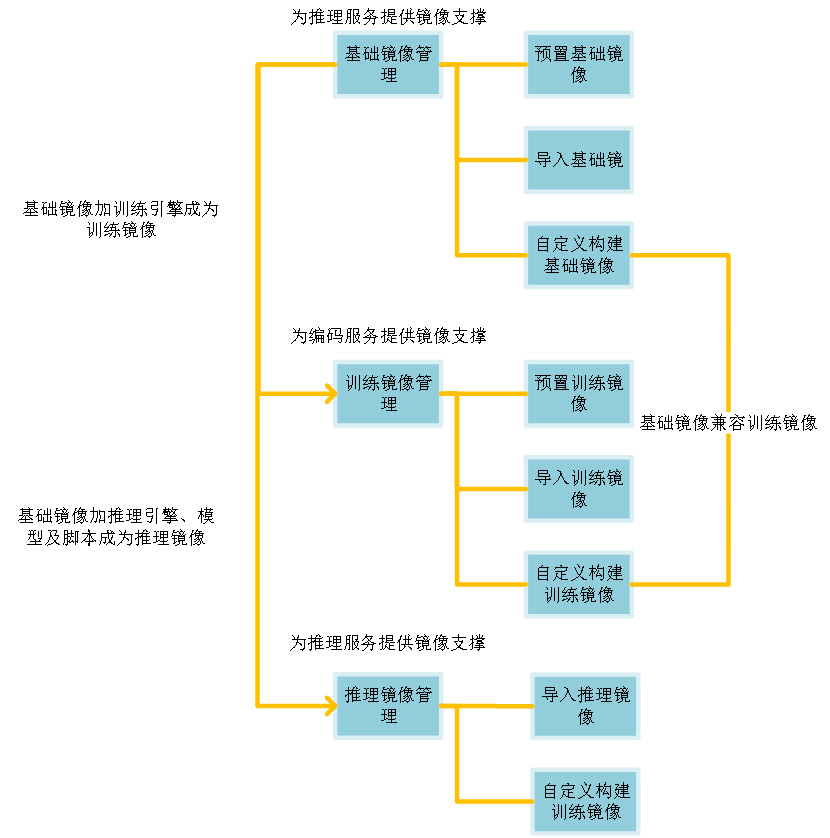
1.2.15.1 基础镜像管理
系统里可用的基础镜像,包含预置基础镜像(平台级),导入的基础镜像和自定义构建镜像。(项目级)

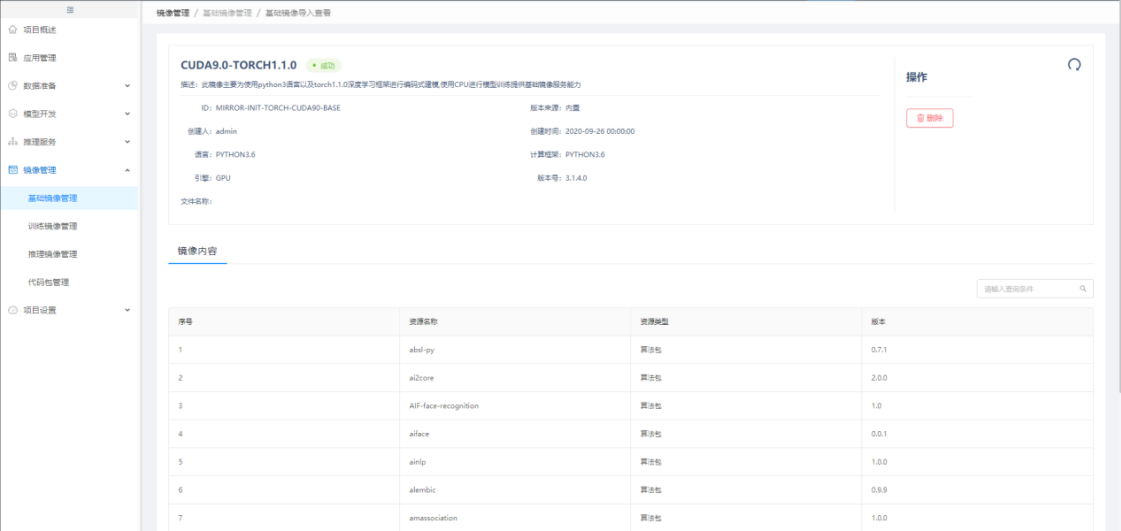
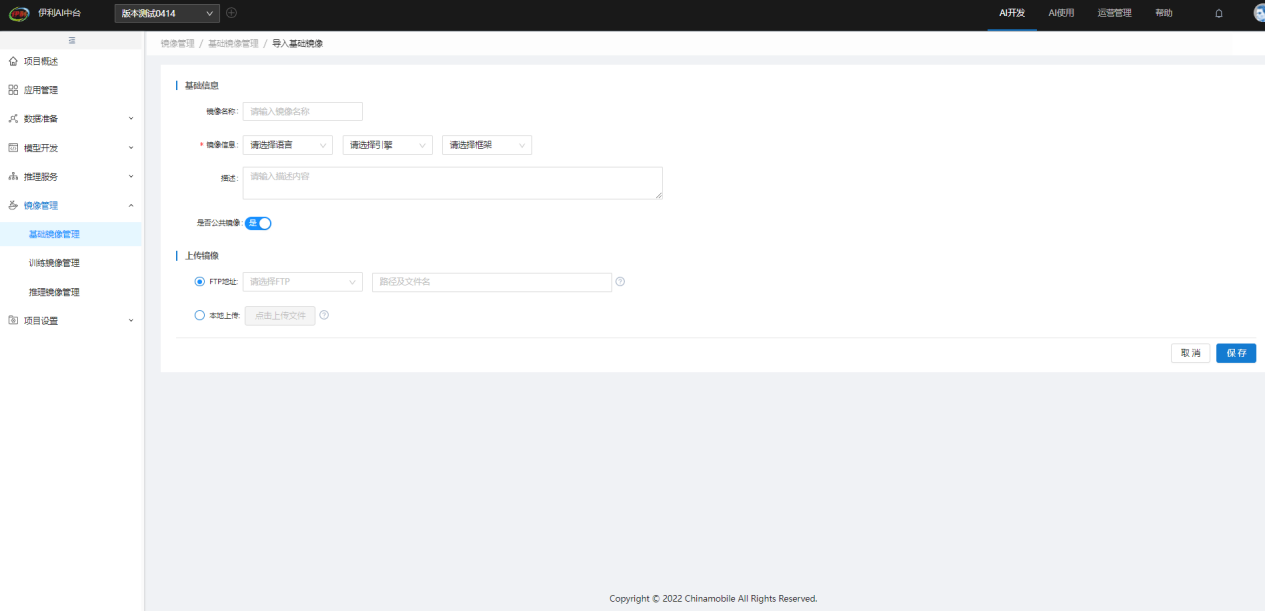
第三方导入的基础镜像,支持FTP和本地上传。
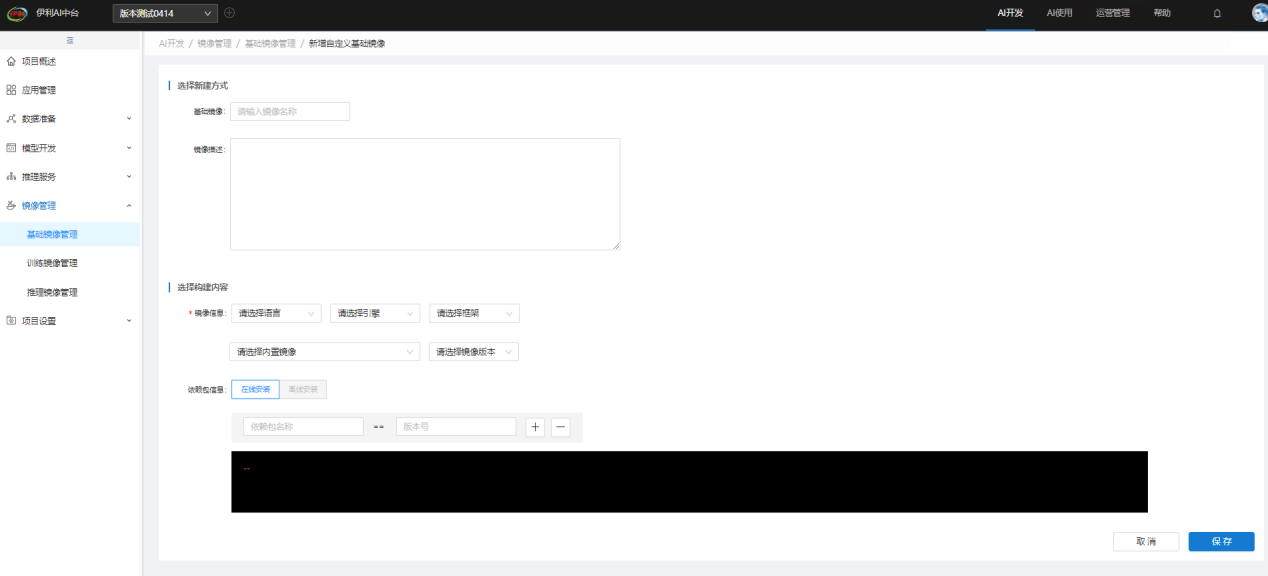
自定义构建的镜像,支持输入依赖包和版本(在线),系统里能匹配到即开始构建镜像。 备注:当前的基础镜像内带了训练镜像的SDK,后续训练时缺少依赖包,可在此处进行构建。
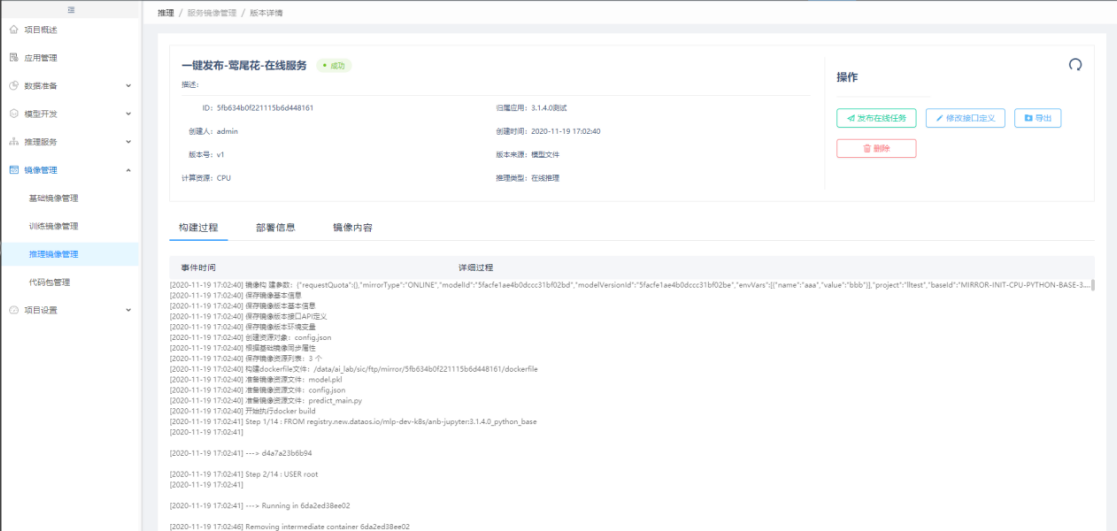
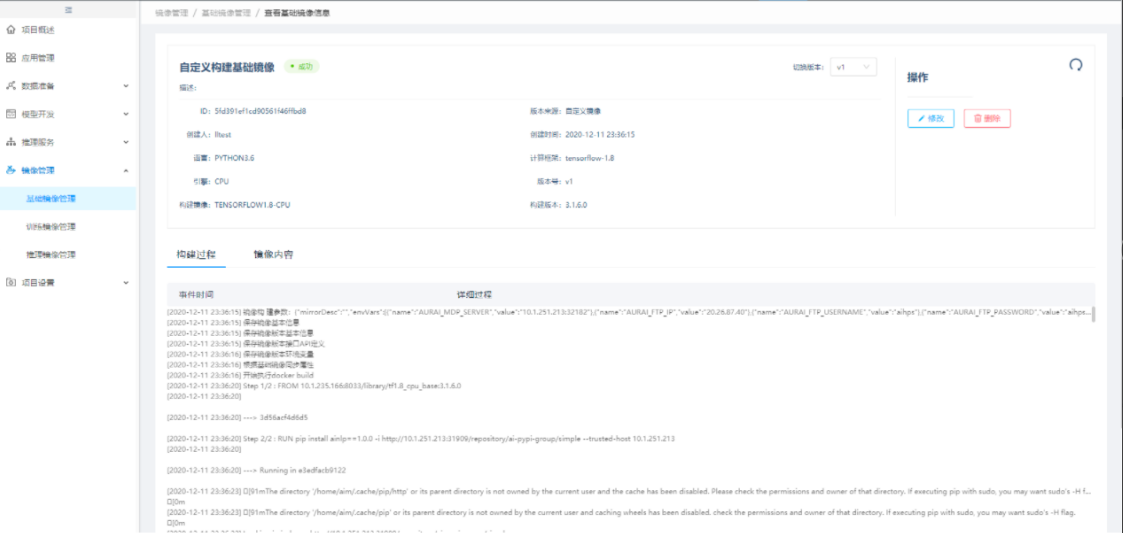
基础镜像的详细信息,可看到构建过程和镜像内容。

1.2.15.2 训练镜像管理
训练镜像包含预置和导入。
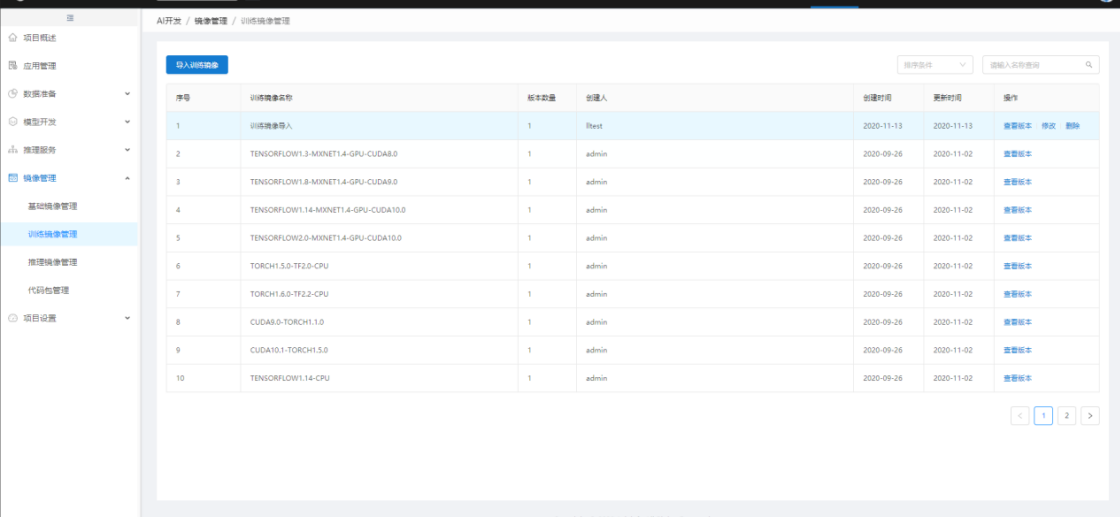
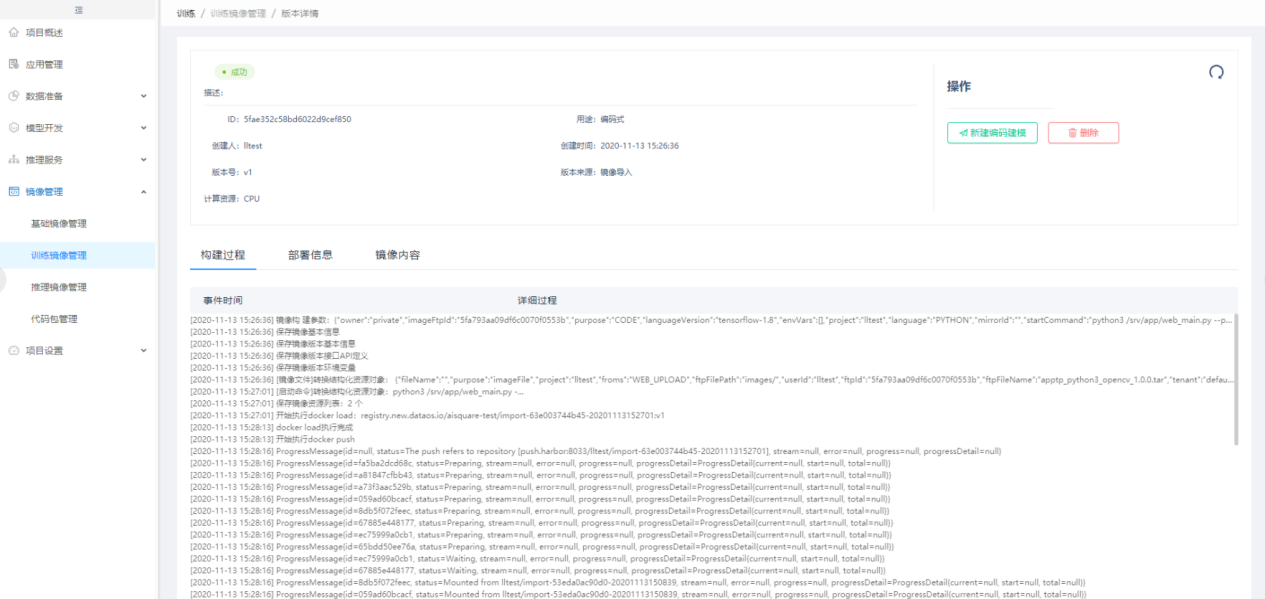
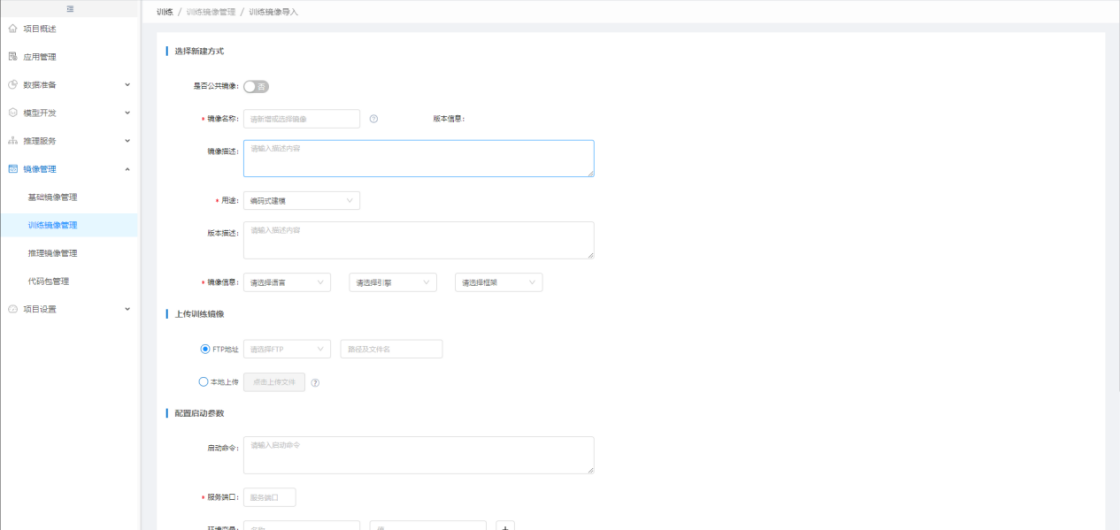
第三方导入的训练镜像,主要用于建模训练。
1.2.15.3 推理镜像管理
推理镜像包含创建在线推理时产生的镜像,也包含第三方导入的推理镜像,同时也支持单独对模型和代码包进行镜像构建。
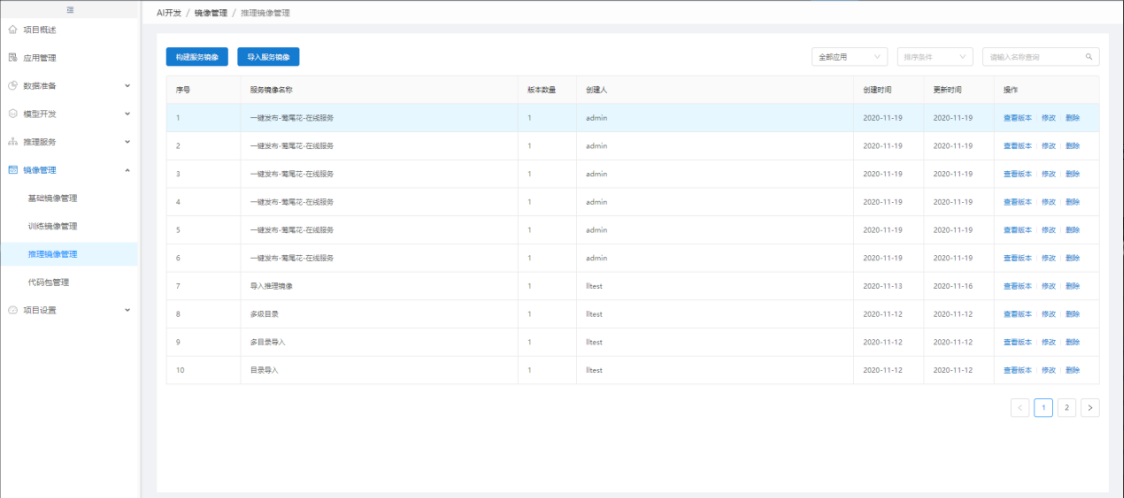
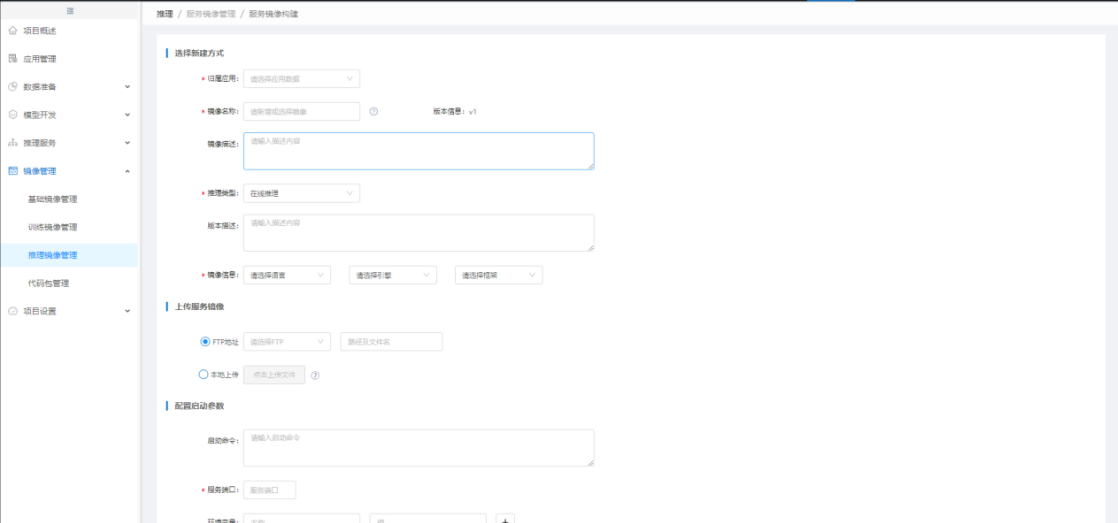
导入第三方推理镜像,可提前编辑好暴露端口、环境变量、启动命令等。
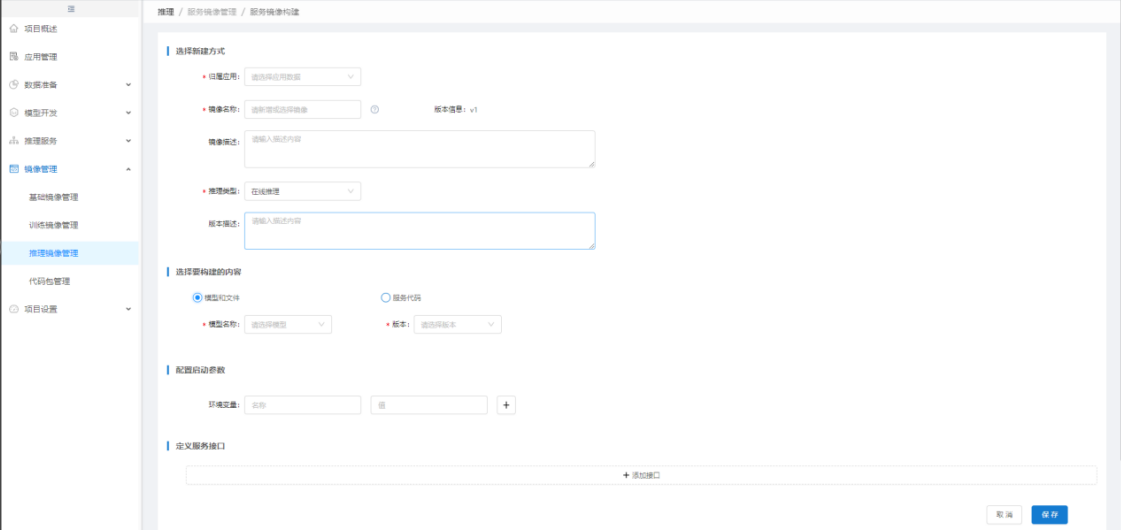
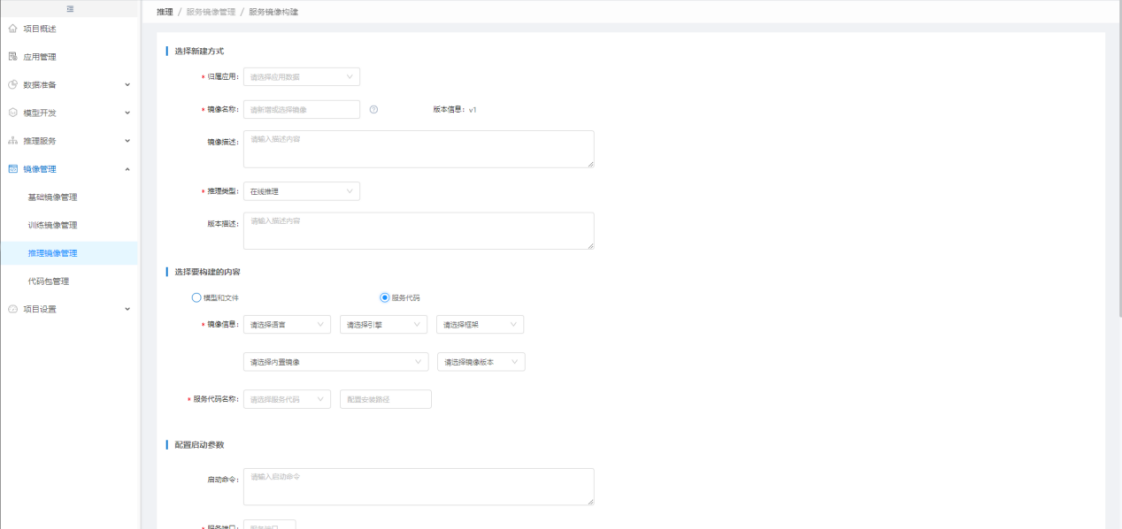
按模型构建和代码包构建镜像。
1.2.15.4 代码包管理
代码包管理包含第三方导入的代码包,与基础镜像构建后具备推理服务能力。

