
 zeke-chin
zeke-chin
23 changed files with 192 additions and 7 deletions
+ 0
- 0
TestAllOcr/config.py → HR-OCR/TestAllOcr/config.py
+ 0
- 0
TestAllOcr/image/bankcard.jpg → HR-OCR/TestAllOcr/image/bankcard.jpg
{kind=link}

+ 0
- 0
TestAllOcr/image/blfe.jpg → HR-OCR/TestAllOcr/image/blfe.jpg
{kind=link}

+ 0
- 0
TestAllOcr/image/cet.jpg → HR-OCR/TestAllOcr/image/cet.jpg
{kind=link}

+ 0
- 0
TestAllOcr/image/idcard.jpg → HR-OCR/TestAllOcr/image/idcard.jpg
{kind=link}

+ 0
- 0
TestAllOcr/image/regbook.jpg → HR-OCR/TestAllOcr/image/regbook.jpg
{kind=link}

+ 0
- 0
TestAllOcr/image/schoolcert.jpg → HR-OCR/TestAllOcr/image/schoolcert.jpg
{kind=link}

+ 6
- 7
TestAllOcr/test_interface.py → HR-OCR/TestAllOcr/test_interface.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 0
- 0
HR-OCR/config.py
+ 0
- 0
to_md/new.py → HR-OCR/to_md/new.py
+ 0
- 0
to_md/ocr_config.py → HR-OCR/to_md/ocr_config.py
+ 0
- 0
to_md/use.py → HR-OCR/to_md/use.py
+ 0
- 0
tools/convert_json.py → HR-OCR/tools/convert_json.py
+ 0
- 0
tools/suffix.py → HR-OCR/tools/suffix.py
BIN
YQ-OCR/img/03-植选PET 内包—植选豆乳以团之名形象定制包装周艺轩版.jpg
{kind=link}

BIN
YQ-OCR/img/03-植选PET 内包—植选豆乳以团之名形象定制包装周艺轩版.xlsx
BIN
YQ-OCR/img/巧克力味牛奶饮品.jpg
{kind=link}

BIN
YQ-OCR/img/巧克力味牛奶饮品.xlsx
BIN
YQ-OCR/img/餐饮纯牛奶 内包.jpg
{kind=link}
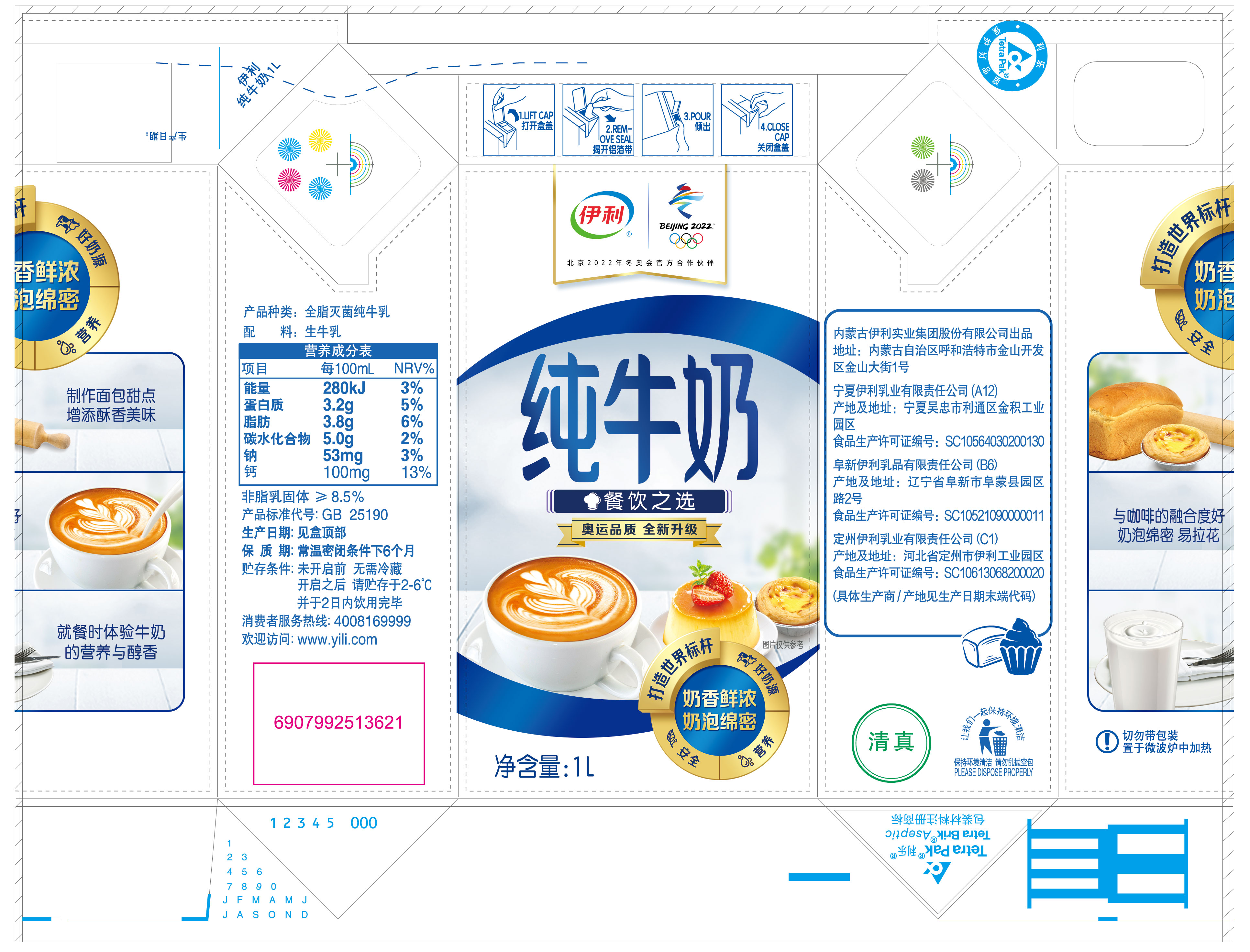
BIN
YQ-OCR/img/餐饮纯牛奶 内包.xlsx
+ 11
- 0
YQ-OCR/to_md/config.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 118
- 0
YQ-OCR/to_md/convert_MD.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 57
- 0
YQ-OCR/to_md/xlsx_convert_json.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||