
visualizing-output-in-the-kfp-ui.md 4.3 KB
Visualizing output from your notebooks or Python scripts in the Kubeflow Pipelines UI
Pipelines that you run on Kubeflow Pipelines can optionally produce output that is rendered in the Kubeflow Pipelines UI. For example, a model training script might expose quality metrics.
You can try the visualizations shown in this document using this pipeline in the Elyra examples repository.
Visualizing output using the Kubeflow Pipelines output viewer
The output viewer in the Kubeflow Pipelines UI can render output such as a confusion matrix, ROC curve, or markdown, that is displayed in the Kubeflow Pipelines UI.
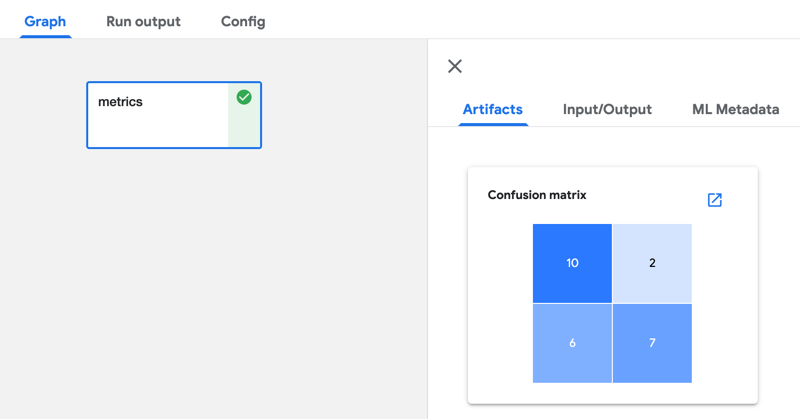
To produce this output add code to your notebook or Python script that creates a file named mlpipeline-ui-metadata.json in the current working directory. Refer to Visualize Results in the Pipelines UI in the Kubeflow Pipelines documentation to learn about supported visualizations and the format of the mlpipeline-ui-metadata.json file.
The following code snippet produces a confusion matrix that is rendered in the output viewer as shown above:
import json
import pandas as pd
matrix = [
['yummy', 'yummy', 10],
['yummy', 'not yummy', 2],
['not yummy', 'yummy', 6],
['not yummy', 'not yummy', 7]
]
df = pd.DataFrame(matrix,columns=['target','predicted','count'])
metadata = {
"outputs": [
{
"type": "confusion_matrix",
"format": "csv",
"schema": [
{
"name": "target",
"type": "CATEGORY"
},
{
"name": "predicted",
"type": "CATEGORY"
},
{
"name": "count",
"type": "NUMBER"
}
],
"source": df.to_csv(header=False, index=False),
"storage": "inline",
"labels": [
"yummy",
"not yummy"
]
}
]
}
with open('mlpipeline-ui-metadata.json', 'w') as f:
json.dump(metadata, f)
Note that the output is displayed only after notebook or Python script processing has completed.
Visualizing scalar performance metrics in the Kubeflow Pipelines UI
If your notebooks or Python scripts calculate scalar performance metrics they can be displayed as part of the run output in the Kubeflow Pipelines UI.
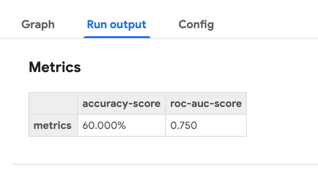
To expose the metrics, add code to the notebook or Python script that stores them in a file named mlpipeline-metrics.json in the current working directory. Refer to Pipeline Metrics in the Kubeflow Pipelines documentation to learn more about the content of this file.
The following code snippet produces this file and records two metrics:
import json
# ...
# calculate Accuracy classification score
accuracy_score = 0.6
# calculate Area Under the Receiver Operating Characteristic Curve (ROC AUC)
roc_auc_score = 0.75
metrics = {
'metrics': [
{
'name': 'accuracy-score',
'numberValue': accuracy_score,
'format': 'PERCENTAGE'
},
{
'name': 'roc-auc-score',
'numberValue': roc_auc_score,
'format': 'RAW'
}
]
}
with open('mlpipeline-metrics.json', 'w') as f:
json.dump(metrics, f)
Note that the metrics are displayed after notebook or Python script processing has completed.