代码包导入,支持FTP和本地上传。
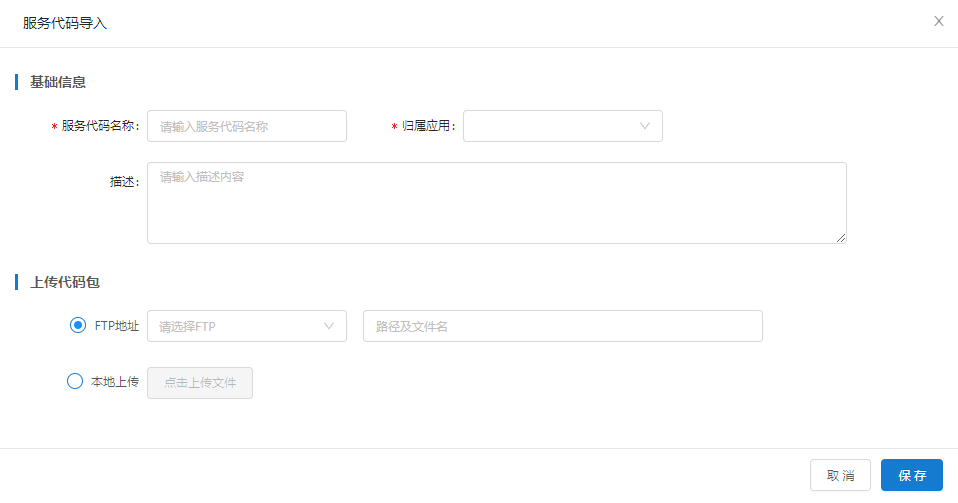
1.3. 使用示例
1.3.1.结构化鸢尾花分类
本示例使用结构化数据集及编码式建模,进行鸢尾花分类模型训练,训练完成后将模型部署成在线推理服务并进行API调用测试。在数据接入前请先准备好项目及资源,并创建"鸢尾花"应用。
1. 准备鸢尾花训练数据
将以下数据复制到鸢尾花文本文件:
Id/Sepal_Length/Sepal_Width/Petal_Length/Petal_Width/Species
1/5.1/3.5/1.4/0.2/setosa
2/4.9/3/1.4/0.2/setosa
3/4.7/3.2/1.3/0.2/setosa
4/4.6/3.1/1.5/0.2/setosa
5/5/3.6/1.4/0.2/setosa
6/5.4/3.9/1.7/0.4/setosa
7/4.6/3.4/1.4/0.3/setosa
8/5/3.4/1.5/0.2/setosa
9/4.4/2.9/1.4/0.2/setosa
10/4.9/3.1/1.5/0.1/setosa
11/5.4/3.7/1.5/0.2/setosa
12/4.8/3.4/1.6/0.2/setosa
13/4.8/3/1.4/0.1/setosa
14/4.3/3/1.1/0.1/setosa
15/5.8/4/1.2/0.2/setosa
16/5.7/4.4/1.5/0.4/setosa
17/5.4/3.9/1.3/0.4/setosa
18/5.1/3.5/1.4/0.3/setosa
19/5.7/3.8/1.7/0.3/setosa
20/5.1/3.8/1.5/0.3/setosa
21/5.4/3.4/1.7/0.2/setosa
22/5.1/3.7/1.5/0.4/setosa
23/4.6/3.6/1/0.2/setosa
24/5.1/3.3/1.7/0.5/setosa
25/4.8/3.4/1.9/0.2/setosa
26/5/3/1.6/0.2/setosa
27/5/3.4/1.6/0.4/setosa
28/5.2/3.5/1.5/0.2/setosa
29/5.2/3.4/1.4/0.2/setosa
30/4.7/3.2/1.6/0.2/setosa
31/4.8/3.1/1.6/0.2/setosa
32/5.4/3.4/1.5/0.4/setosa
33/5.2/4.1/1.5/0.1/setosa
34/5.5/4.2/1.4/0.2/setosa
35/4.9/3.1/1.5/0.2/setosa
36/5/3.2/1.2/0.2/setosa
37/5.5/3.5/1.3/0.2/setosa
38/4.9/3.6/1.4/0.1/setosa
39/4.4/3/1.3/0.2/setosa
40/5.1/3.4/1.5/0.2/setosa
41/5/3.5/1.3/0.3/setosa
42/4.5/2.3/1.3/0.3/setosa
43/4.4/3.2/1.3/0.2/setosa
44/5/3.5/1.6/0.6/setosa
45/5.1/3.8/1.9/0.4/setosa
46/4.8/3/1.4/0.3/setosa
47/5.1/3.8/1.6/0.2/setosa
48/4.6/3.2/1.4/0.2/setosa
49/5.3/3.7/1.5/0.2/setosa
50/5/3.3/1.4/0.2/setosa
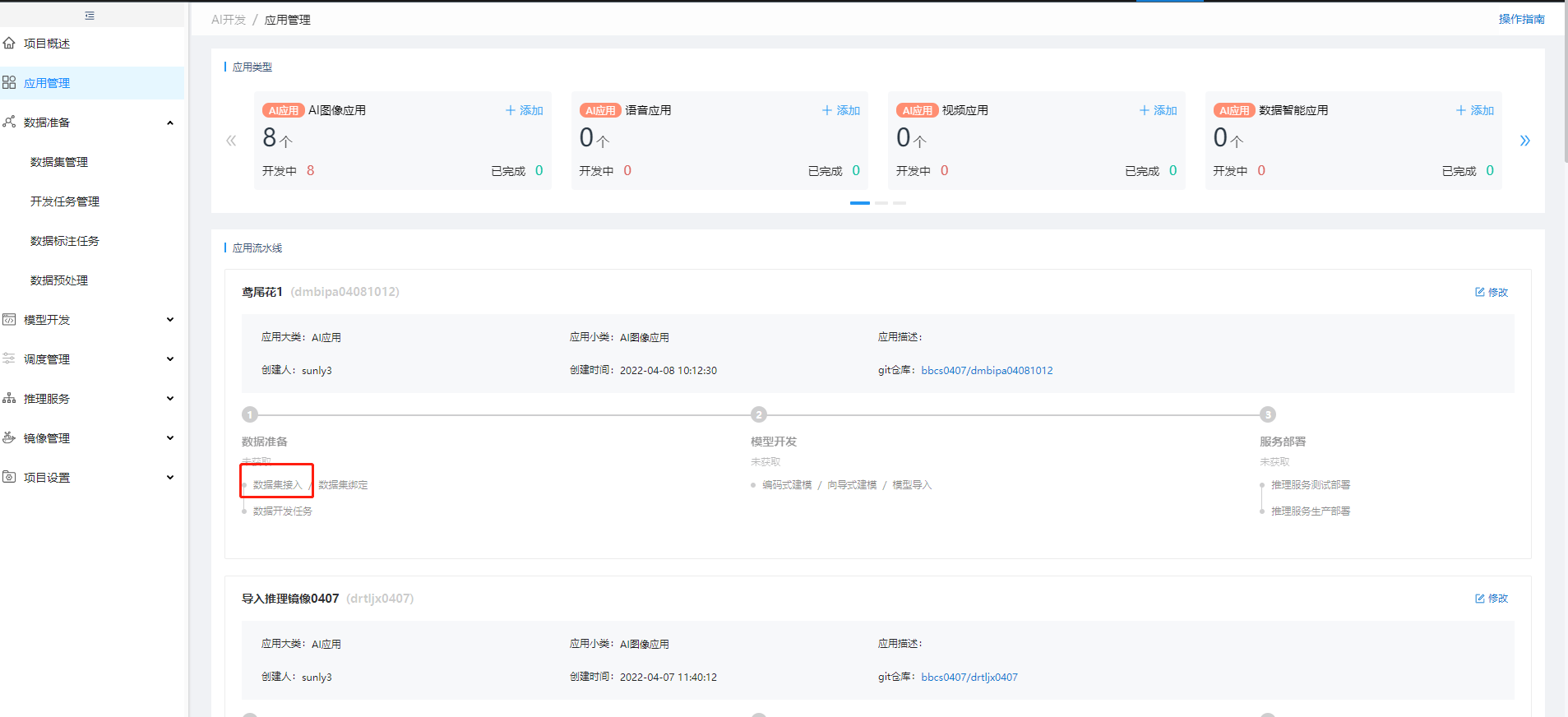
2. 接入鸢尾花数据集
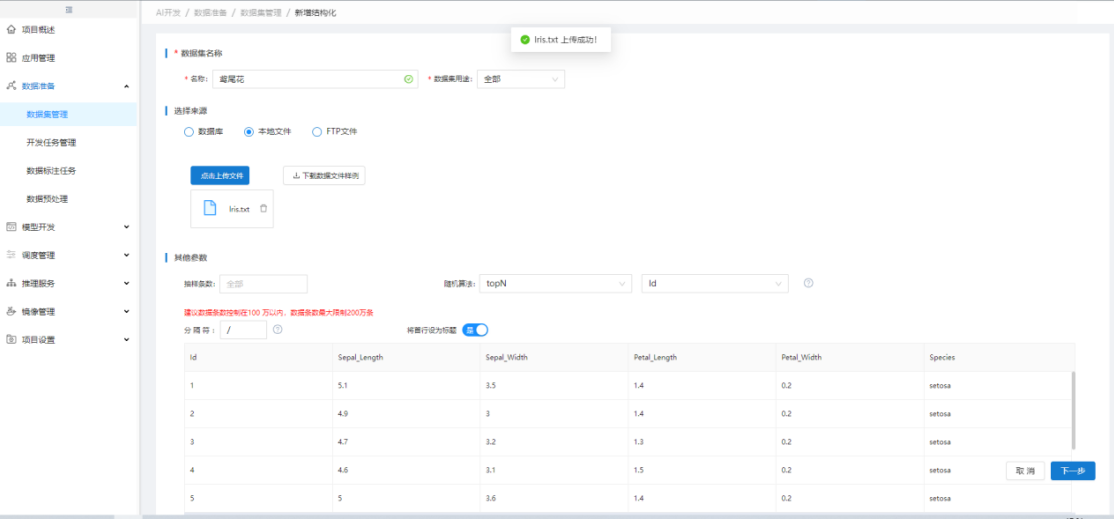
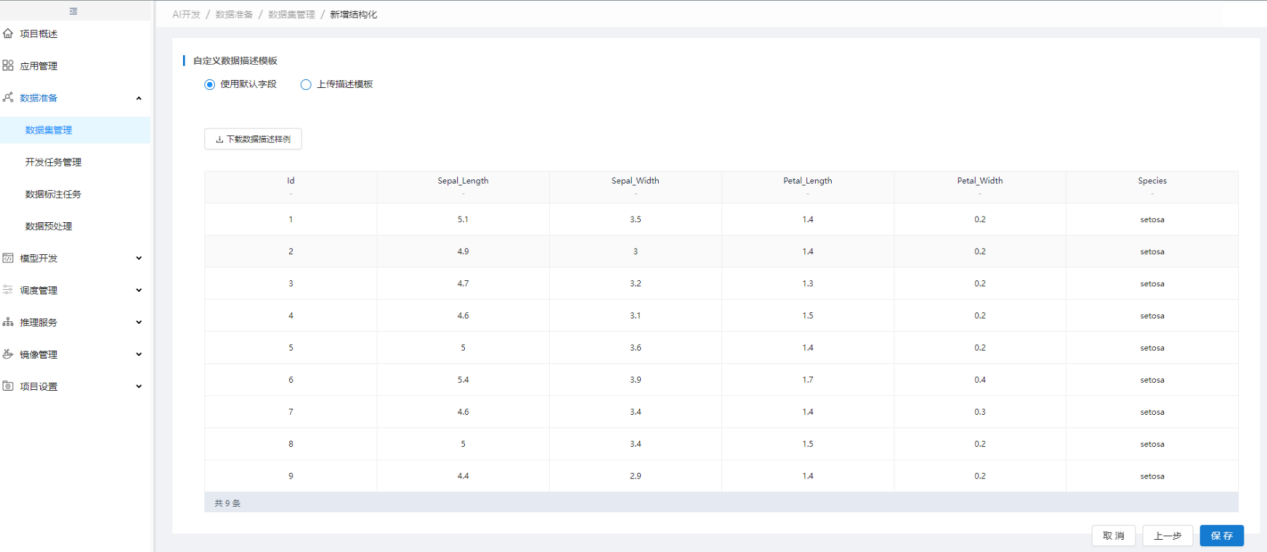
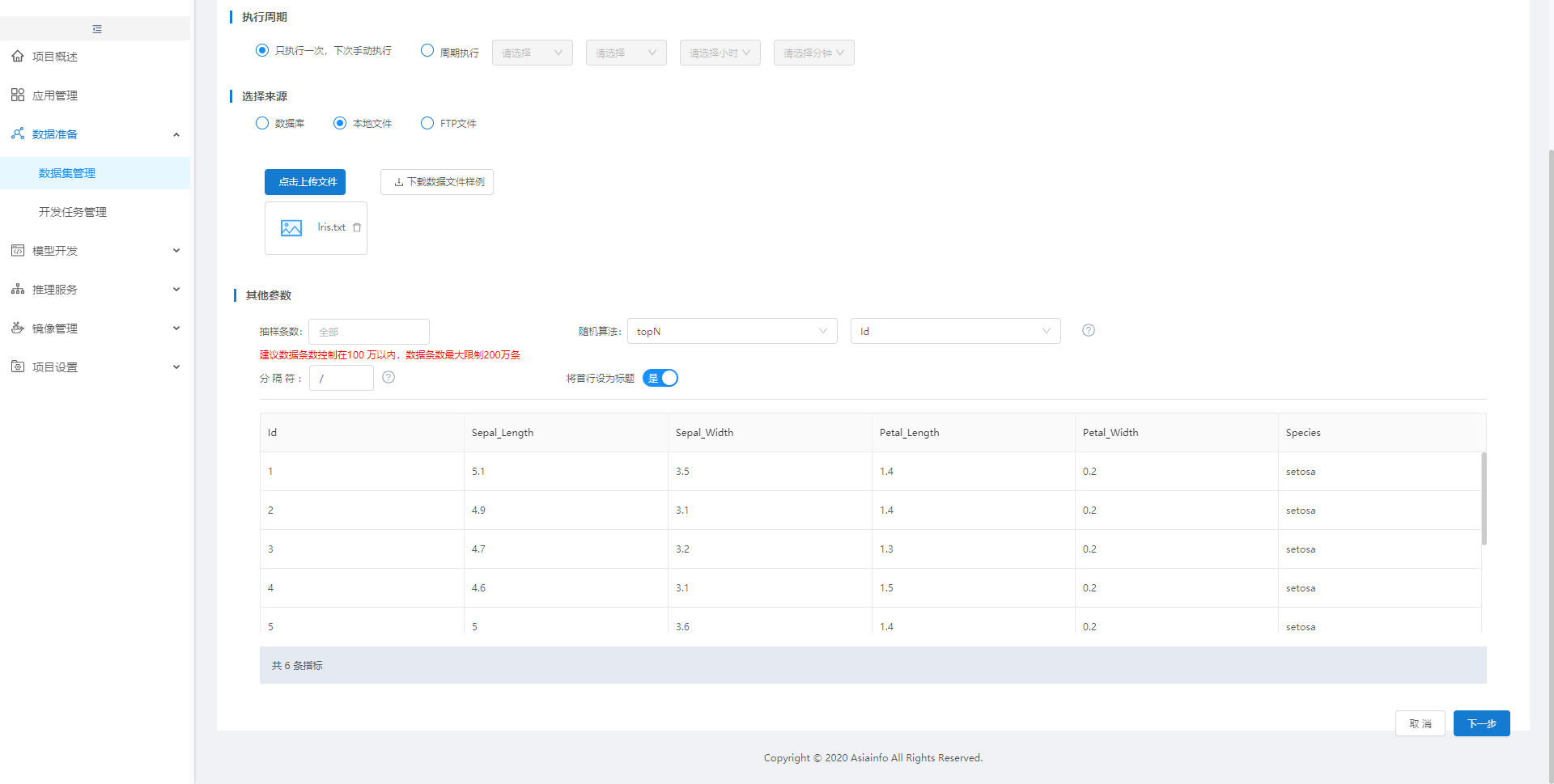
在【应用管理】中点击"鸢尾花"应用的"接入数据集",然后在【数据集管理】中点击"新增结构化",【新增结构化】中,选择"本地文件"并上传准备的鸢尾花文本文件,点击"下一步"再点击"保存"完成鸢尾花数据集的接入:
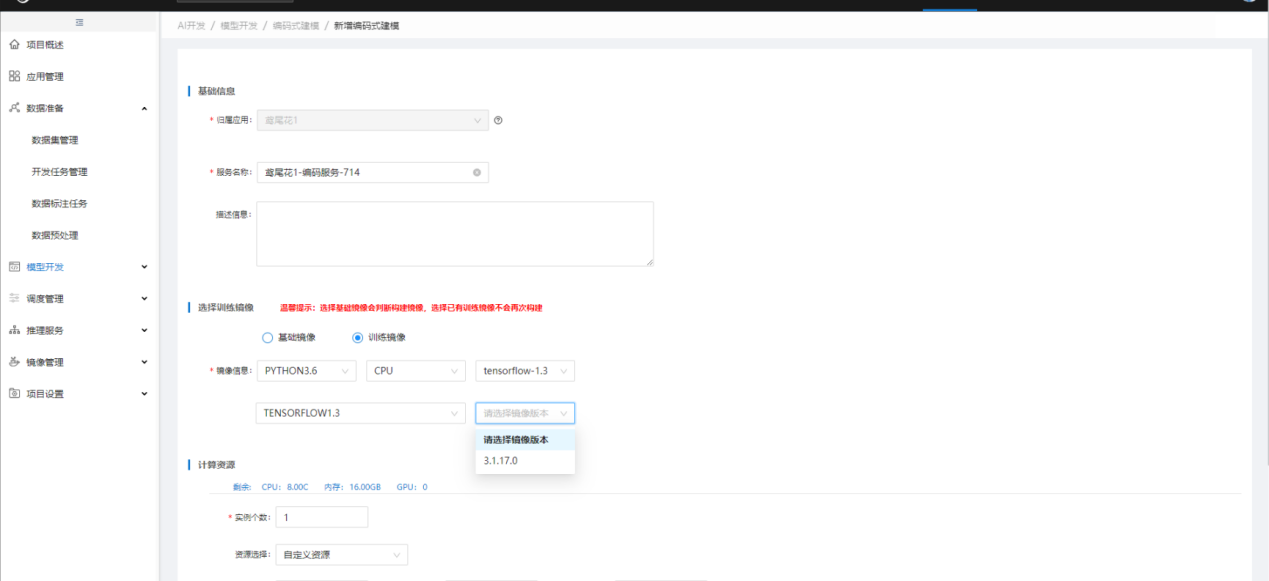
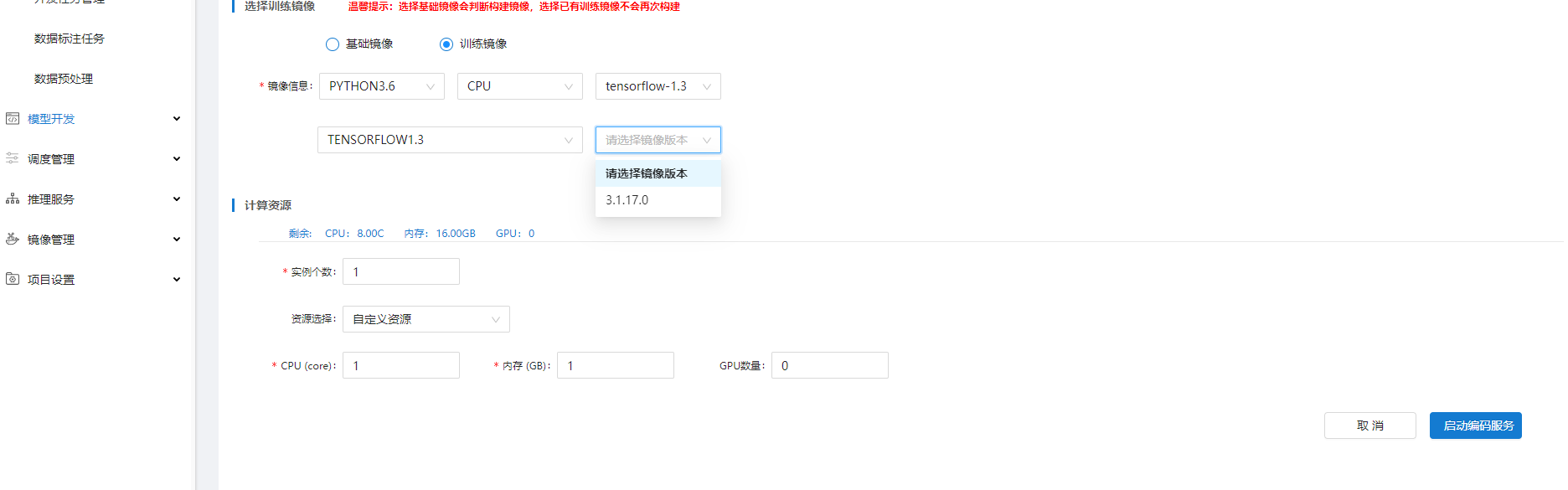
3. 创建鸢尾花应用个人编码服务
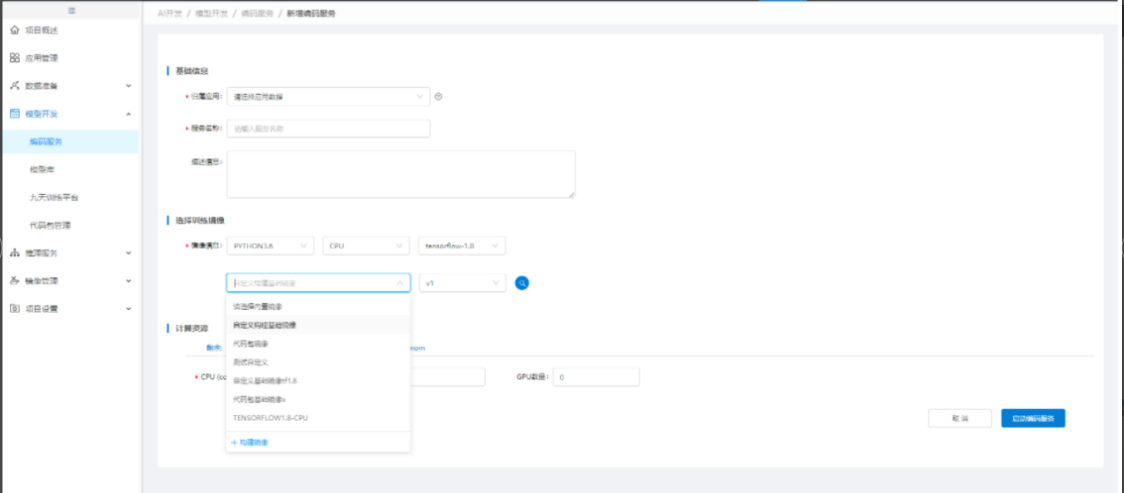
在【编码式建模】中点击"新增编码服务",【新增编码服务】中,选择"鸢尾花"应用,并选择如图所示的"训练镜像"及"计算资源",点击"启动编码服务",完成个人编码服务的创建,等待编码服务启动:
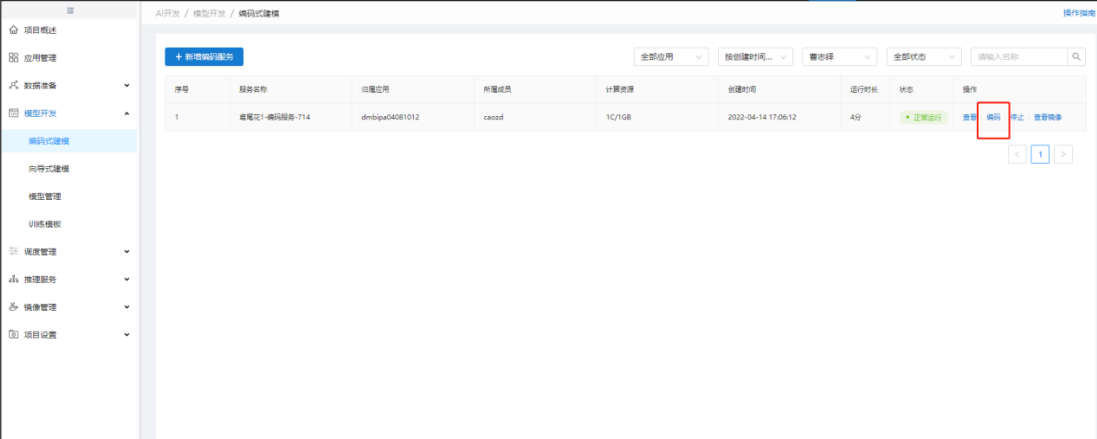
4. 编写鸢尾花模型训练代码
个人编码服务启动成功状态为"正常运行"时,点击"编码"进入【Jupyterlab】:
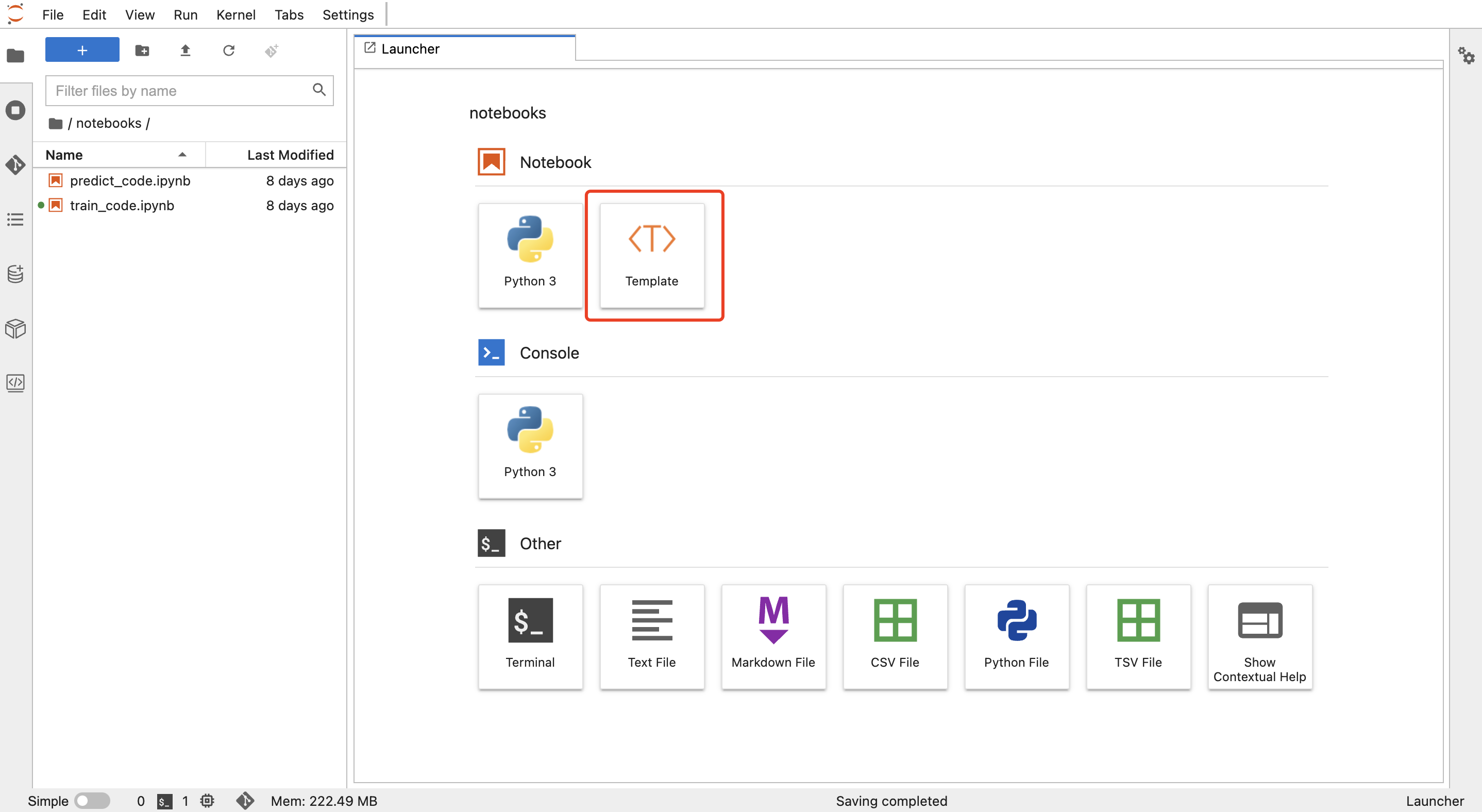
在【Jupyterlab】中,双击左侧文件浏览器插件的"notebooks"进入notebooks文件夹,点击"Template"并选择"ai_template"下的"train_code.ipynb",点击"Go",创建了含有鸢尾花训练代码示例的notebook,

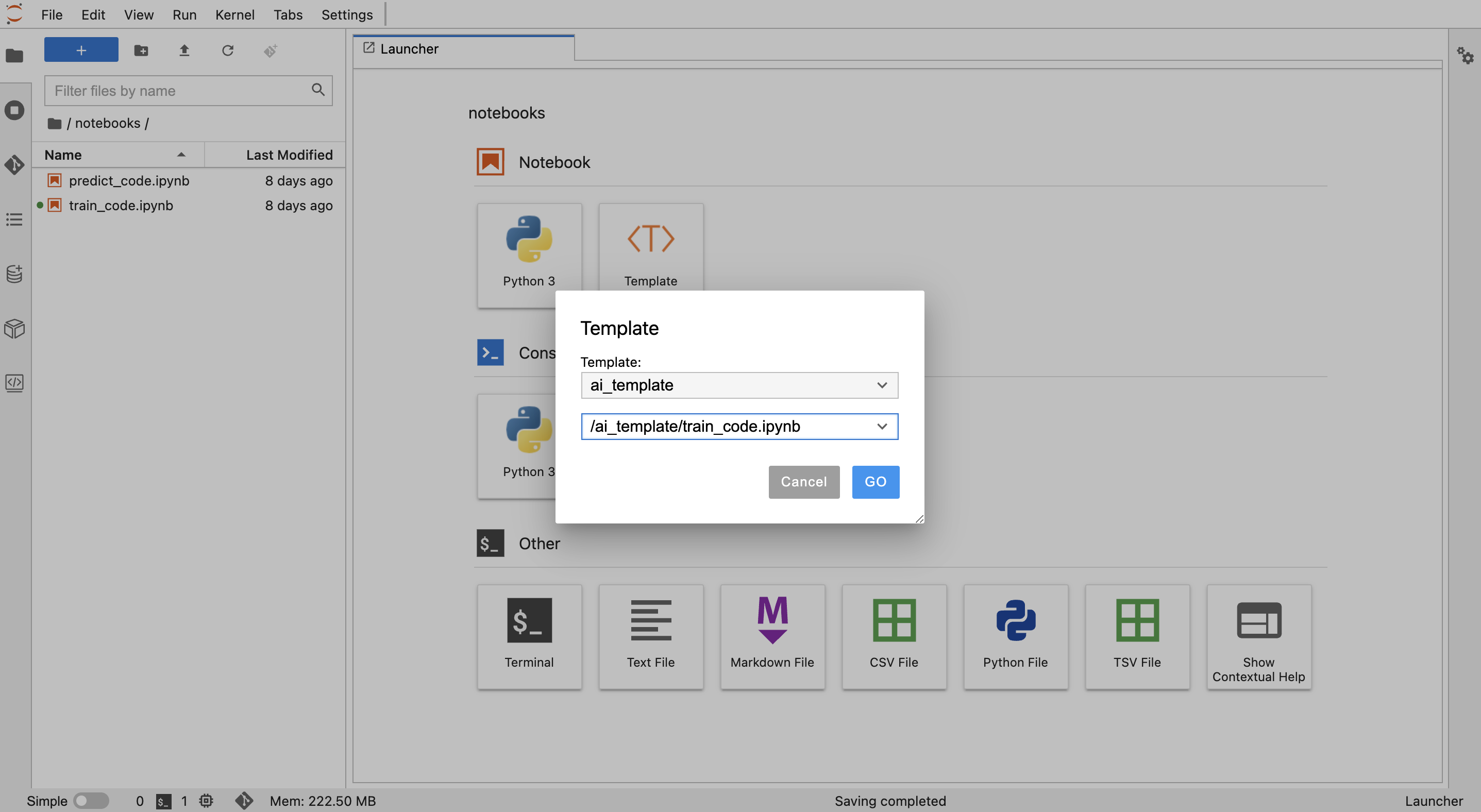
删除示例代码中原有的数据集引用,并点击左侧数据集插件,在接入的鸢尾花数据集的数据周期上,点击"插入代码",在训练代码中引用该数据周期:


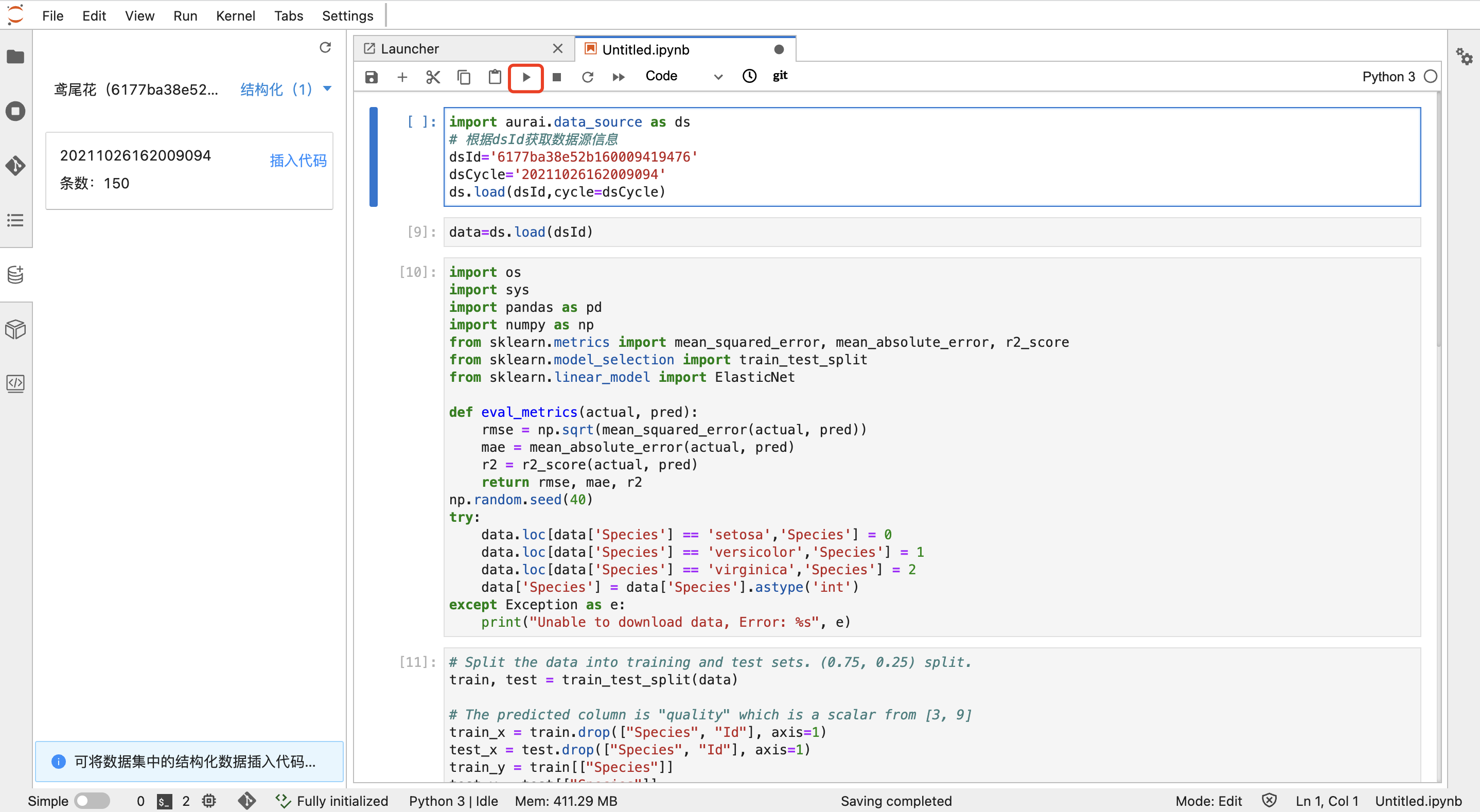
点击编辑栏中的运行图标,运行所有cell,等待模型输出,可在左侧文件浏览器插件中的"model"文件夹中查看示例代码中的模型输出:
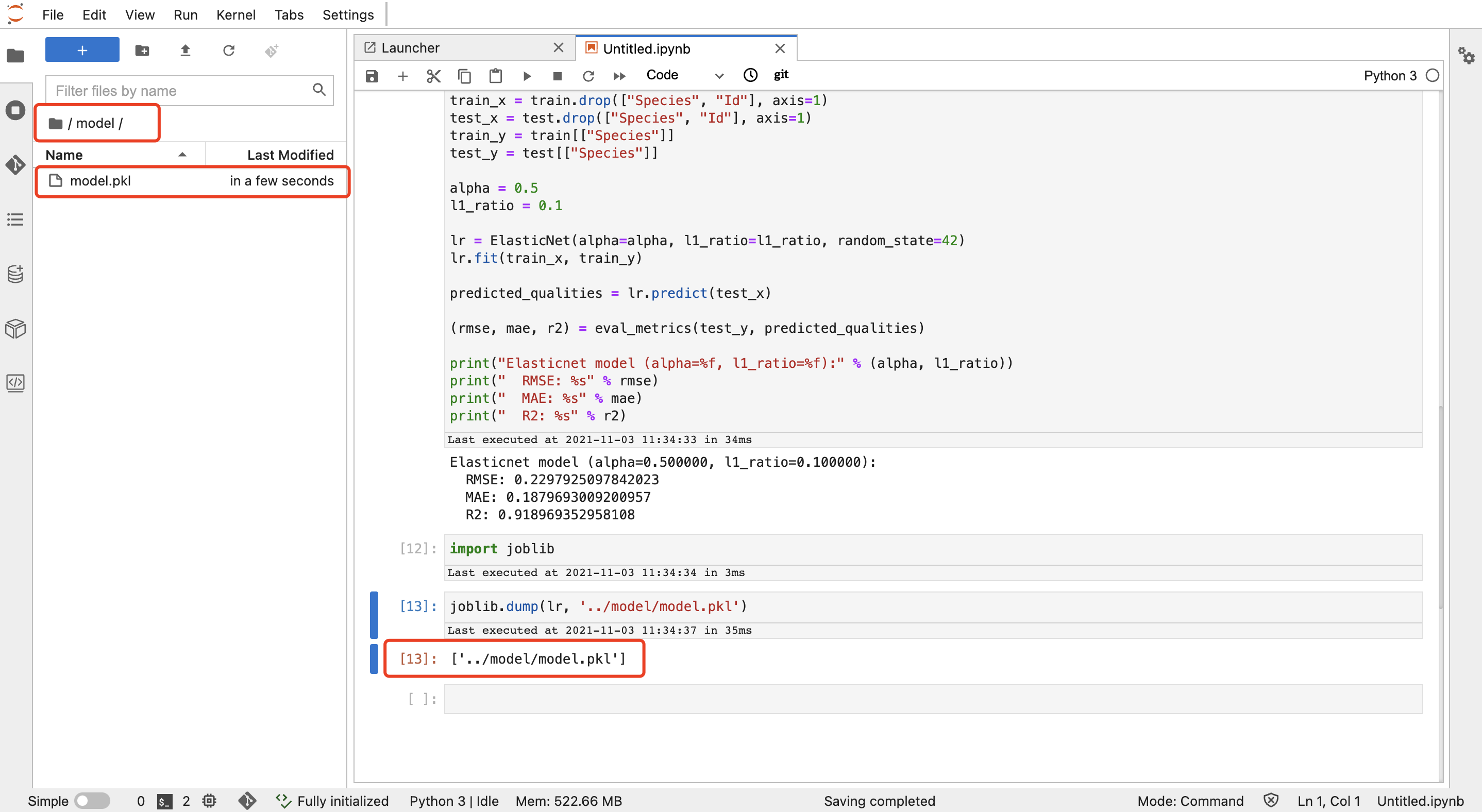
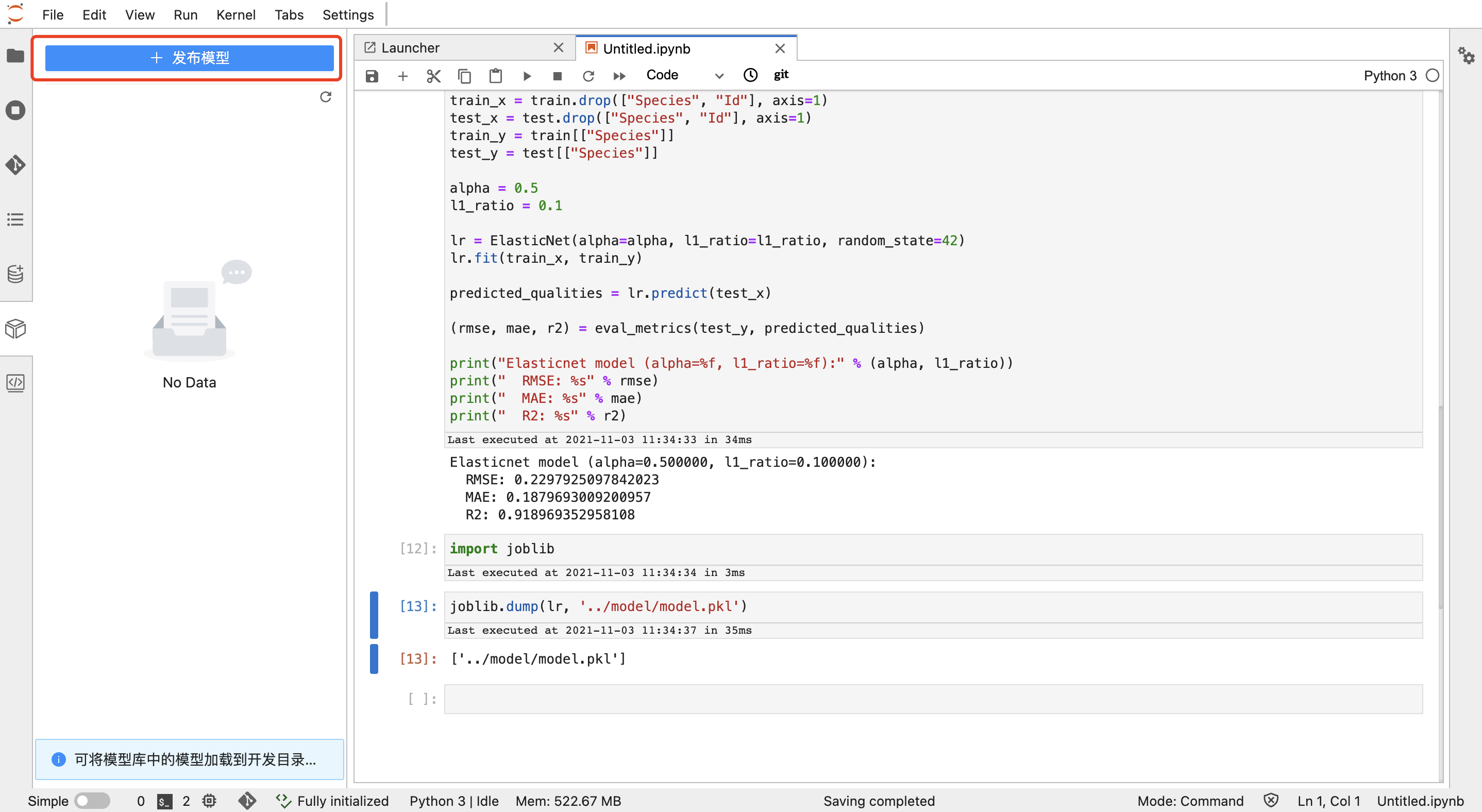
5. 发布鸢尾花模型
鸢尾花模型训练好后,点击左侧模型管理插件,并点击"发布模型"及"确定",在【发布模型】中,按图中选中输出的模型文件,并选择文件类型为"模型文件",点击"保存",完成模型发布:
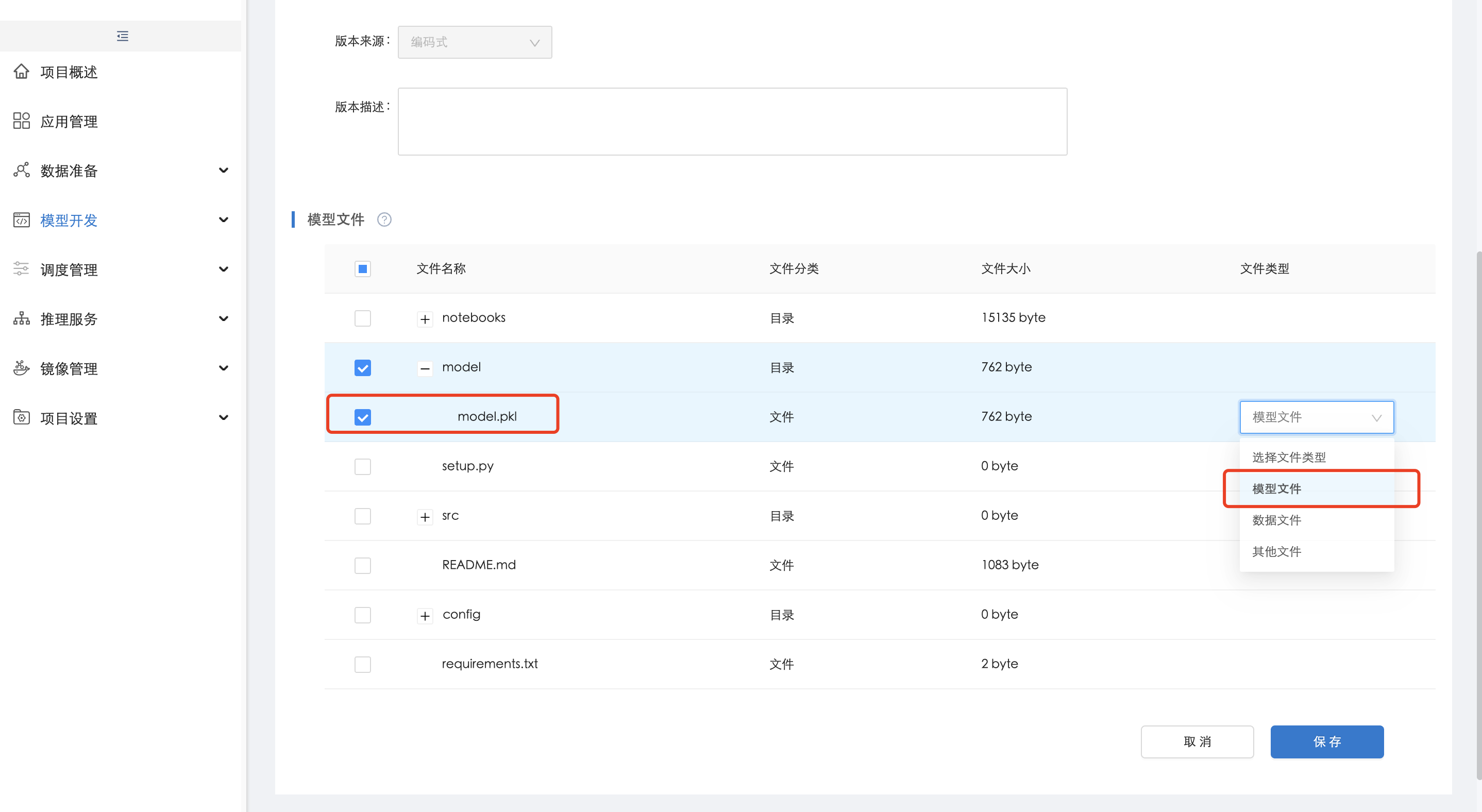
6. 编写鸢尾花模型预测代码
在【Jupyterlab】中,仍然在notebooks文件夹下,点击"Template"并选择"ai_template"下的"predict_code.ipynb",点击"Go",创建了含有鸢尾花预测代码示例的notebook:

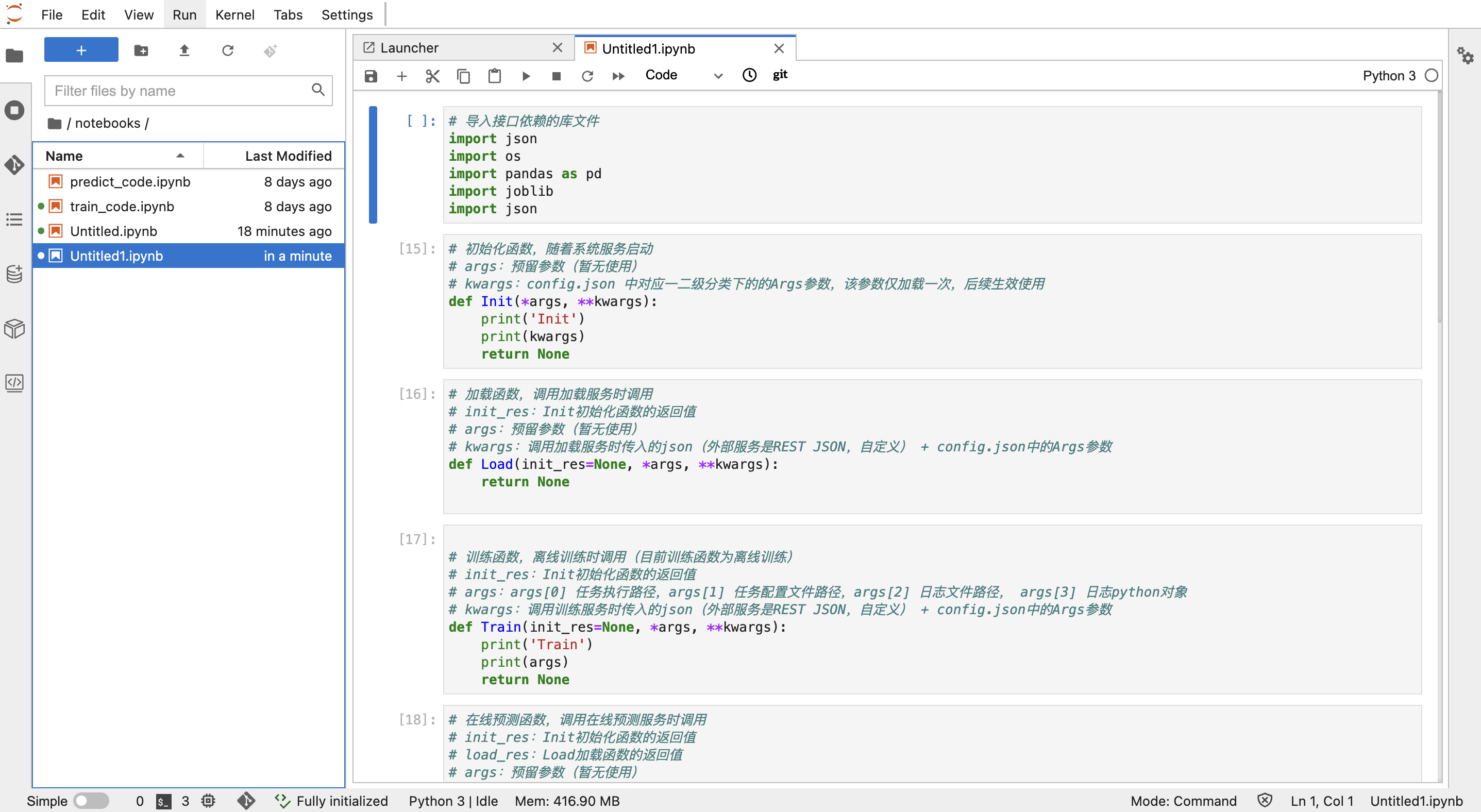
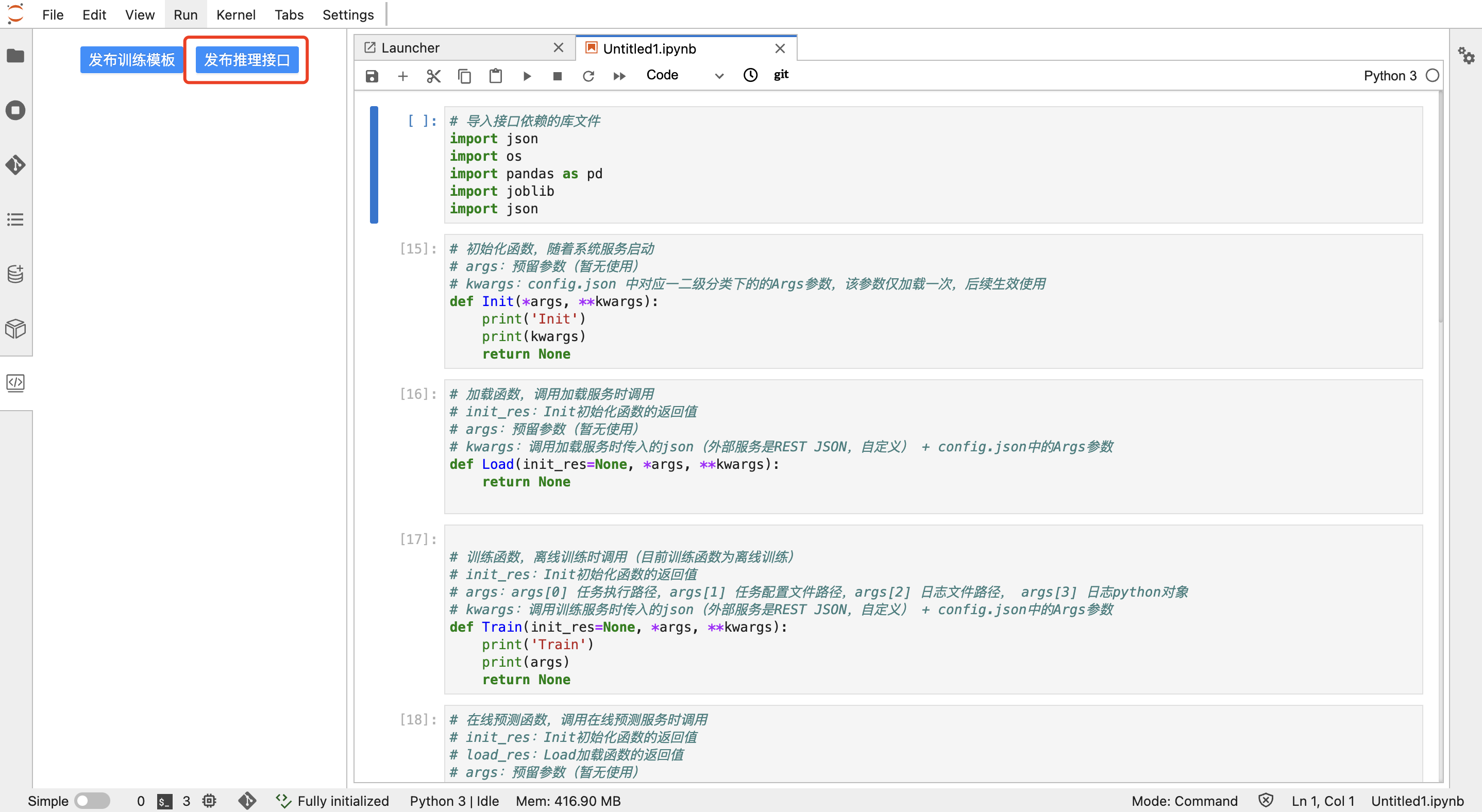
7. 发布推理接口到鸢尾花模型
准备好鸢尾花模型的预测代码后,点击左侧代码管理插件,并点击"发布推理接口"及"确定",在【发布推理接口】中,选择刚才发布的鸢尾花模型,并选择预测代码对应的py格式文件,选择文件类型为"在线推理接口",点击"保存",完成推理接口发布:

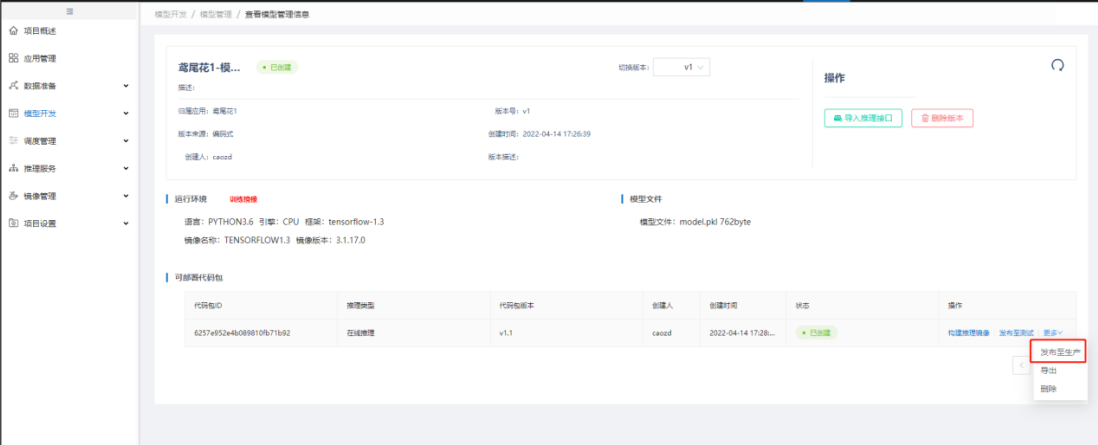
8. 部署鸢尾花在线推理服务
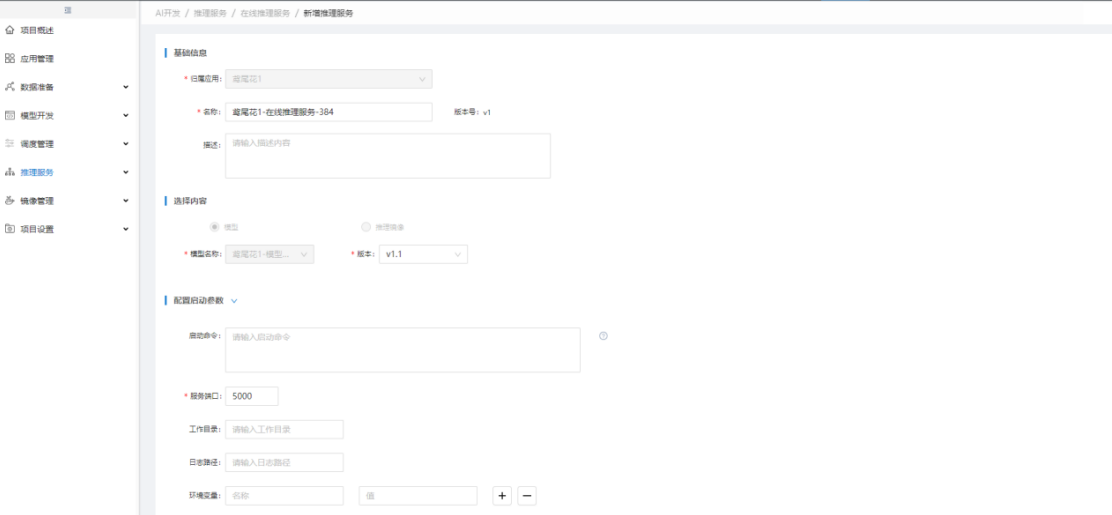
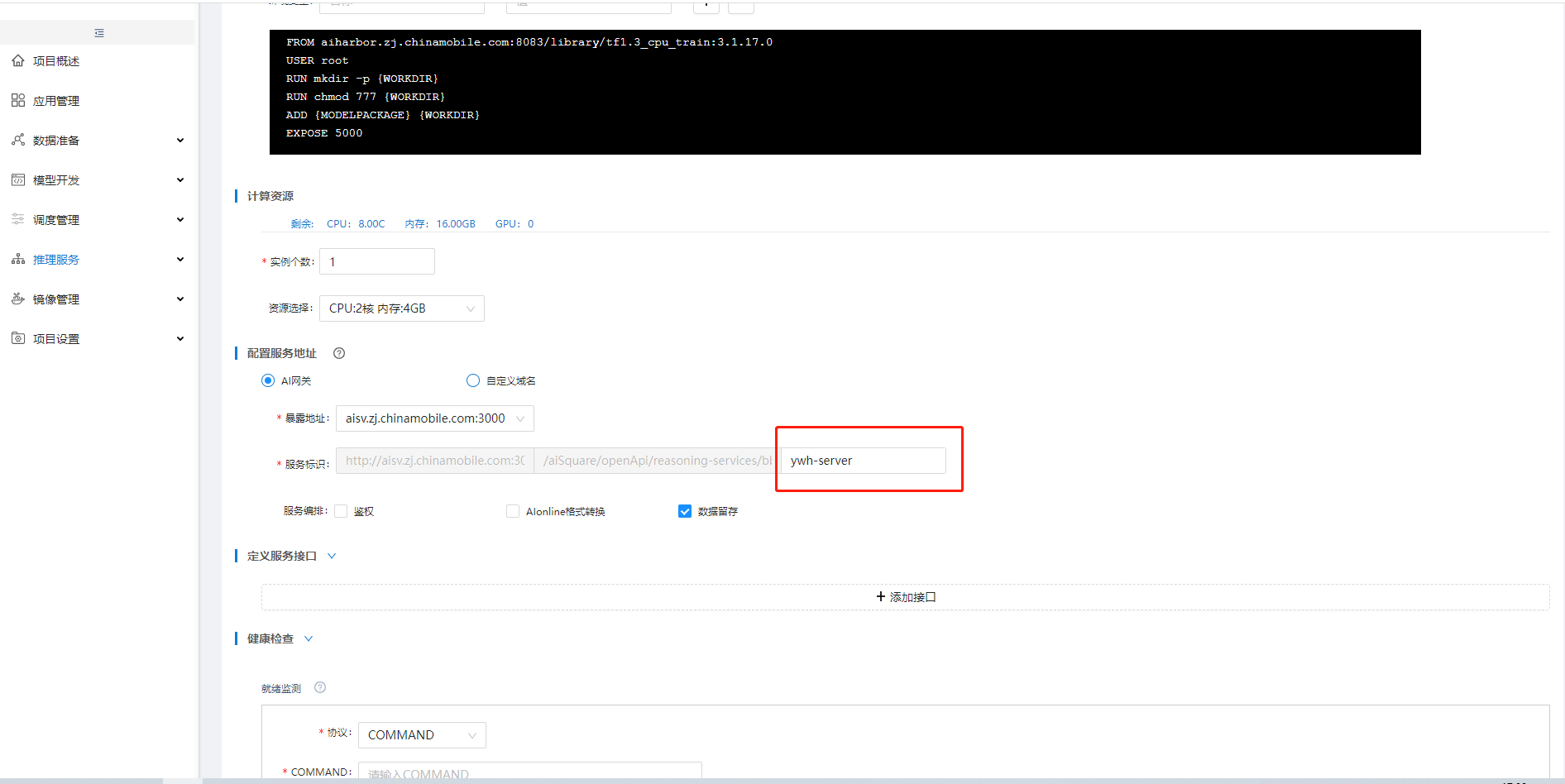
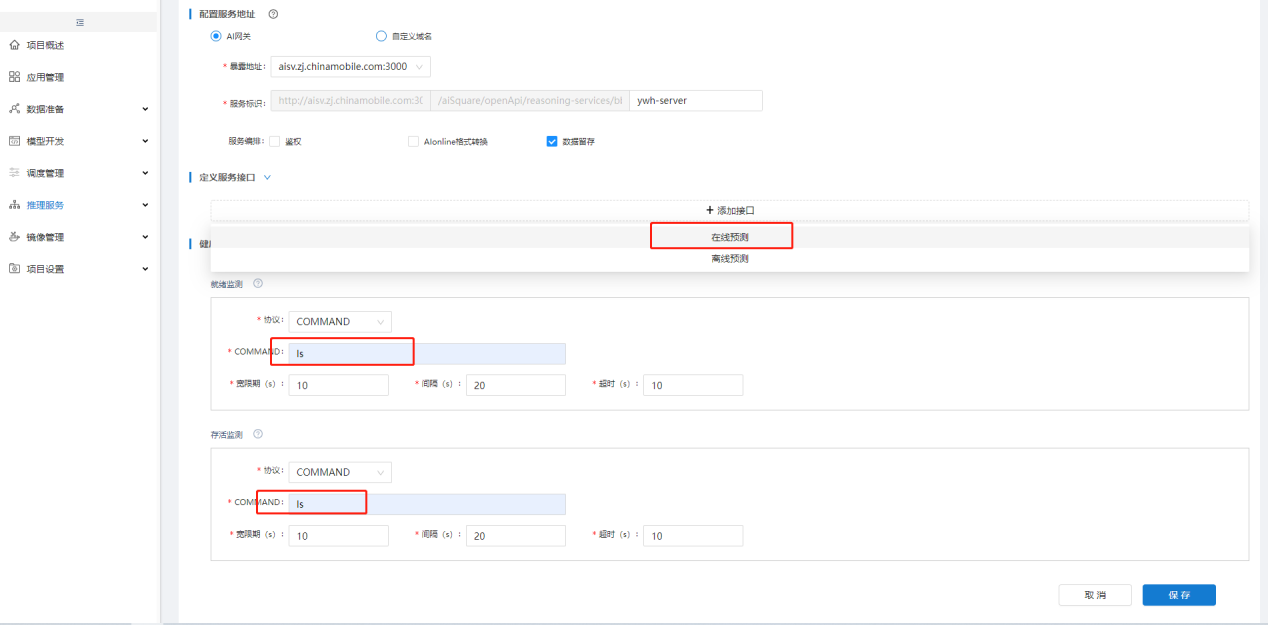
在【模型管理】中,可见发布的鸢尾花模型,点击"查看",【模型详情】中,可见系统自动生成了模型的可部署代码包,点击可部署代码包的"发布至生产",在【新增在线推理】中,"配置服务地址"输入服务唯一标识,"定义服务接口"点击"添加接口"并选择"在线推理","健康检查"输入"ls"命令,点击"保存",完成在线推理服务部署,等待服务启动:
9. 测试鸢尾花在线推理服务API
鸢尾花在线推理服务启动成功状态为"正常运行"时,点击"查看",在【在线推理服务详情】中,点击"输入输出"中的"试一试",并点击"Try it out":
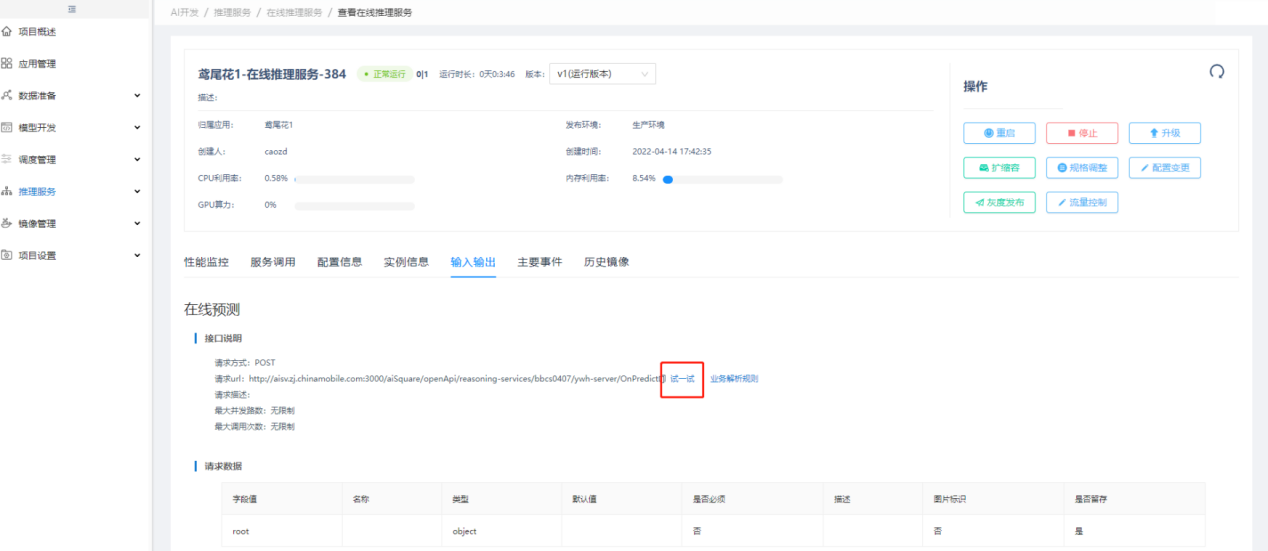
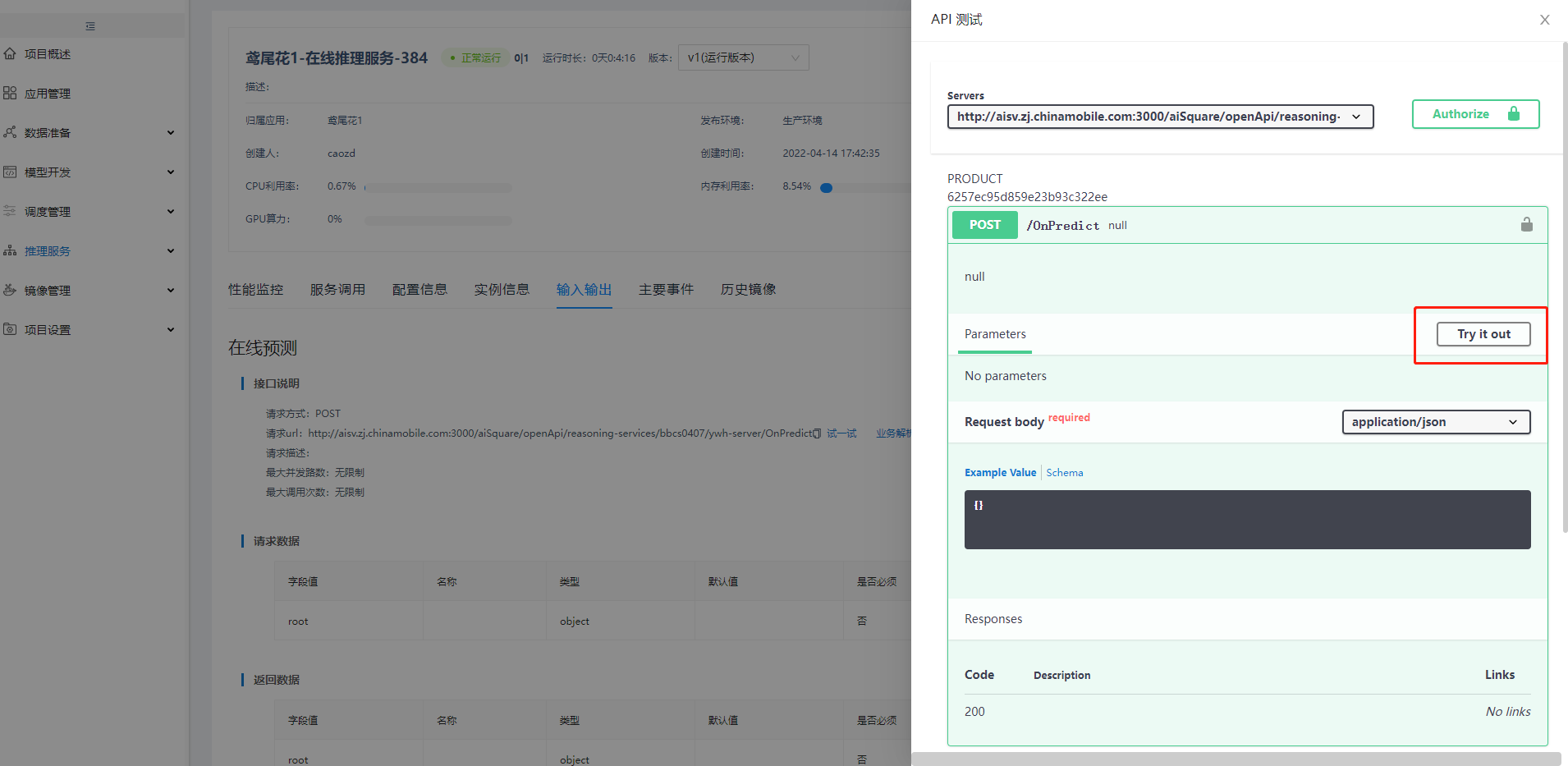
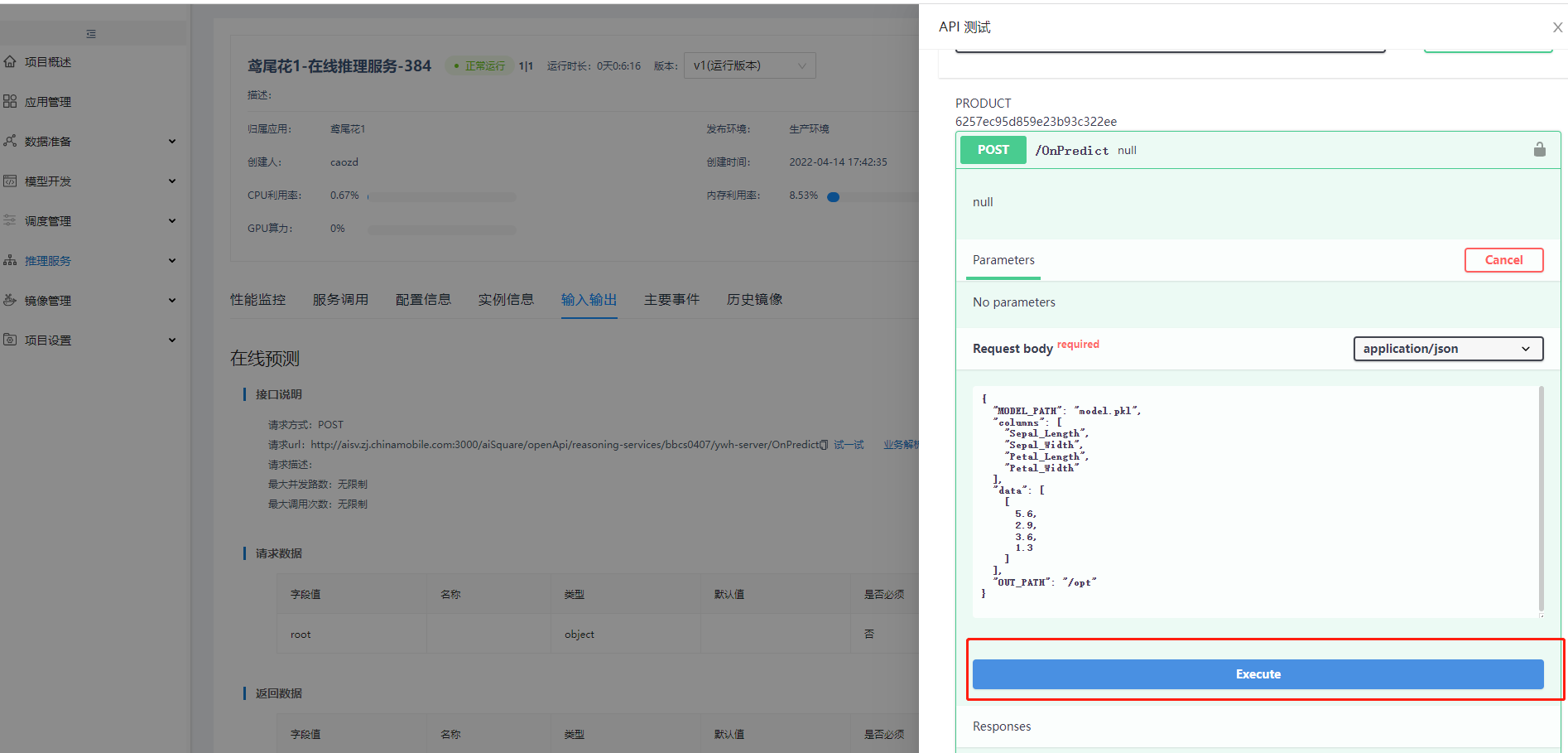
弹窗中,"Request body"输入以下入参,并点击"Execute",可见预测结果:
{
\"MODEL_PATH\": \"model.pkl\",
\"columns\": [
\"Sepal_Length\",
\"Sepal_Width\",
\"Petal_Length\",
\"Petal_Width\"
],
\"data\": [
[
5.6,
2.9,
3.6,
1.3
]
],
\"OUT_PATH\": \"/opt\"
}

1.4. 常见问题
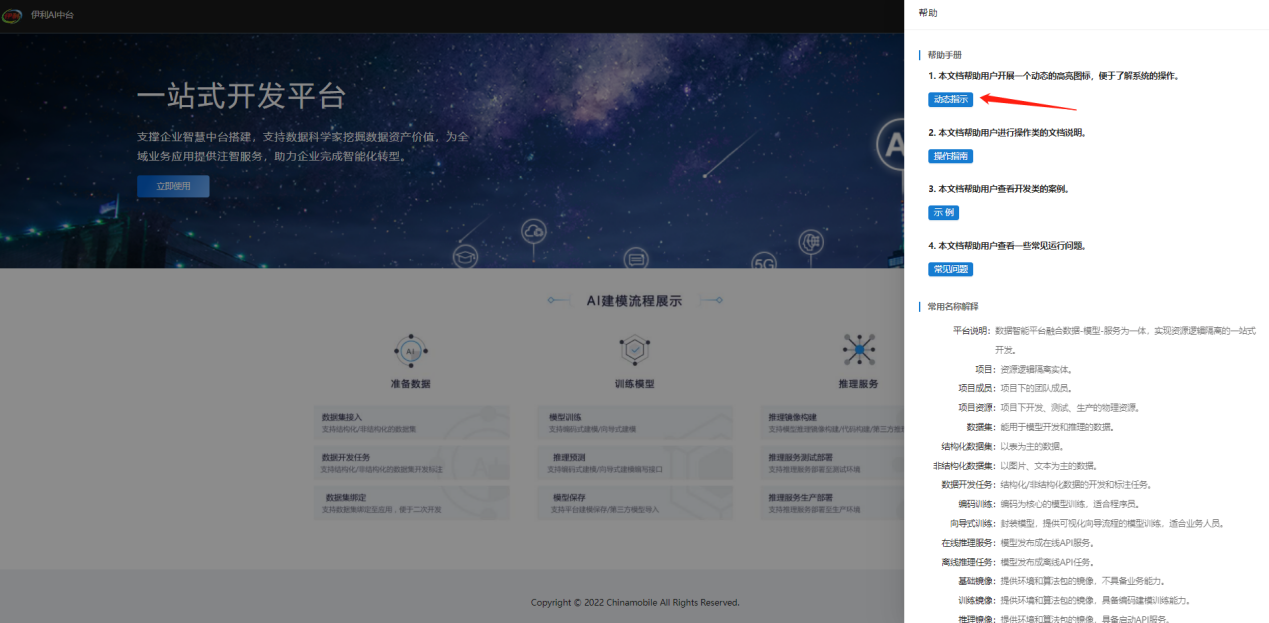
1. 新用户第一次使用系统,对系统不熟练,如何查看新手导航?
答:登录系统页面head页(登录前后均可)的右上方有一个"帮助"按钮,点击后,展开一个新窗口,再点击"动态指引",即可进行流程的介绍。
2. 用户如何开始第一份代码的编写,如何查看示例?
答:登录系统页面head页(登录前后均可)的右上方有一个"帮助"按钮,点击后,展开一个新窗口,再点击"示例",即可查看一份实例代码。

3. 导入的数据在能否还能看到原始数据?
答:当前在"数据准备-数据集管理"里列表点击"修改",结构化数据可看到最新上传的一份数据情况,非结构化数据无法展示。
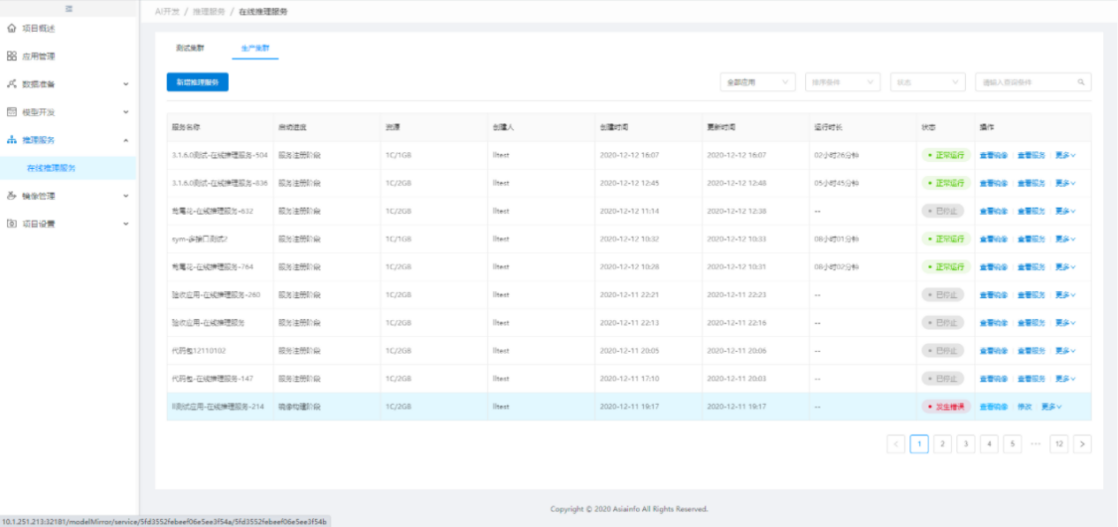
推理服务如果发布失败了,构建的镜像是否也没有了?
答:推理服务如果在构建镜像阶段失败了,镜像状态可以通过推理服务的"查看镜像"去点击查看,也可以直接查看"推理镜像管理"里的推理镜像进行查看。
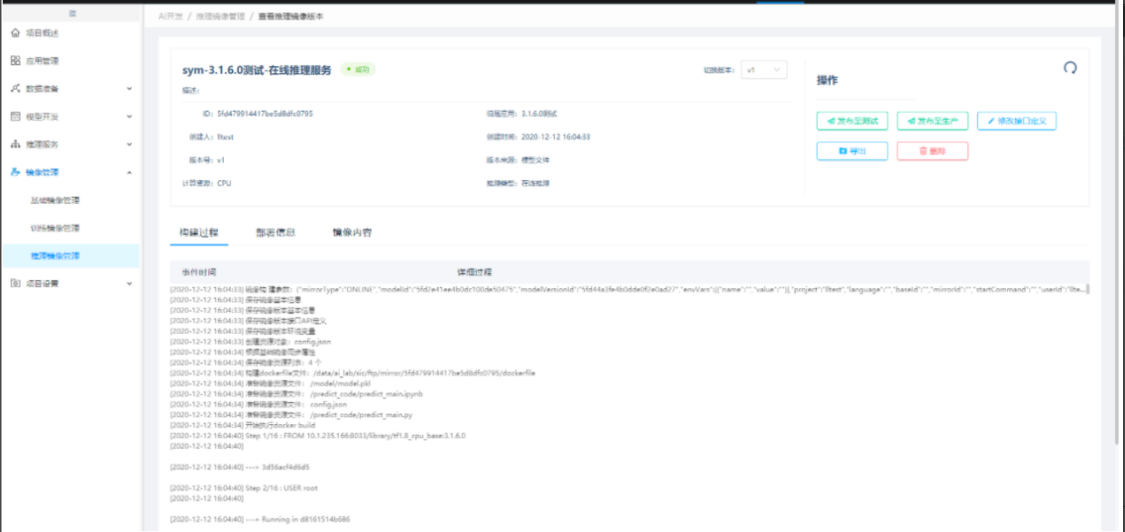
5. 编码式建模时发现训练镜像不满足训练条件,如何重新构建训练镜像?
答:通过"基础镜像管理"的自定义基础镜像,构建出的基础镜像会自动生成一个训练镜像(名称与基础镜像一致),后续在编码建模的时候直接按基础镜像构建的框架选择即可。
6. 如何用jupyterLab装依赖包?
答:方式一 jupyter页面requirements文件安装
在jupyterlab目录中选择requirements文件,填写需要安装的依赖包,格式参考如下,多个依赖包请换行:
pyspark == 2.3.1
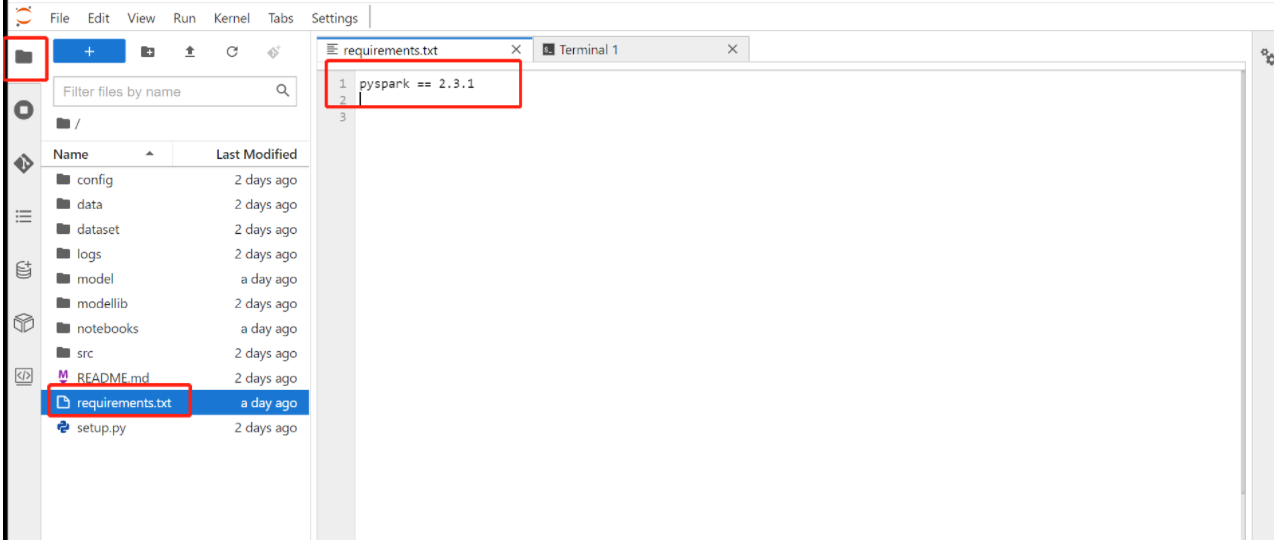
Ctrl+S保存
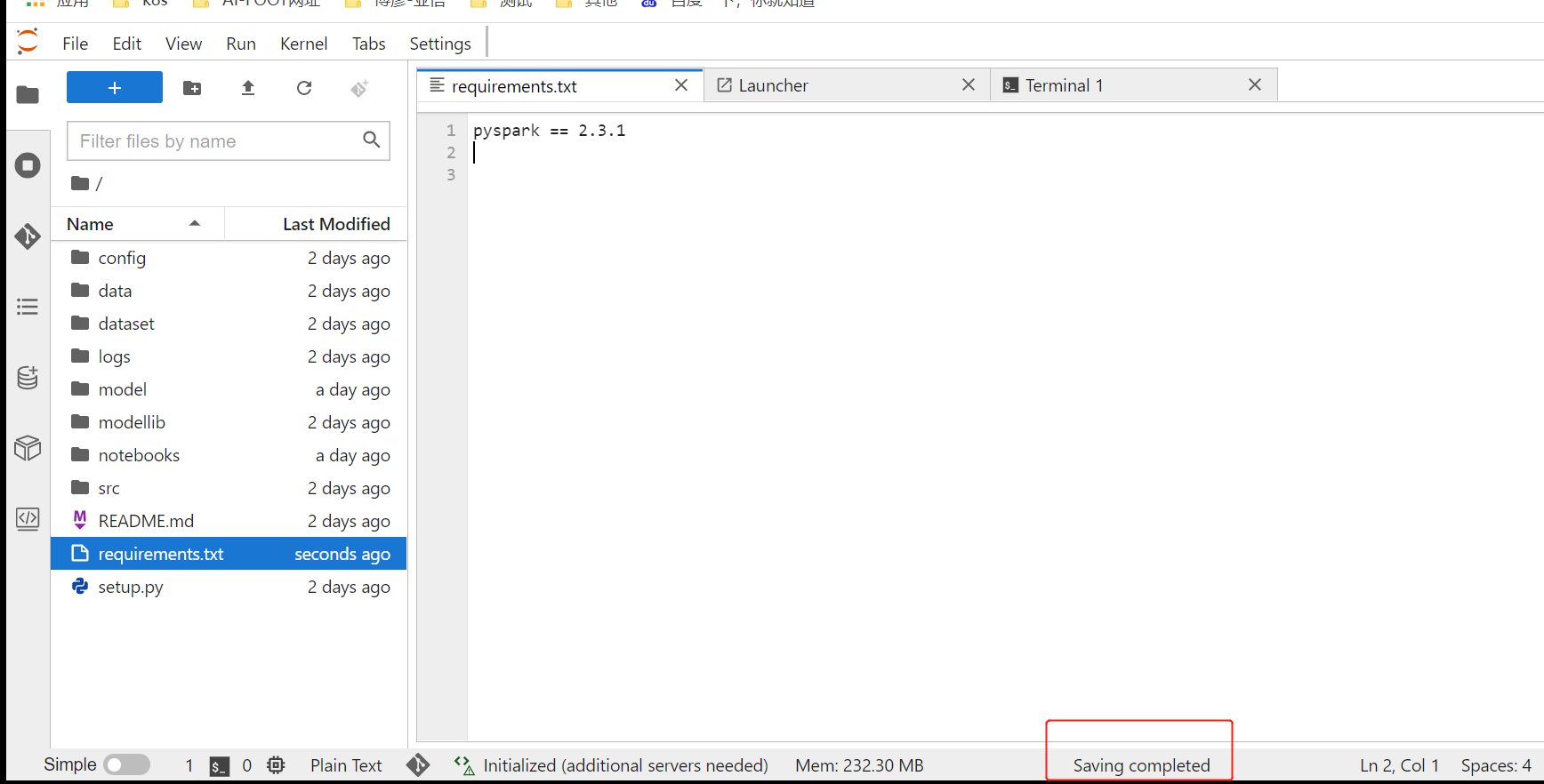
保存requirements文件后,切换到git区域,添加文件到暂存区域
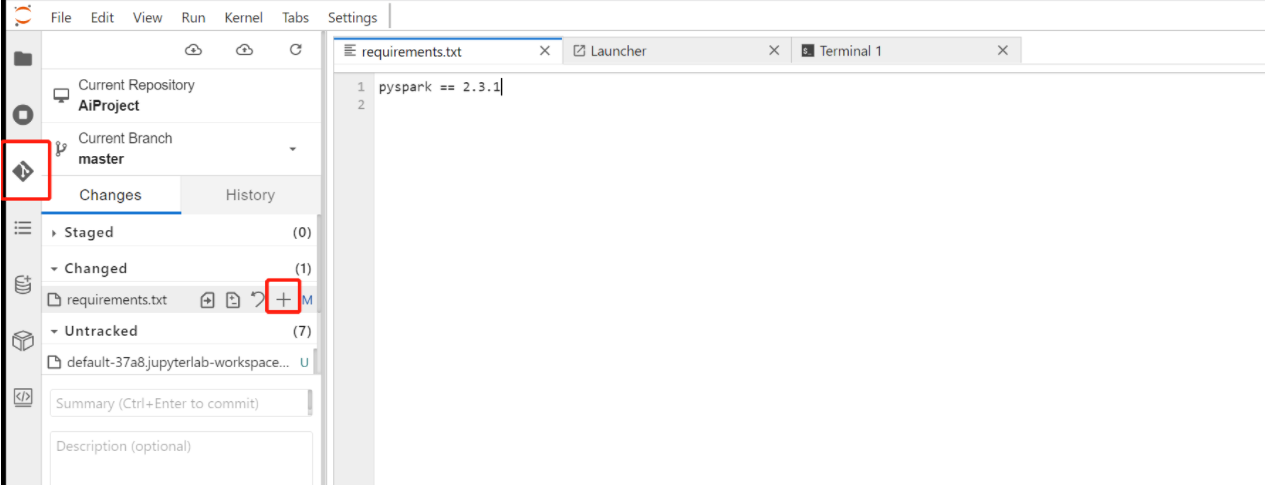
requirements文件提交到已暂存后,填写摘要信息、描述信息,提交
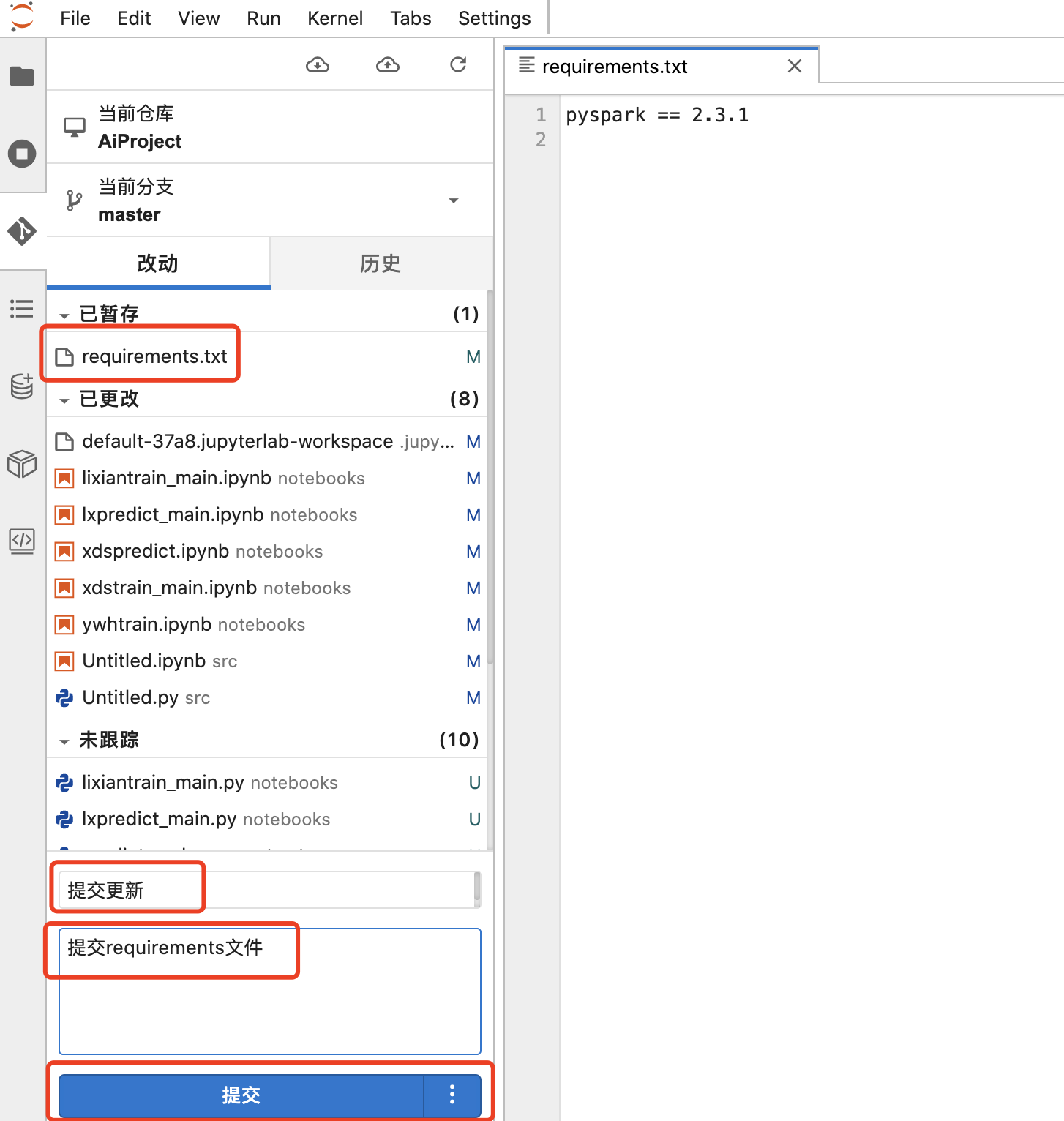
requirements文件提交成功后,点击推送按钮,推送到git
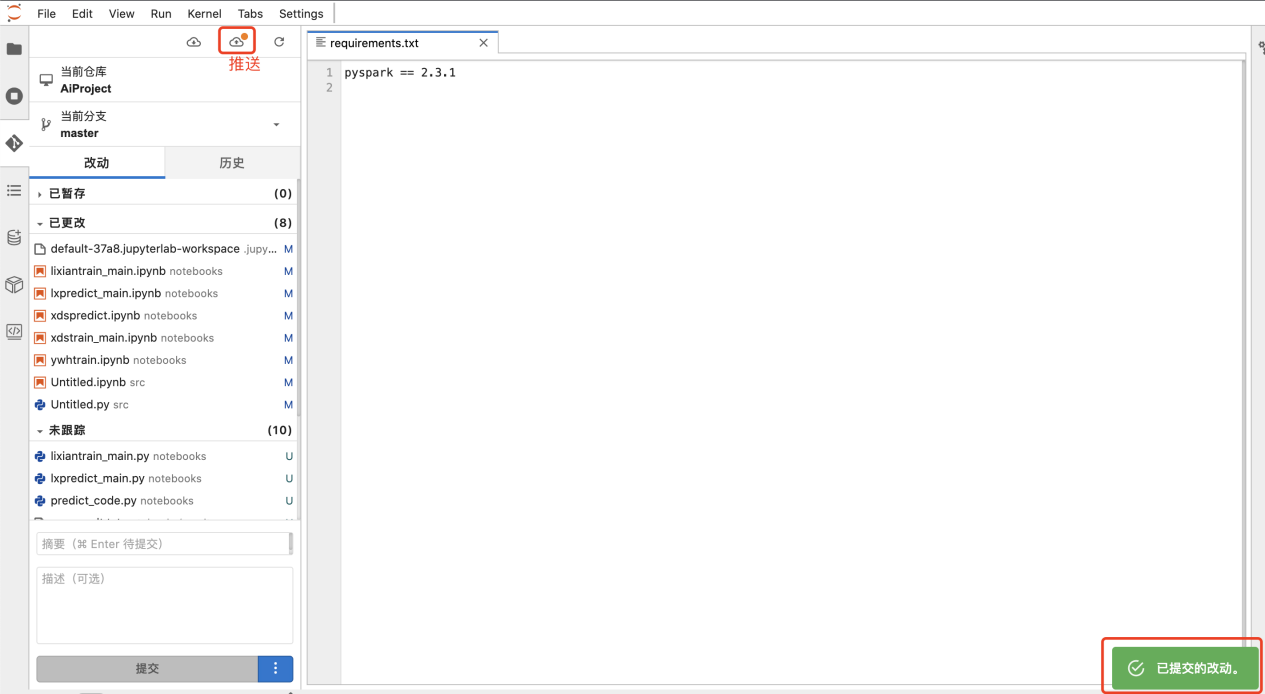
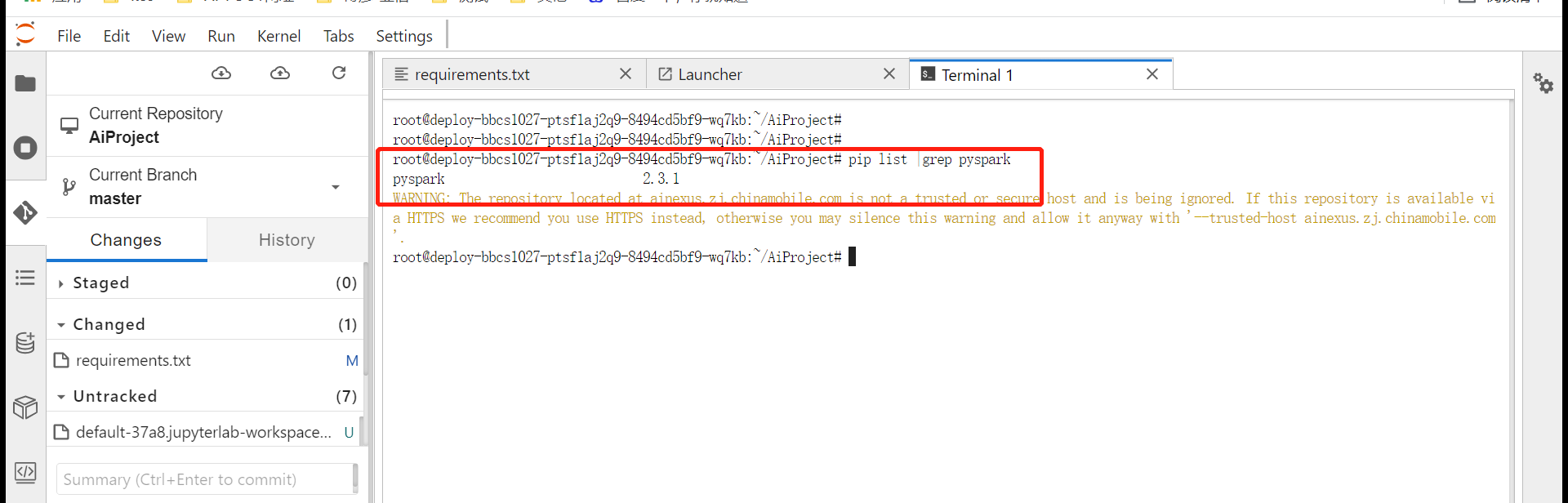
重启编码服务后会自动安装requirements文件中的依赖包(可以在容器中或者jupyterlab的终端执行pip list | grep 查看安装包和安装的版本)
方式二 打开终端直接输入pip install 命令安装依赖包
安装成功后直接查看确认。

安装成功后仅针对该编码服务,如果用方式二安装,则每次重启都要在终端重新安装,方式一安装,重启后依赖包不用重新安装。
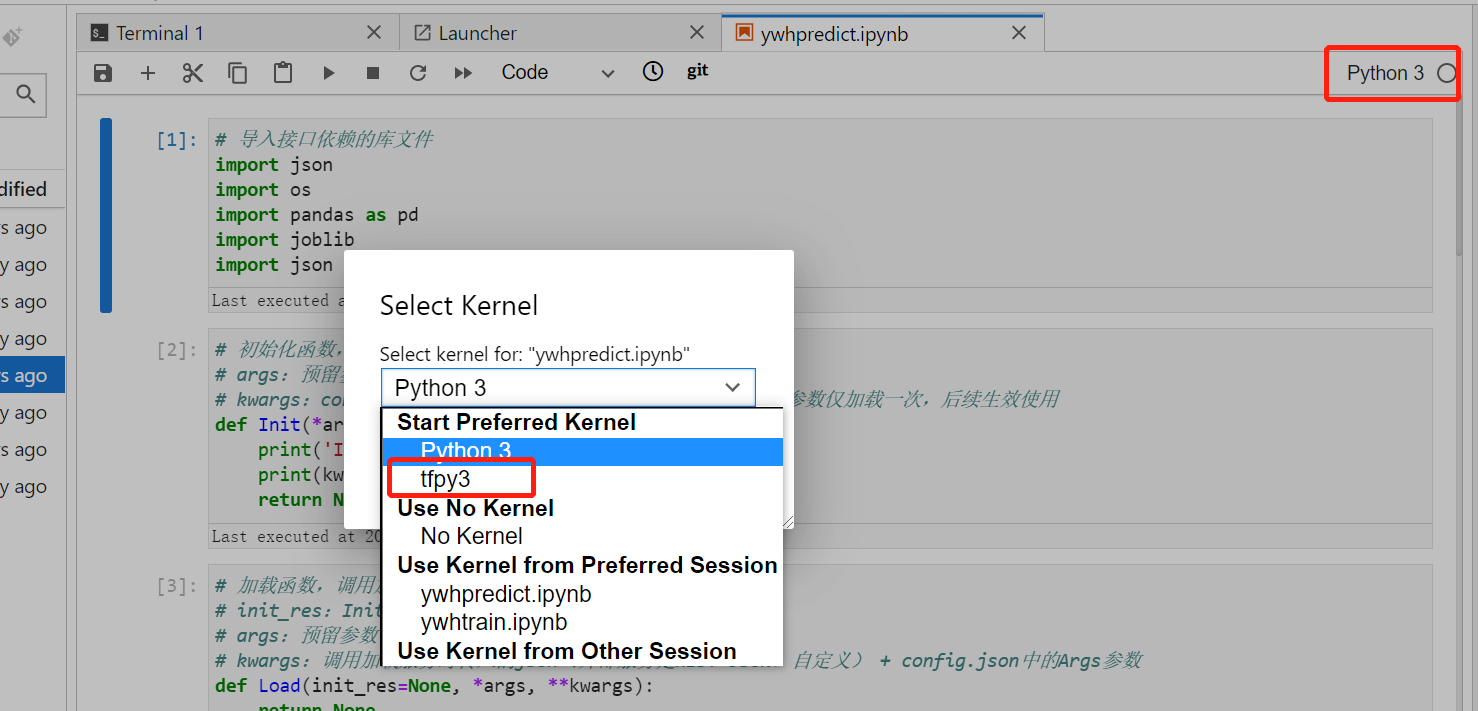
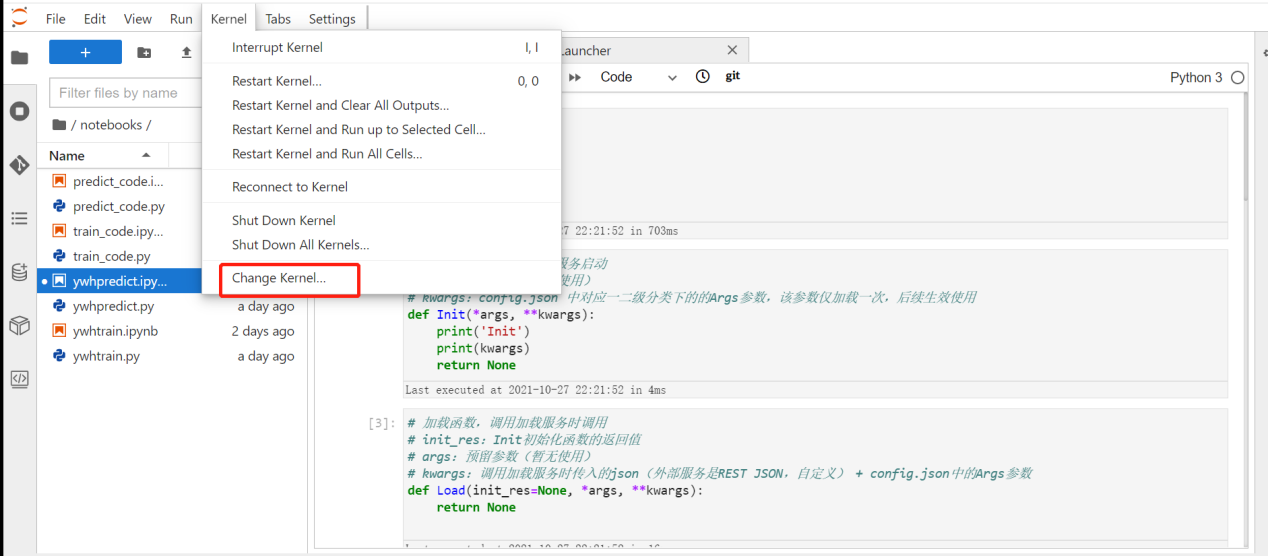
7. 如何在jupyter页面安装其他环境?
答:进入jupyter页面点击终端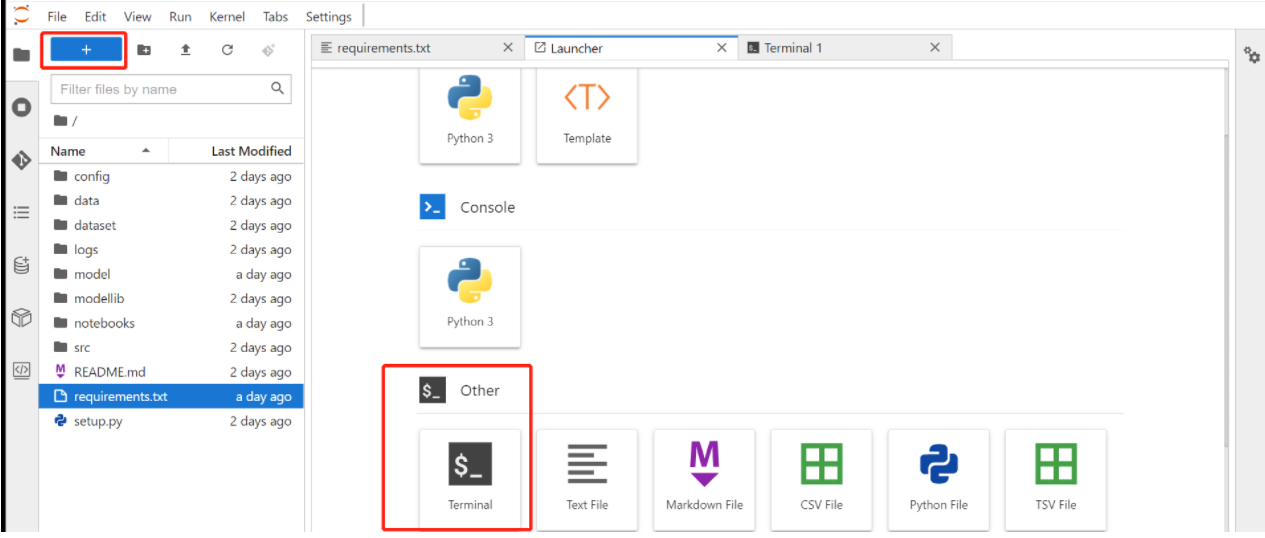
pip安装内核环境,例:
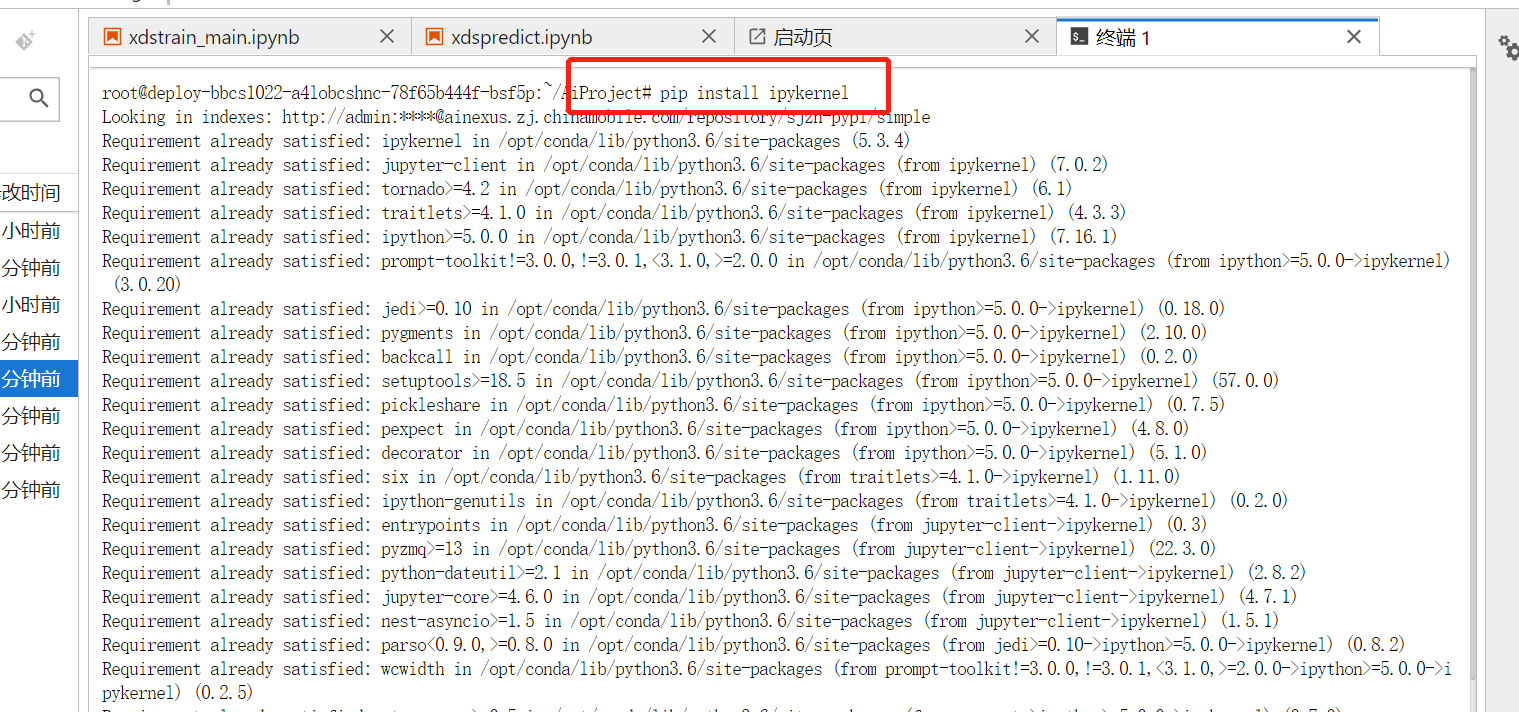
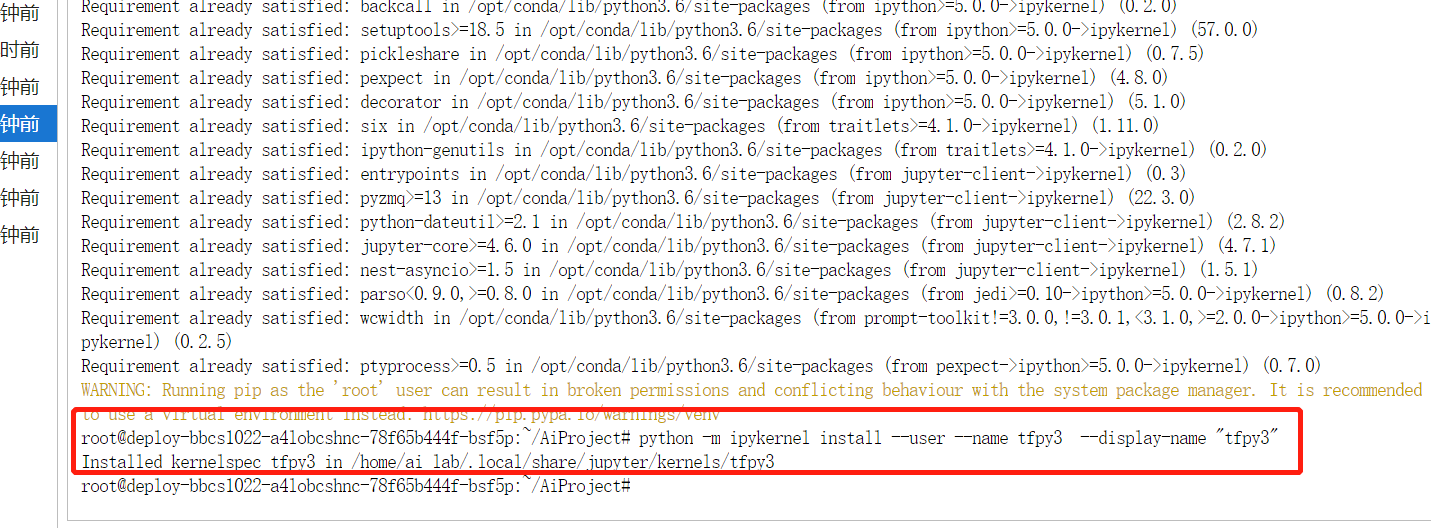
进入启动页可以看到新增的自定义语言。
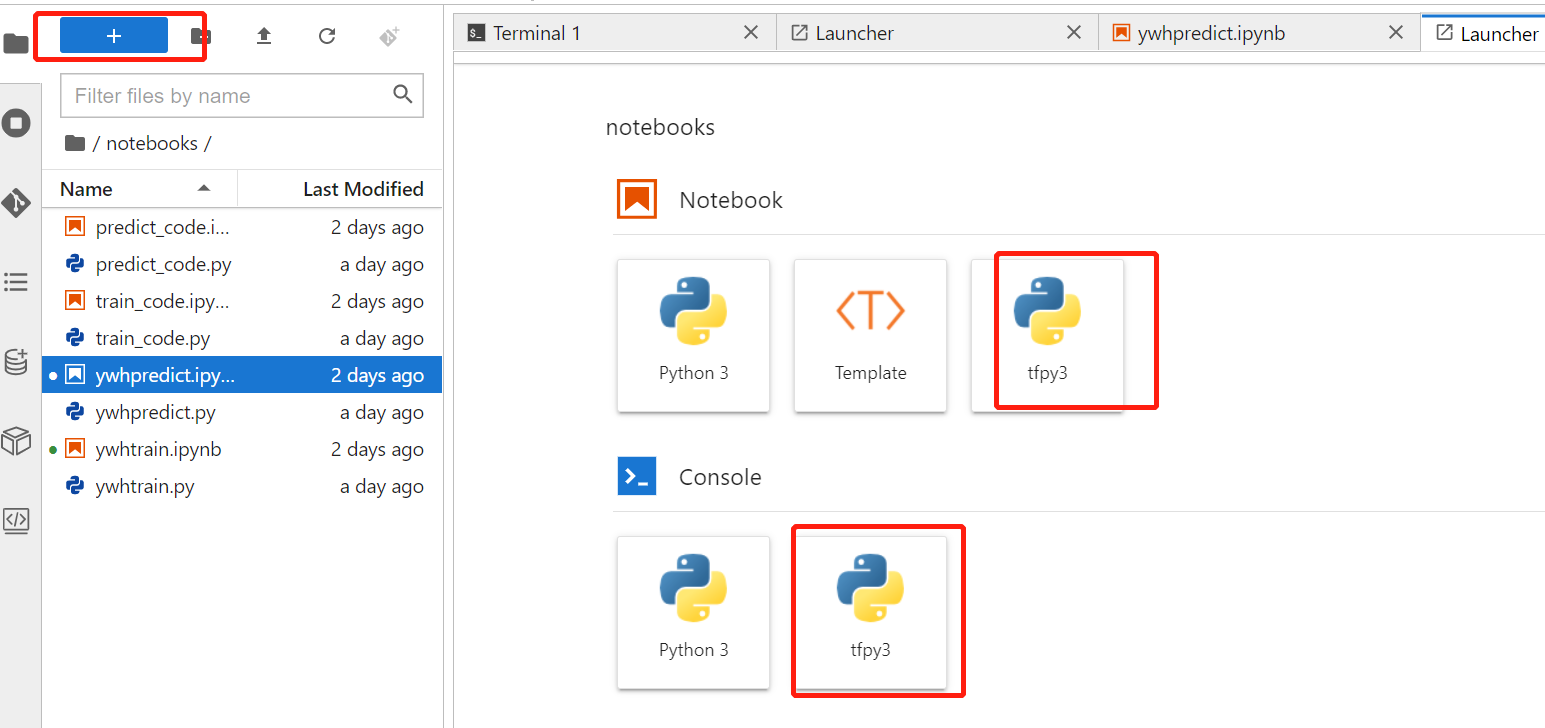
在代码页点击右上角切换语言,或点击kernel组件里的change kernel切换。重启后需要重新安装。
8. 未完待续
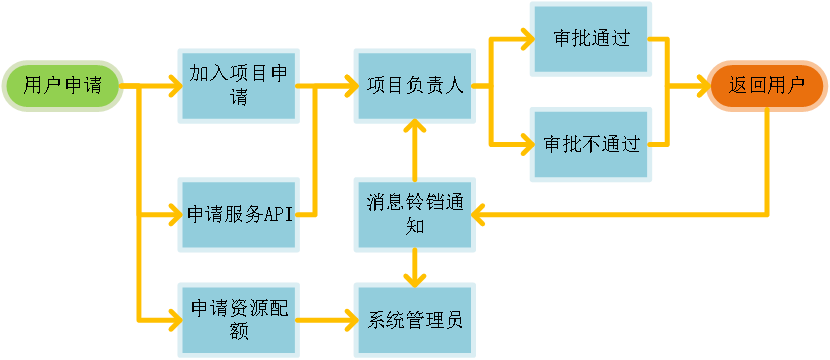
1.5. 项目设置
用户项目相关的申请,主要包括项目下加入申请、资源配额申请、及其API服务申请,项目负责人审批加入和API,系统管理员审批资源配额。
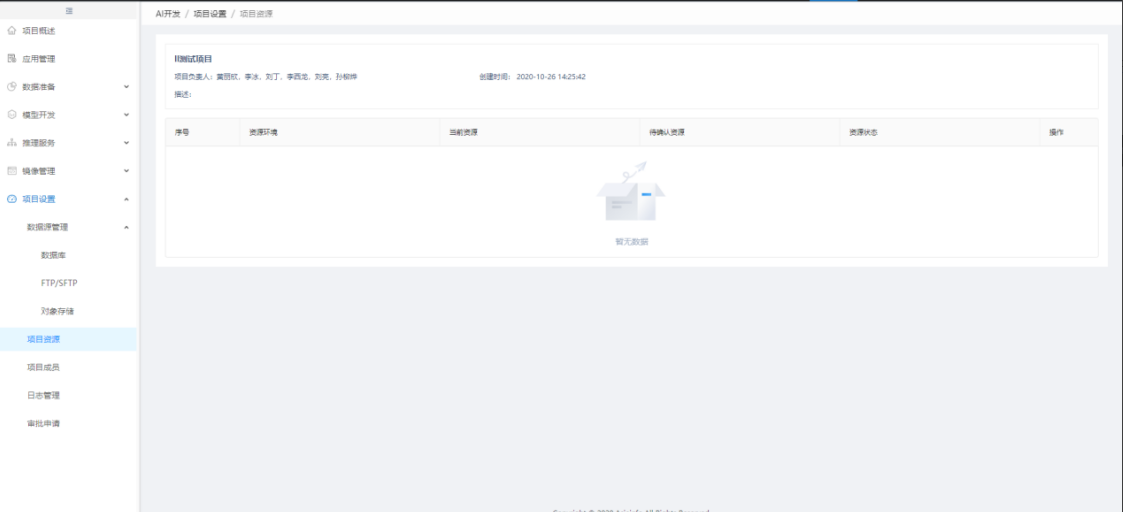
1.5.1. 项目资源
当前项目下的资源申请,主要是项目负责人对系统默认的资源进行额外资源变更申请。(现有资源情况暂在项目概览可查看到)
下图为管理员视角下可查看到的项目申请审批记录。(用于参考)
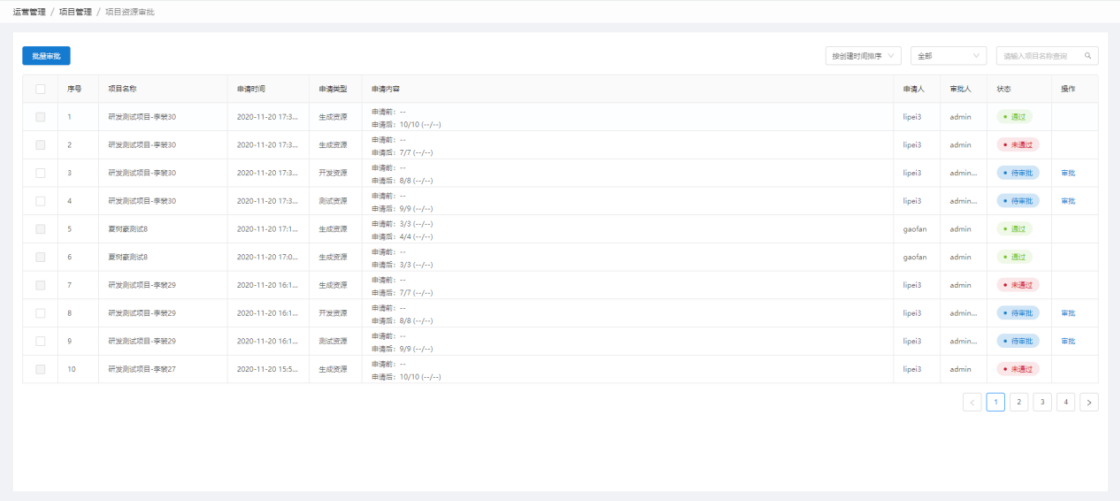
1.5.2. 项目成员
当前项目下的成员情况,项目负责人可以添加成员和成员身份。

1.5.3. 申请审批
当前项目下的项目申请情况,包括自身对外的申请记录和需自身审批的记录。

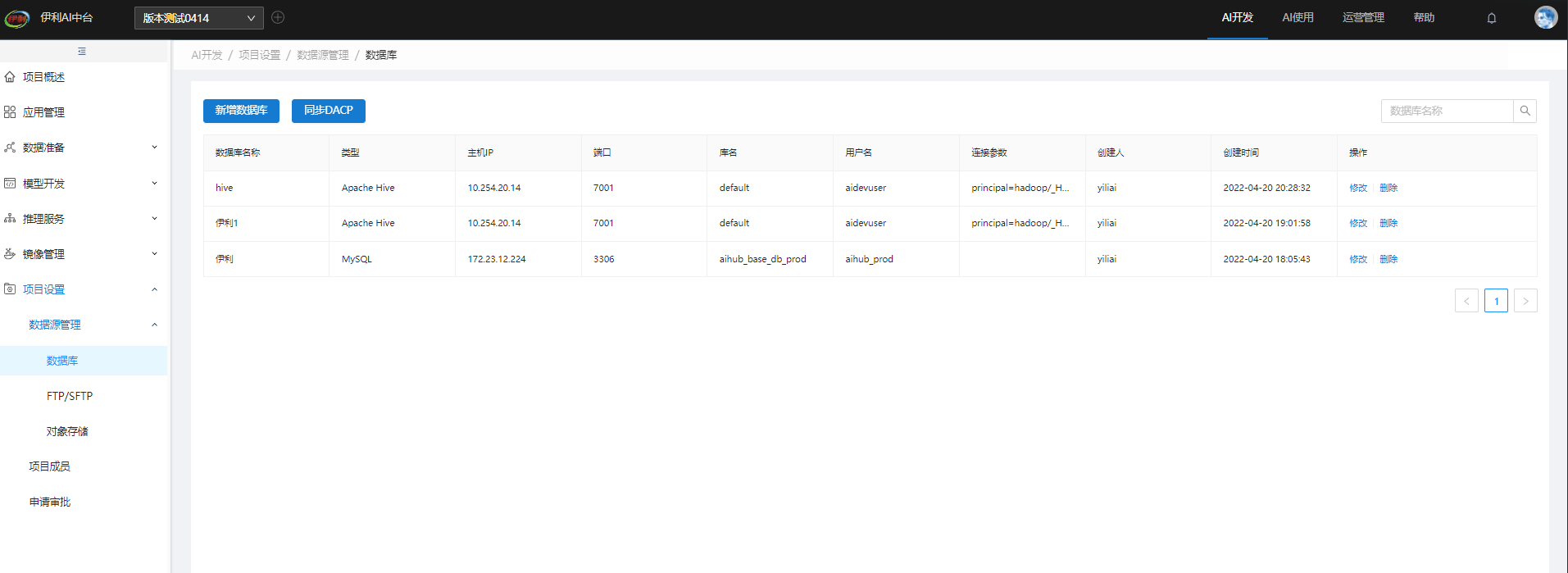
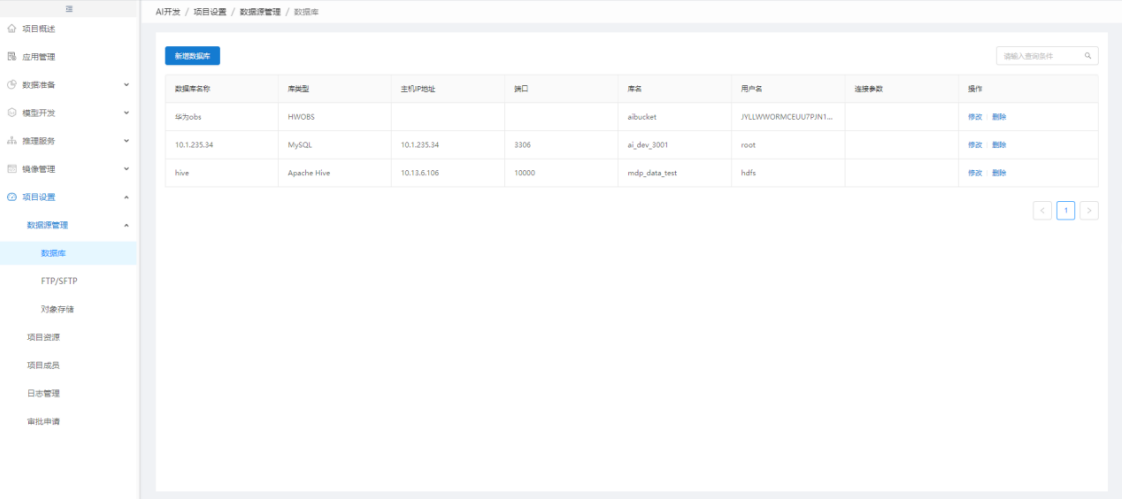
1.5.4. 数据源管理
系统里可看到的数据源,主要是针对结构化数据的开发,配置好相关的数据源信息,即可接入表数据。
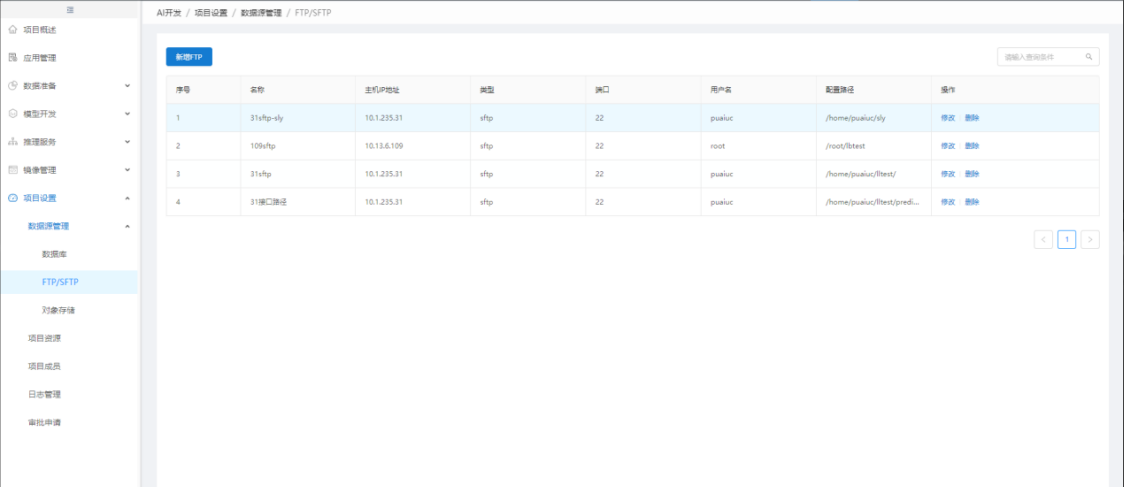
系统里可看到的FTP地址,主要用于数据远程放置(结构化和非结构化均可),配置好相关的FTP信息,即可接入表数据。
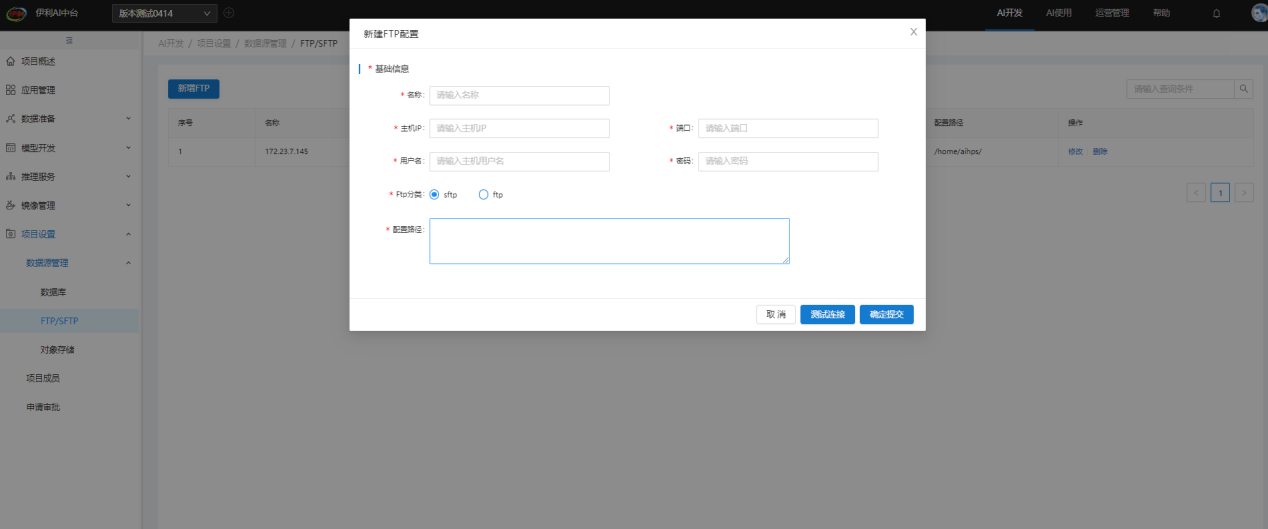
1.6. AI使用
用户使用系统API,需申请一个API用户,通过API用户申请一定时间的服务权限。

后续想使用一些服务,用于API调用,需要在首页上的“AI使用”进入API用户管理。
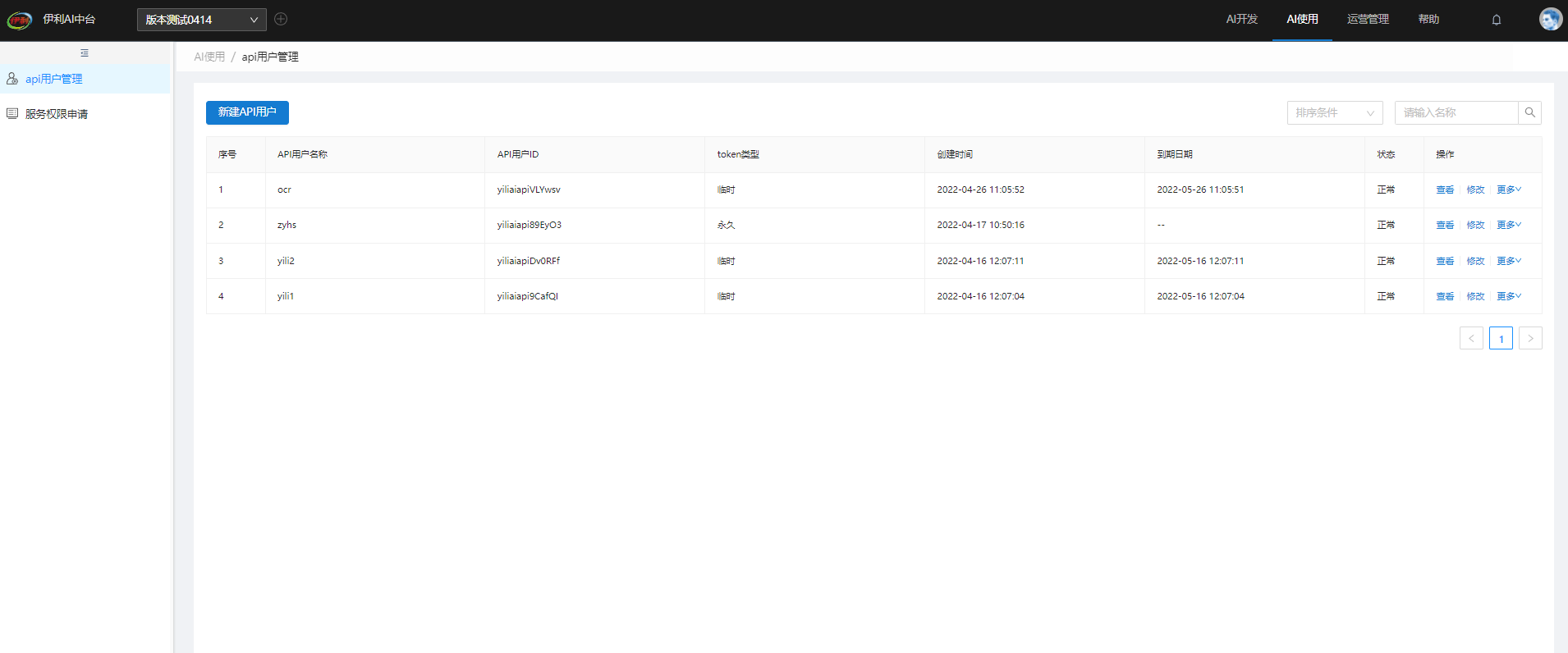
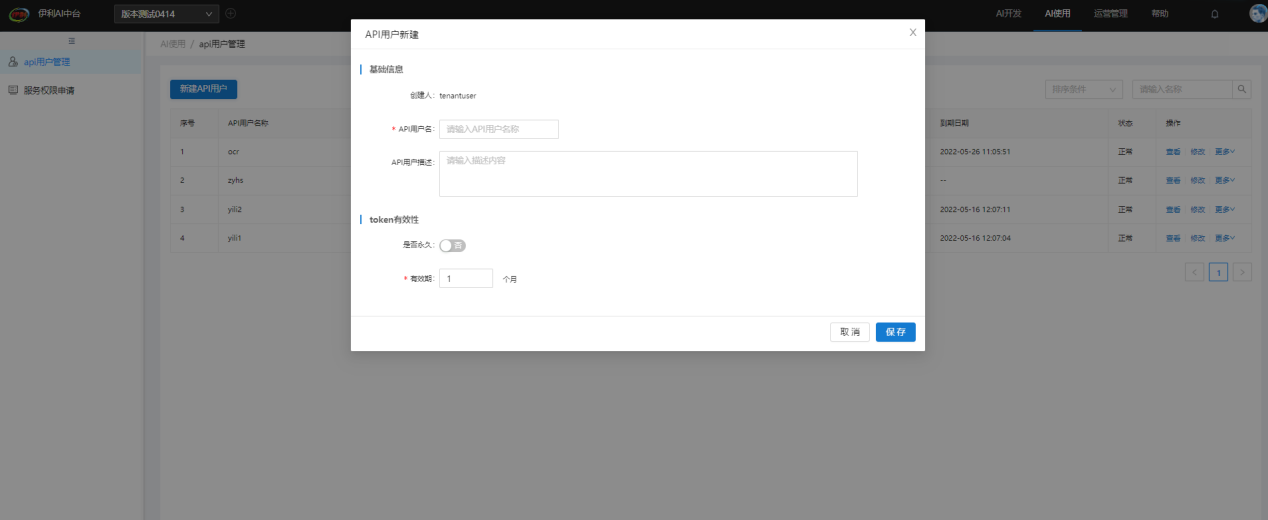
若没有想用的API用户,可以新建一个API用户。
申请后的API用户需指定想申请的服务,即在指定的API用户里申请服务权限。
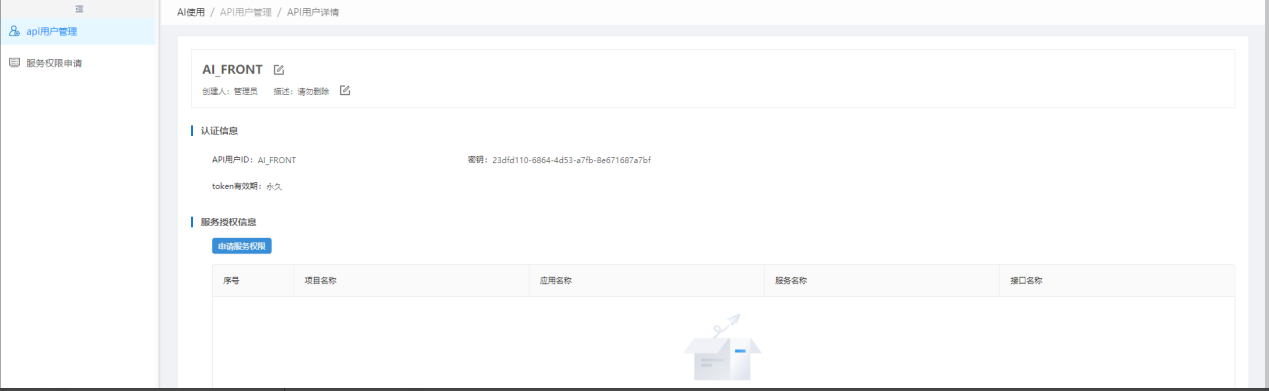

新增的申请可以在申请列表中查看。

1.7. 附录
1.7.1. 用户信息
登录系统的用户可以进行自身信息进行变更,包括修改密码,绑定Git,退出账号。


